深度强化学习驱动的全球股票市场动态投资组合配置研究
引言:从静态优化到序贯决策
投资组合管理的核心问题,本质上是一个在不确定环境中做序贯决策(sequential decision-making)的问题。从 Markowitz 1952 年提出的均值-方差优化(MVO)开始,金融工程领域沉淀了大量的组合构建框架。然而,无论是 MVO,还是后来的 Black-Litterman、风险平价、或者基于机器学习预测收益的”预测+优化”两阶段方法,本质上都有一个共同的特征:把”预测”和”决策”拆分开来。先估计期望收益与协方差矩阵,再求解一个静态的优化问题。
这种范式存在两个长期被诟病的问题。其一,估计误差敏感性。即便是经典文献也表明(如 DeMiguel et al. 2009),简单的等权重 策略在样本外往往可以击败精心优化过的 MVO 组合,原因正是参数估计噪声被优化器放大。其二,缺乏对动态环境的适应性。市场状态在结构性破裂、危机、不同宏观周期中切换,单一的静态参数估计很难跨制度(regime)稳健。
强化学习(Reinforcement Learning, RL)提供了另一种思路:把预测和决策融合到同一个目标函数下。智能体(agent)在与市场环境的交互中,直接学习一个从市场状态到投资组合权重的映射策略,目标是最大化长期累积的风险调整后收益。它不显式预测未来收益,而是把”预测”内化为价值函数(value function)与策略(policy)的隐式表达。
本文要系统讨论的是一个基于 Soft Actor-Critic(SAC)的深度强化学习框架,覆盖 Nasdaq-100、Nikkei 225、Euro Stoxx 50 三大全球股票指数,用walk-forward方式回测约 17 年的样本外表现,并比较了五种结构不同的 RL 配置以及四个经典基准。
一、问题的 MDP 表述
强化学习的标准形式是马尔可夫决策过程(MDP),由五元组 描述。在投资组合的语境下:
-
:状态空间,对应于当前可观测的市场信息(价格、波动、动量、技术指标、宏观特征等); -
:动作空间,对应于资产权重向量 ; -
:环境转移,即给定当前状态与动作后,下一时点市场状态的条件分布; -
:奖励函数,反映组合在 期的表现; -
:折现因子,控制对未来奖励的重视程度。
策略 是从状态到动作的(条件)分布。智能体从 时刻起的累积回报为:
学习目标是找到使期望累积回报最大化的最优策略 。两个核心价值函数分别为:
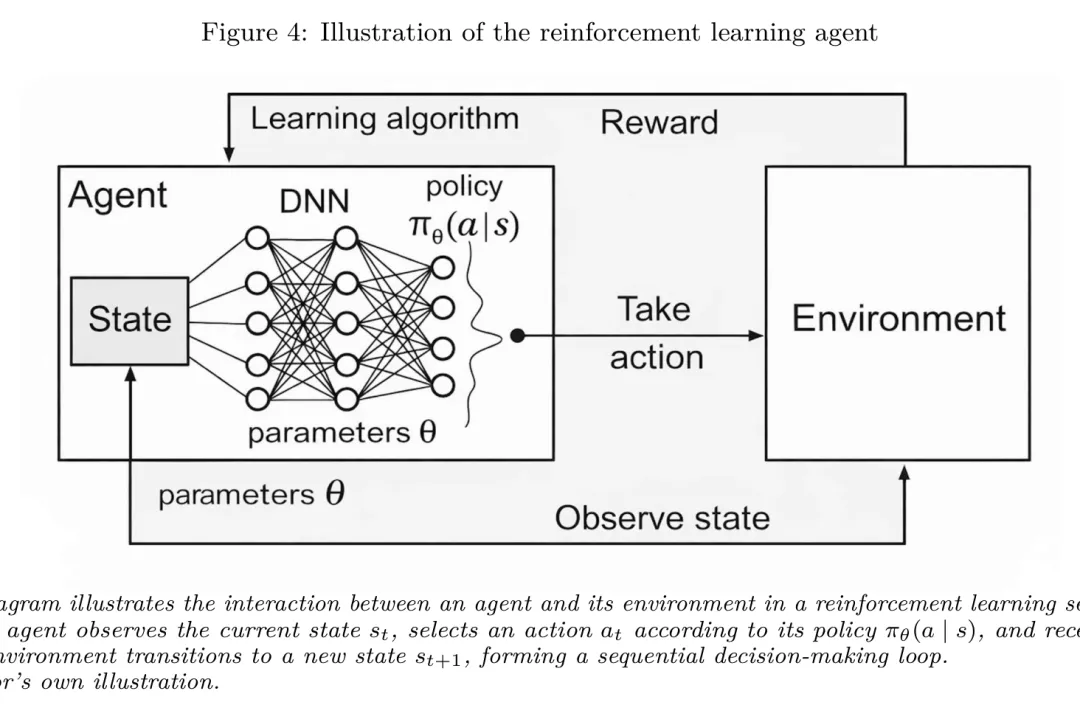
