柴油站营销选择模型构建及实证研究

柴油站营销选择模型构建及实证研究
张蕾1,丁少恒1,张嘉琪2
(1.中国石油规划总院;2.中国人民大学)
摘 要:在激烈的成品油市场竞争中,柴油加油站营销方案的科学制定与效果评估至关重要。本文以国内某大型石油公司L省柴油加油站为研究对象,整合2020—2021年运营数据与外部环境数据,融合传统统计方法、机器学习及深度学习技术,构建营销选择模型与个体效应(ITE)评估框架。研究采用了聚类划分站点类型,结合生成对抗网络(GAN)处理选择偏倚、极端梯度提升(XGB)构建推断模型,并通过模型平均降低结果波动性,最终实现不同营销强度下站点ITE的精准量化。基于评估结果,建立站点营销优先级排序与成本约束下的策略模拟方法,实证显示该方案可使销量提升近25%。研究为柴油加油站营销资源优化配置、过往方案评价及未来策略制定提供了量化依据和实践参考。
关键词:柴油加油站;加油站网络优化;营销方案制定;生成对抗网络;机器学习营销决策;因果推断
0 引言
在市场竞争中,销售企业通常希望通过营销手段实现在市场中的有效竞争[1-3]。在如今中国激烈的成品油市场中,合理分配有限的营销资源、制定有效的营销策略在销售企业的营销活动中尤为重要[4-6],而“价格战”是进行营销的重要手段[7]。在大数据时代,统计数据分析方法与技术已在加油站选址[8-10]、加油站量价关系分析[11-13]、销量预测[14-15]等问题中有较多应用,由于成品油市场更加复杂、营销方式更加多样,营销效果的制定与评估难度也会大大提升[16-19]。为应对这些挑战,利用诸如深度学习等大数据分析技术,将大大提升营销模型的应用效果[20-24],更精确地刻画数据的规律。本研究以柴油加油站为主要研究对象,基于加油站运营数据(柴油量价数据、基础设施数据等)与外部环境数据(周边道路环境、人口环境、商业环境、车流环境等),将传统统计方法与机器学习、深度学习等技术相融合,建立了柴油加油站营销选择模型。本研究拟实现的主要研究目标为,通过对数据的分析与建模,构建多种营销投入规模下的加油站个体效应(Idividual Treatment Effect,ITE)评估框架,为既往柴油营销投入方案的评价和未来方案的制定提供量化依据。
1 柴油站运营数据选取与模型构建方法
本研究利用国内某大型石油公司(A公司)2020—2021年在L省加柴油油站的营销历史量价数据,通过对营销加油站与未营销加油站的联合建模,探索销量变化的一般性规律,精准提取、量化评估不同规模的营销投入对于各个加油站柴油销量影响的个体效应,为柴油营销投入方案的制定提供依据。
由于实际中各加油站的柴油销量受到多方面因素的影响,本研究拟考虑加油站自身属性等关键因素,包括站点柴油单价与周边人口信息、基础设施、商业环境、车流规模等。基于实际业务需求,本研究面临以下两方面的挑战。一方面,由于不同站点在自身属性、环境条件等方面具有异质性,对于相同的营销方案或投入规模,不同站点往往体现着不同的营销效果。因此,对于加油站个性化营销方案的制定需要将加油站间的异质性纳入考虑;另一方面,柴油销量与其影响因素间的作用机制较为复杂,譬如影响因素对销量的潜在非线性结构关系、影响因素之间交互甚至高阶交互的关联效应等。因此,在预测模型和推断模型的构建方面,本研究使用神经网络模型(Neural Networks,NN)和极端梯度提升(Extreme Gradient Boosting,XGB)对上述复杂的关系进行刻画。
基于历史数据,本研究在充分考虑加油站间异质性的前提下,通过构建个体效应评估框架实现对各个加油站在多种营销投入规模下个体效应的量化评估。依据评估结果可进一步分析与营销投入效果相关的影响因素,探索针对性地增加站点柴油销量、提升市场占有份额的有效途径。鉴于既往营销站点的选择往往依托实际需求背景因而具有非随机的特征,本研究考虑借助基于生成对抗网络(Generative Adversarial Networks, GAN)的因果推断方法处理既往营销试验数据中存在的选择偏倚,进而完成对数据的合理分析。
基于对各个加油站个体效应的评估和计划营销投入的资源总量,本研究将进一步构建出结合个体效应量化评估与实际业务需求的加油站营销投入方案制定模式。具体而言,本研究计划从个体效应量化评估和经验总结与业务需求两个维度考虑营销投入方案的制定问题。1)个体效应量化评估维度。由各个加油站个体效应的评估结果,遵循择优营销原则,可依据其营销效应排序进行营销投入规划,包括拟定实施营销投入的加油站名单和各个加油站的营销投入规模,进而完成在个体效应视角下对于营销投入资源的合理配置。2)经验总结与业务需求维度。依托历史数据与实际情况,总结提炼选站经验,对往期营销方案的科学性进行合理评估,并结合实际业务需求进行当期营销投入方案的制定。譬如,应避免为了营销投入效果最大化将营销投入全部集中在某几个地区,而忽视营销活动对于其他区域市场份额提升的可能性。此外,根据预测模型可对计划的营销投入方案的整体效果进行评估,预见性地得到在该方案下柴油销量的提升程度。
2 模型构建与实证
2.1 模型概述
本研究设定一个加油站在一天的柴油销量是关于营销强度(单位柴油降价量)的函数。在某营销强度元/L下,该加油站柴油销量与不进行营销投入时的销量差值,即为该加油站对于元/L这一营销强度下的个体效应,对于一个范围内的营销强度下个体效应的综合考虑,即为该加油站对于营销的个体效应。而实际情况下,每个加油站在每天只有一个营销强度下的销量