图:强化学习智能体与环境的交互闭环:智能体观测状态 ,按策略 选取动作 ,环境反馈奖励并转移到新状态 。
需要强调的是,金融市场严格意义上并不满足马尔可夫性。当前价格并不”概括”全部历史信息——波动聚集、长记忆效应、宏观周期都意味着状态需要更丰富的表达。实际操作中,研究者通常通过把最近的若干历史观测窗口纳入状态,来近似满足马尔可夫性。这也是 LSTM、Transformer 这类时序编码器在 RL 框架中被广泛使用的原因。
二、数据与可交易宇宙的构建
研究覆盖三个具有代表性的指数:美国的 Nasdaq-100、日本的 Nikkei 225、欧洲的 Euro Stoxx 50,样本期为 2003-01-02 至 2026-03-13,日频。
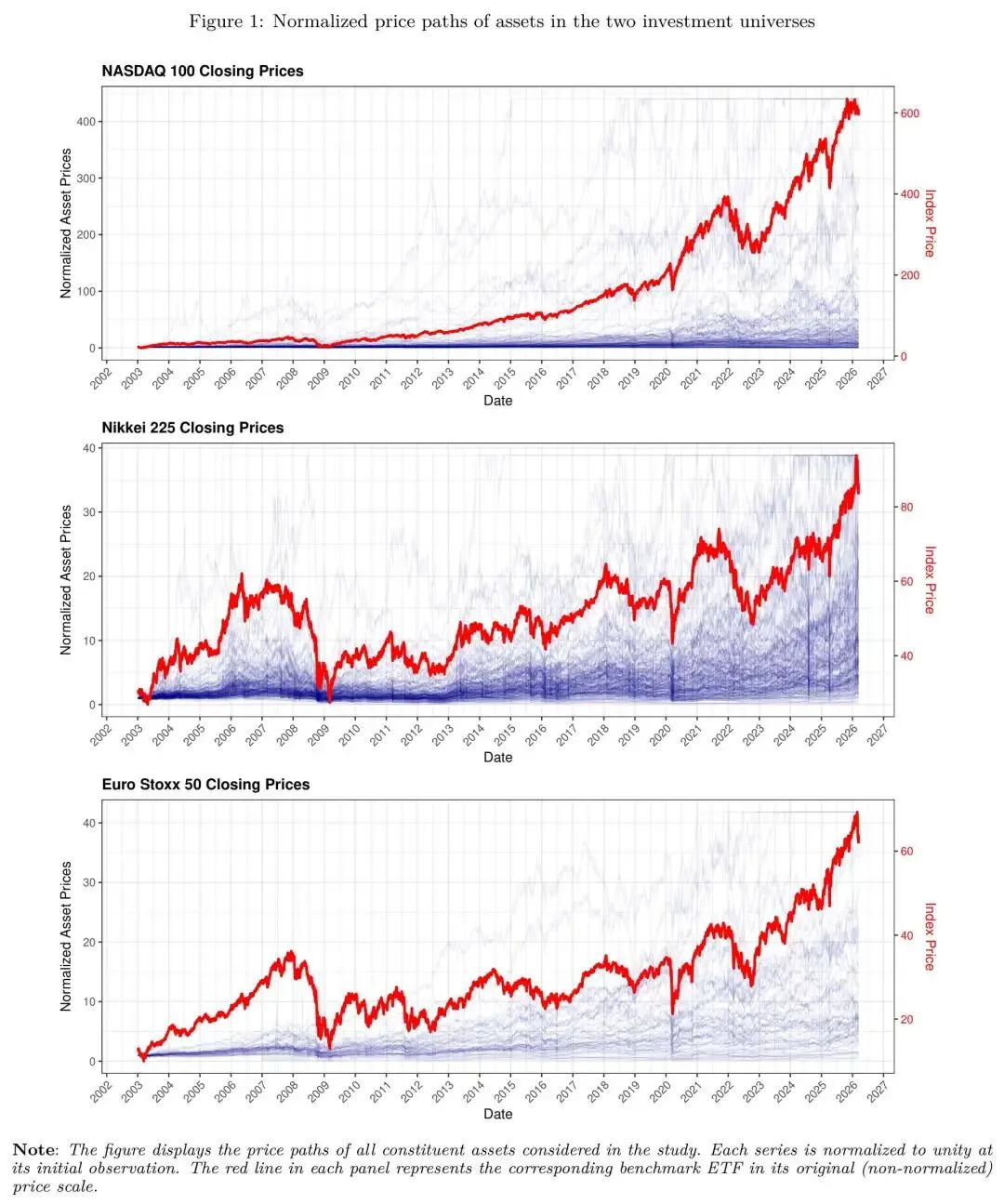
图:三个指数成分股的标准化价格路径(红线为对应的可交易 ETF 基准),可以直观看出各市场的历史走势特征差异。
这里有一个非常重要的细节:幸存者偏差(survivorship bias)的处理。如果直接拿”当前在册的成分股”回到 2003 年回测,结果会被严重高估——退市、被剔除的股票被系统性地忽略掉了。研究者通过 Bloomberg 终端获取了完整的指数成分历史变更(加入与剔除事件),并构建了一个可交易掩码(tradability mask):
也就是说,资产 在 时刻”可交易”,当且仅当它既是当时指数成分,又有有效价格数据。这一处理对回测结果的真实性至关重要。
基准 ETF 方面,QQQ 用于 Nasdaq-100,FEZ 用于 Euro Stoxx 50,EWJ 用于 Nikkei 225。这些都是流动性充足、可直接交易的工具,保证了 Buy & Hold 基准的现实可执行性。
三、状态表征:多维特征的工程
状态向量是 RL 智能体的”眼睛”。设计得过于稀疏会损失信息,过于稠密又会让网络在样本量有限的金融数据上过拟合。本框架的状态分为五类特征。
第一类是动量特征。对每个资产 在 时刻,计算多窗口的对数收益率:
第二类是波动率特征,使用滚动标准差:
第三类是技术指标,包括 RSI、MACD 直方图、Bollinger %B、距 20 日高点的距离、相对 20 日均线的偏离度。这些特征用于捕捉非线性的价格动力学与均值回归信号。
第四类是市场相对特征,包括对市场代理(QQQ/FEZ/EWJ)的 60 日滚动 beta,以及 20 日的绝对表现。
第五类是全局宏观特征:VIX 水平及其 5 日变化、横截面平均收益及其滚动波动、市场宽度(即正中期收益资产的比例)、市场代理的标准化收益。
此外,为了控制维度灾难,框架使用了一个非常实用的预筛选机制——top-k 动量选股。在每个时点 ,只保留 120 日动量最高的 个资产()进入候选集:
这一选股环节是外生于 RL 智能体的,目的有二:一是把动作空间从近百个收窄到一个可控的数量,二是把”明显的动量过滤”和”权重分配”两个子问题解耦。后续做基准比较时,这一点至关重要——我们需要分清楚到底是动量预筛选在创造收益,还是 RL 的权重分配策略在创造价值。
四、动作空间与 Dirichlet 策略
智能体的动作就是一个权重向量:
其中 是现金权重。权重必须满足预算约束:
为了保证策略网络的输出天然满足”非负且求和为 1″的单纯形约束,作者采用 Dirichlet 分布参数化策略:神经网络输出 Dirichlet 分布的浓度参数 ,再从该分布采样得到权重。这是连续动作空间下的一种自然选择,既保留了随机性以利探索,又通过分布约束保证了组合的合法性。
更进一步,本框架对比了两种策略结构。第一种是扁平 Dirichlet,直接用一个 Dirichlet 分布对所有股票 + 现金做权重分配。第二种是层级化(hierarchical)策略:先用一个分布决定”股票 vs 现金”的总暴露,再用另一个 Dirichlet 在股票内部做横截面分配。其结构上类似:
层级结构的好处是把”宏观仓位决策”与”个股选择决策”解耦,这与人类基金经理的实际决策流程更接近,也更利于网络分别学习两类不同时间尺度的信号。
五、奖励函数:把现实摩擦写进目标
奖励函数是 RL 框架中最具”金融工程意味”的部分。如果直接用原始收益作为奖励,智能体会倾向于学到换手极高、集中度极高的极端策略——这在现实交易中根本无法实现。因此奖励函数需要嵌入三类要素:组合收益、交易摩擦、分散化约束。
记 为扣除交易成本后的组合收益。为稳定训练梯度,做对数变换:
换手率定义为前后两期权重向量的 距离,反映组合再平衡的强度:
集中度用 Herfindahl 指数衡量:
理论最小值 对应等权重组合。最终的奖励函数(绝对收益形式)为:
另一种形式是基准相对(benchmark-relative)奖励:
奖励项的缩放系数(1000、100)是为了让三项贡献在数值上保持相近量级,避免某一项淹没梯度信号。这是 RL 训练中常见的实践技巧。
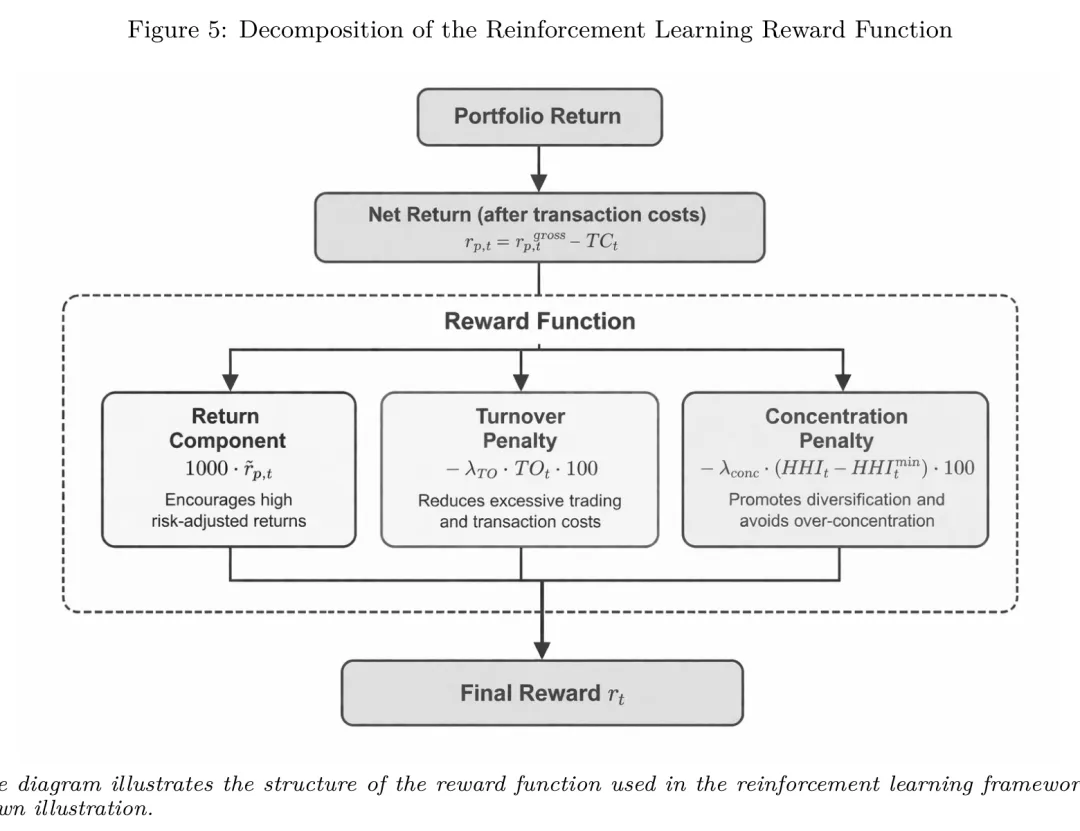
图:奖励函数的三段式分解结构:组合净收益项促使追求高收益,换手率惩罚项抑制过度交易,集中度惩罚项推动分散化。
值得一提的是,交易成本设定为每单位换手 2 个基点(bps),这一水平与 Interactive Brokers 在分层定价下机构与高频交易者实际可以获得的费率相符,因此具有一定的真实性。
六、模型架构:SAC + 时序编码器 + Dirichlet 策略
整个 RL 算法基于 Soft Actor-Critic(SAC)。SAC 是一个 off-policy 的演员-评论员算法,相比 PPO、DDPG 等方法的核心改进在于最大熵正则化:策略不仅要最大化期望回报,还要最大化策略的熵:
熵正则化项 鼓励探索,对金融这种信号噪声比极低的场景尤其有用。本文将熵系数 固定为 0.2,而不是常见的自适应调节——作者发现自适应 在walk-forward的窗口切换中会引入训练不稳定性,固定值反而带来更可复现的结果。
SAC 网络结构包括:一个策略网络(actor,输出 Dirichlet 浓度参数)和两个独立的 Q 函数网络(twin critics,缓解 Q 值高估偏差)。目标网络通过软更新机制平滑参数:
其中 。
时序编码器有两种选择。基线是 LSTM:对每个资产的历史窗口(60 天)单独编码,再通过横截面注意力机制汇总。另一种是 Transformer 编码器,用自注意力替代 RNN 的递归结构。在金融时序里,二者各有优势:LSTM 顺序处理对局部时序依赖建模更直接,Transformer 的并行注意力则更擅长捕捉长程关联。但参数量与训练时间也相差悬殊——单折训练 LSTM 需约 14 小时,Transformer 需约 23 小时。
五种模型配置的对比如下表所示,每行对应一个完整的”编码器 + 策略 + 奖励 + 约束”组合:
|
|
|
|
|
|
|
|---|---|---|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
七、walk-forward优化与自适应再训练
金融时序的非平稳性意味着,传统的 k-fold 交叉验证根本不适用——它会泄露未来信息。研究者采用了非锚定式的walk-forward(walk-forward)框架:每一折包含 5 年训练、1 年验证、1 年测试,窗口随时间向前滚动,从 2003 年开始一路推到 2026 年,总共 16 个测试折。
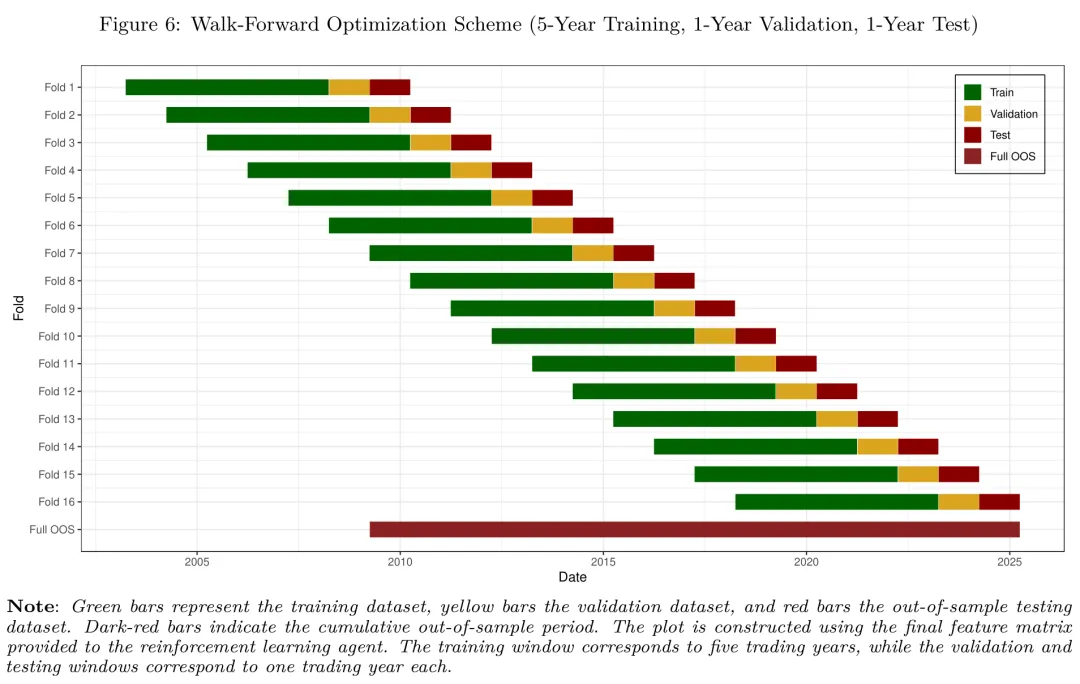
图:walk-forward回测的窗口滚动结构。绿色为训练集,黄色为验证集,红色为测试集,暗红色累积条带表示完整的样本外评估期。
这种设置最大限度地模拟了真实部署环境——任何时点的决策都只能用过去的数据训练模型。但每折都从头训练既昂贵又可能引入不必要的不稳定性,因此作者设计了一个自适应再训练机制:只有当模型的近期验证表现下滑时才重新训练。具体地,记第 折验证集上的夏普比为 ,定义阈值:
其中 。若满足以下任一条件,则触发再训练:
这一机制既节约了算力,也避免在模型仍然适用时强行重训带来的扰动。
八、基准策略:合理的对照组
公允评价 RL 策略,必须有覆盖不同范式的基准组。本文使用了四个:
第一是 Buy & Hold,对应基准 ETF 的被动持有。这是最严苛的对照——它没有任何主动管理、零交易成本。学界普遍认为,能在风险调整后稳定打败被动持有,是任何主动策略的最低门槛。
第二是 Momentum Top-20,按 120 日动量每月选股 20 只并等权重持有。这一基准的目的是隔离”动量预筛选”的贡献——如果 RL 策略和这个动量基准表现相近,那说明真正在创造收益的是动量预筛选,而非 RL 学到的权重分配策略。
第三是 Equal-Weight Monthly,对 RL 用的同一个 top-k 候选池等权配置、月度再平衡。这是 DeMiguel et al. (2009) 推崇的”朴素分散”基准。
第四是 Markowitz 最小方差组合,在 5 年滚动训练窗口上估计协方差矩阵,求解长期、全仓、有上限的最小方差问题,月度再平衡。这是经典优化方法的代表。
九、绩效指标:超越夏普比的多维评估
研究采用了一个比较全面的指标体系。除了常见的年化复合收益 ARC 和年化波动率 ASD,最大回撤 MD、最大损失持续期 MLD(以年计),还有:
夏普比(SR):
修正信息比 IR2,这是本文的主要评估指标:
IR2 的设计意图是:在同时奖励高收益、低波动的基础上,再用最大回撤进行”惩罚”。一个频繁深度回撤的策略,即使夏普比看起来还行,IR2 也会被压低。这对于实盘投资者而言更具参考价值。
扩展信息比 IR3 进一步把回撤持续时间也纳入:
十、实证结果:三个市场的差异化表现
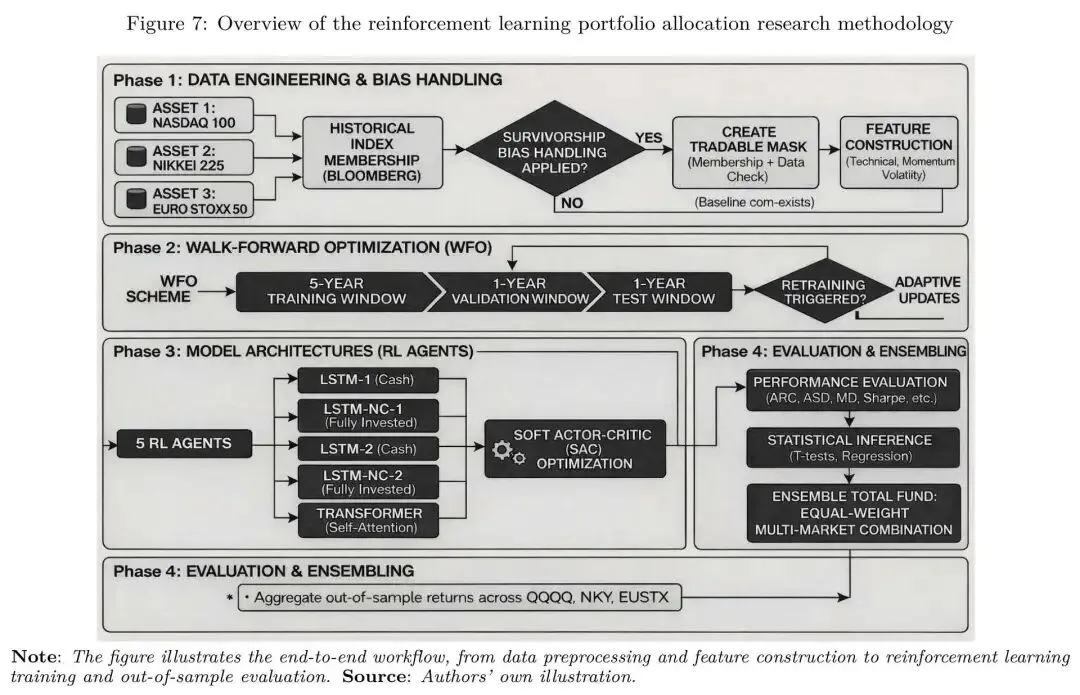
图:从数据工程、walk-forward、模型架构到评估与集成的完整研究流程框架。
Nasdaq-100:被动策略难以战胜
在 Nasdaq-100 这个 2009 年以来持续单边上涨的市场里,被动策略表现极为亮眼。Buy & Hold 的 ARC 达 19.27%,IR2 为 0.52;Equal-Weight Monthly 也表现强劲(IR2 = 0.49)。在 RL 策略中,表现最好的是 LSTM_2(层级化、含现金),IR2 = 0.46,年化波动率(18.67%)和最大回撤(28.77%)都明显低于其他 RL 配置,体现了层级化策略和现金缓冲的下行保护能力。
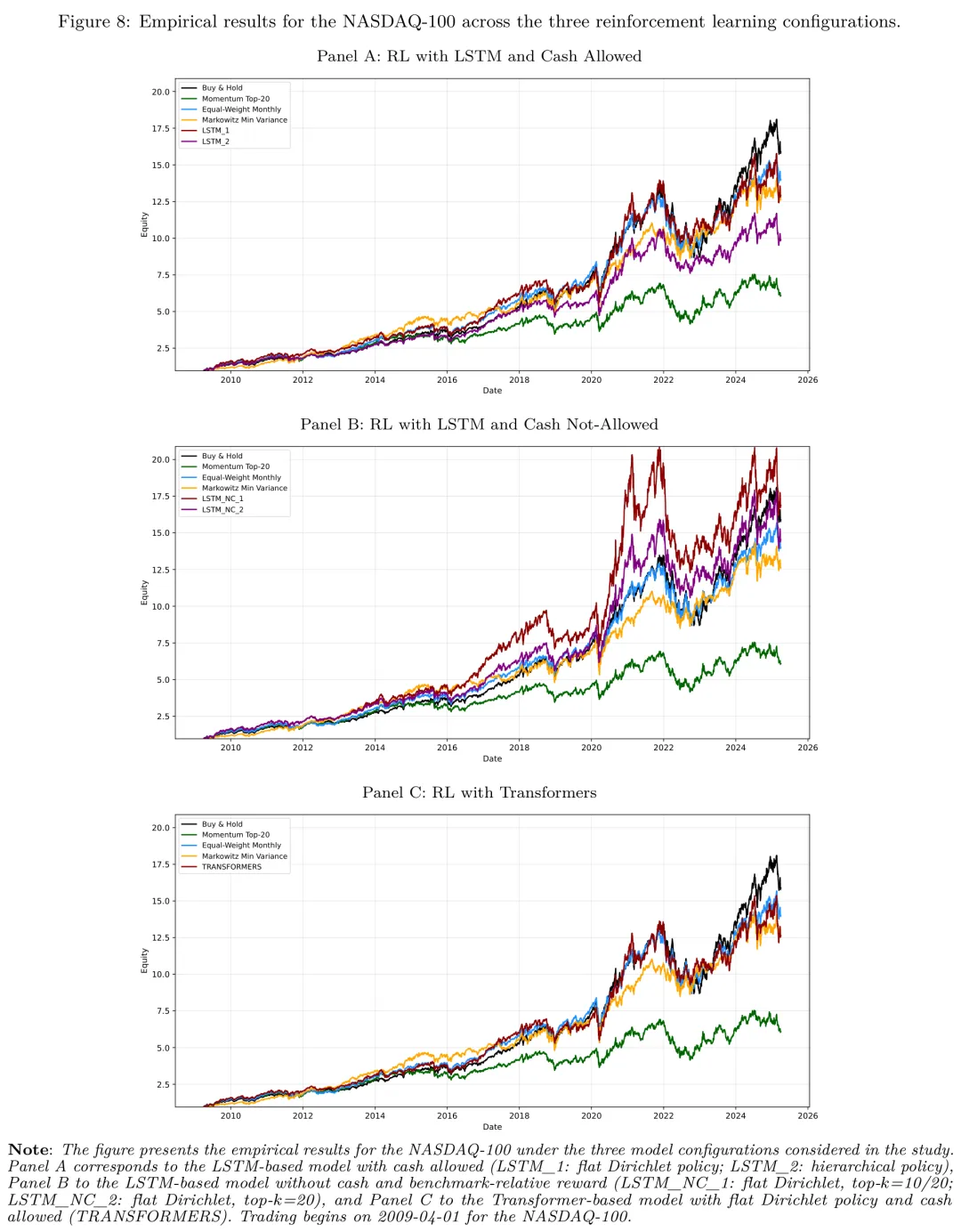
图: Nasdaq-100 三种 RL 配置(含现金 LSTM、不含现金 LSTM、Transformer)的样本外权益曲线,以及与四个基准的对比。
值得注意的是 LSTM_NC_1(不含现金的 RL 配置)实现了 1666.4% 的最高累计收益,但年化波动率高达 24.20%,最大回撤 41.23%,IR2 只有 0.39。这清楚地说明了一个事实:满仓投资能放大趋势,但代价是回撤——风险调整后并不优。
总体看,Nasdaq-100 这种强趋势市场,是被动策略的”主场”,RL 难以在其中创造系统性 alpha。
Nikkei 225:分散化才是王道
日本市场的情况则完全不同。Buy & Hold(EWJ)在整个样本期里表现极差,ARC 仅 4.57%,最大损失持续期 MLD 高达 11.35 年——也就是说,从 2007 年附近的高点出发,要等十一年才能回本。这反映了日本市场长期的结构性问题。
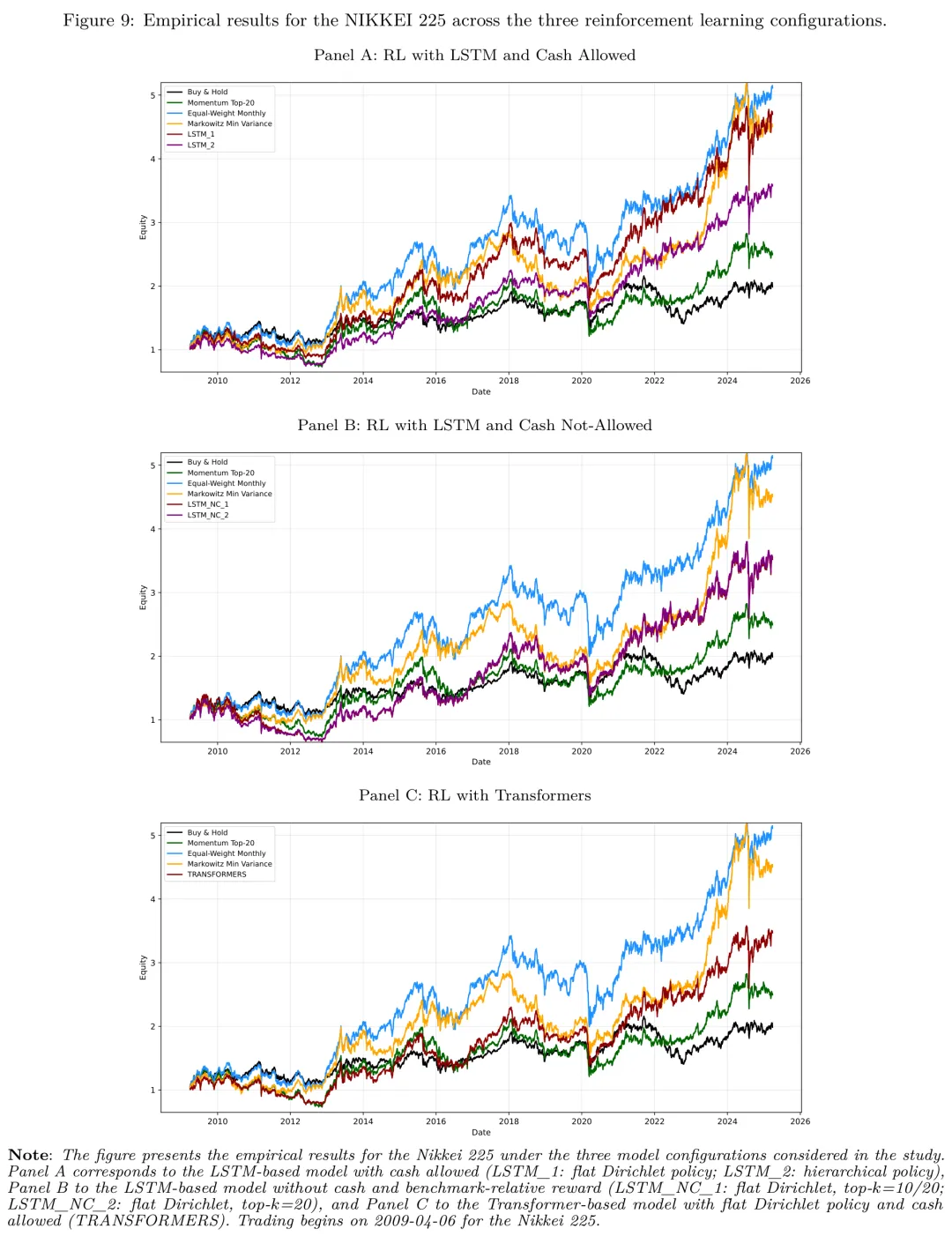
图: Nikkei 225 三种 RL 配置的样本外权益曲线。可以明显观察到 Buy & Hold 长期跑输 Equal-Weight Monthly 与 Markowitz 最小方差组合。
在这种市场中,Markowitz 最小方差(ARC 13.17%)和 Equal-Weight Monthly(ARC 12.40%)反而表现最好。RL 中表现最好的 LSTM_1 实现 ARC 11.22%、IR2 0.15,虽然好于 Buy & Hold,但仍然没有超过这两个经典分散化基准。
Euro Stoxx 50:RL 的相对优势区
欧洲市场是 RL 表现最好的环境。所有 RL 配置在 IR2 上都超过了 Buy & Hold。其中 LSTM_2(层级化)以 IR2 = 0.146、波动率 15.97%、最大回撤 29.94% 的组合达到全场 RL 最佳水平,甚至略高于 Equal-Weight Monthly(IR2 = 0.129)。
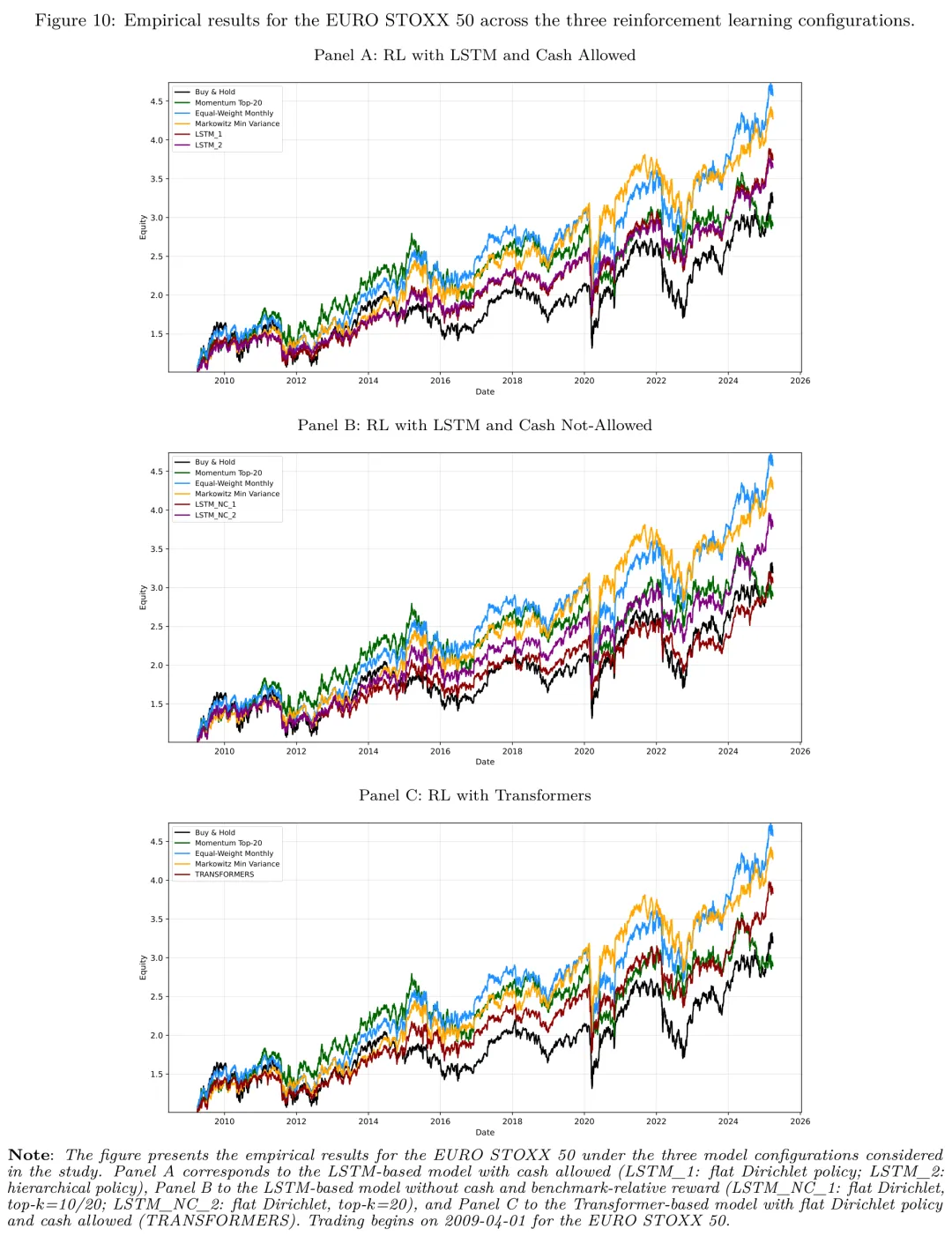
图: Euro Stoxx 50 三种 RL 配置的样本外权益曲线。
这一现象有合理的金融直觉:欧洲市场在样本期内更接近震荡而非强趋势,结构性不确定性更高(欧债危机、英国脱欧、能源危机等),主动型动态资产配置更容易找到价值。
十一、统计显著性:被严格检验后才有意义
绩效指标的差异,未必等于统计意义上的真正优势。金融收益序列存在自相关、异方差、厚尾——直接做配对 t 检验会严重低估标准误。研究者采用了两套互补的稳健推断方法。
第一是 Newey-West HAC 估计量,对均值收益差做异方差和自相关稳健的标准误修正。
第二是平稳块自助法(stationary block bootstrap),构造夏普比和 IR2 差异的经验分布。
零假设是 ,备择假设是 。
结果让人冷静。在所有三个市场,在所有 RL 配置上,对均值收益差、夏普比差、IR2 差的检验都未在 10% 显著性水平上拒绝原假设。也就是说,那些看起来漂亮的指标差距,可能更多是随机变异而非系统性 alpha。
研究者进一步做了截距回归:
在 HAC 标准误下检验 。这是经典的”超额收益”检验。结果是:Nasdaq-100 和 Nikkei 225 上没有 RL 配置实现显著的 ,但在 Euro Stoxx 50 上,LSTM_1、LSTM_2 和 Transformer 都实现了在 10% 显著性水平下的正 (LSTM_2 的 t 统计量达 2.26,p 值 0.012)。
这一发现具有重要含义:RL 在”易于做主动管理”的市场上确实可以捕捉到一些异常收益,但不能跨市场普适化。
十二、宏观体制分析:什么时候 RL 才有用?
研究者把样本期切成三个宏观体制:金融危机后复苏(2009-2013)、长期牛市(2014-2019)、新冠+加息周期(2020-2026),观察各策略在不同体制下的表现。
在 Nasdaq-100 上,RL 仅在 2009-2013 的复苏期能超过 Buy & Hold;进入 2014 年以后的科技股大牛市,被动策略全面占优。这印证了一个朴素的逻辑:在强趋势市场里,任何”主动择时”都是负 alpha 的,因为最优策略就是不动。
在 Nikkei 225 上,2014-2019 期间 LSTM_2 跑出全场最佳(IR2 = 0.265),明显优于所有基准。这个时期日本市场震荡较多,RL 的动态择时和分散化产生了实质性价值。
在 Euro Stoxx 50 上,RL 策略在三个体制中都稳定优于 Buy & Hold(虽然不一定优于 Markowitz)。尤其值得注意的是 2020-2026 期间,Momentum Top-20 几乎崩盘(IR2 接近 0),而 RL 的 IR2 仍维持在 0.09-0.10 区间——这说明 RL 学到的不仅仅是简单动量,而是某种适应性更强的信号组合。
总结性的规律是:RL 在不确定性高、趋势持续性弱的环境中创造更多价值;在强趋势的市场里,主动管理本身就是劣势。
十三、集成视角:跨市场组合的价值
如果把三个市场的 RL 信号通过等权方式集成成一个”总基金”组合,结果会怎样?
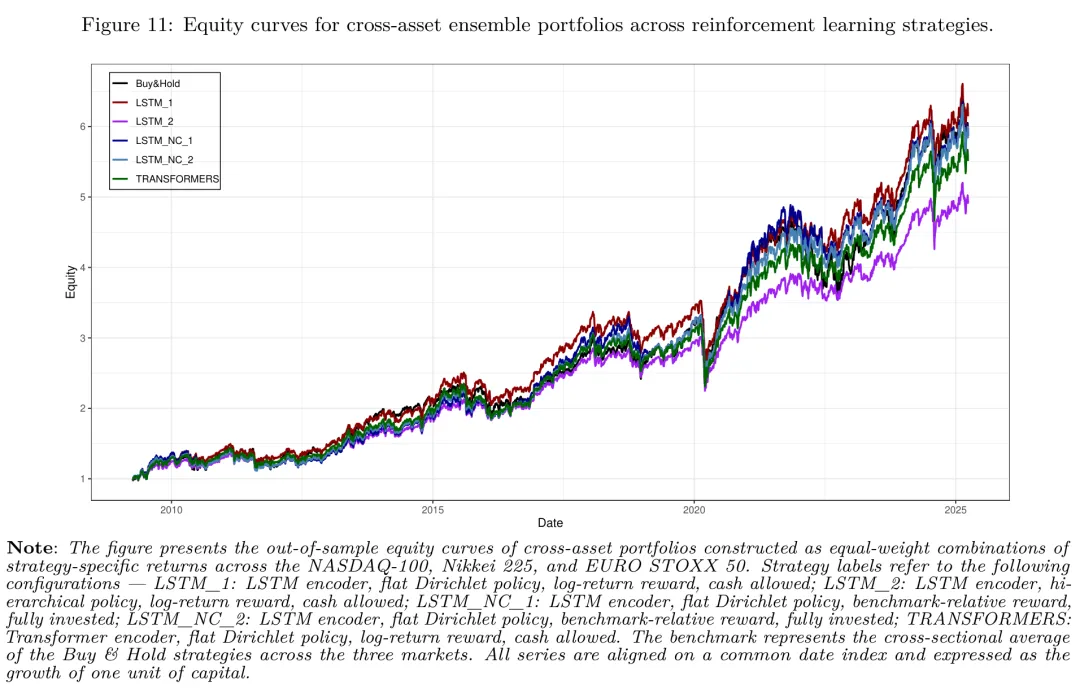
图:跨市场集成组合的样本外权益曲线,五种 RL 配置都被纳入比较。
集成结果是相当亮眼的。LSTM_1 集成组合实现 ARC 13.03%、波动率 14.72%、IR2 0.41,明显高于跨市场基准(IR2 0.34)。LSTM_2 集成组合的波动率(12.75%)和最大回撤(25.46%)是全场最低。
|
|
|
|
|
|
|---|---|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
更重要的是,集成情境下的回归检验里,LSTM_1 和 LSTM_2 集成组合的 在 10% 显著性水平上为正(p 值分别为 0.0496 和 0.0481)。这是地理分散化的真实价值——不同市场的 RL 信号去相关,组合层面降低了系统性风险,把单一市场上不显著的 alpha 在集成后放大到统计显著的水平。
十四、对量化研究的几点思考
把整个研究串起来,可以得出几个对实际量化研究有价值的观察。
第一,奖励工程比算法选择更重要。SAC 是个稳定的算法,但真正决定了策略行为模式的,是奖励函数里换手率惩罚、集中度惩罚的相对权重,是允许现金还是强制满仓,是绝对收益还是基准相对。在金融 RL 里,”模型设计”很大程度上等于”经济约束的数学化表达”。
第二,层级化策略结构有真实增量价值。LSTM_2 跨三个市场都比扁平 LSTM_1 拥有更低的波动和回撤。把”宏观仓位决策”与”个股选择决策”分离,让网络在两个不同时间尺度的子问题上分别学习,是一个值得推广的设计思路。
第三,含现金 vs 满仓的权衡,背后是收益与回撤的取舍。满仓配置追逐 beta,含现金配置追求 alpha。如果你的评估指标重视回撤控制(如 IR2、Calmar、Sortino),那含现金几乎总是更优;如果只看绝对累计收益,满仓有时候更亮眼,但稳健性差。
第四,Transformer 不是万能药。在这个任务里,Transformer 没能击败 LSTM 的风险调整后表现,而训练时间是 LSTM 的 1.6 倍以上。这与近期一些其他金融时序文献的发现一致——Transformer 强大的归纳偏置在数据量充足、长程依赖明显的场景下才能体现。日级别股票收益序列既不缺数据、也不太需要超长程依赖。
第五,跨市场集成是真实的”免费午餐”。等权集成三个去相关的市场信号,把单市场上不显著的 alpha 在投资组合层面放大到统计显著。这是一种典型的去噪 + 利用横截面信息的机制。从实操角度,构建全球多市场的 RL 配置系统,比深耕单一市场更有效率。
第六,要敬畏统计显著性。从指标层面看 LSTM_NC_1 在 Nasdaq-100 创造了 1666% 的累计收益,但在 HAC 检验下完全不显著。如果只看 P&L 不做严格的统计检验,很容易把噪声当成 alpha。
十五、局限与展望
需要诚实地指出研究的局限性。
其一,五种配置之间不是严格的 ceteris paribus 消融。比如 LSTM_NC 同时变了奖励(基准相对)和约束(满仓),无法把性能差异精确归因到某一个维度。后续工作可以做严格的逐维变量消融。
其二,交易成本固定为 2 bps,没有压力测试更高的成本水平。对换手率高的 RL 策略而言,5 bps 或 10 bps 的成本可能就让 alpha 消失。
其三,walk-forward参数(5 年训练 / 1 年验证 / 1 年测试)本身没有做敏感性分析,存在”元过拟合”的风险——也就是说,最终展示的好结果可能部分来自于参数选择本身。
其四,集成是等权固定的,没有学习一个自适应的跨市场动态权重。
未来值得探索的方向有几个:把状态空间扩展到日内高频或加密资产;把宏观特征(利差、信用利差、PMI)和情感信号(LLM 嵌入的新闻文本)纳入状态;把固定等权集成升级为学习型的元配置层;以及把这类框架嫁接到衍生品对冲、最优执行等更复杂的金融决策场景。
结语
强化学习并非金融市场的”圣杯”。它在某些市场(如 Euro Stoxx 50)和某些体制(不确定性高、趋势弱)下能创造价值,在另一些市场(强趋势的 Nasdaq-100)里则难以击败被动策略。但它提供的范式价值是真实的——把预测、决策、风险管理三个传统上独立优化的环节,融合到一个端到端的目标函数中,让我们以一种更灵活、更适应非平稳环境的方式去构建投资组合策略。
对量化研究而言,关键在于:不要把 RL 当成万能药,也不要因为它在某个市场没出 alpha 就否定整个范式。理解它适用的边界、设计合适的奖励函数与策略结构、严格地做统计推断与跨市场稳健性检验——这才是把这一工具真正变成 alpha 来源的方式。
参考文献
Kashif, K., & Ślepaczuk, R. (2026). Deep Reinforcement Learning Framework for Diversified Portfolio Management Across Global Equity Markets. arXiv preprint arXiv:2605.17307. Quantitative Finance Research Group, Faculty of Economic Sciences, University of Warsaw.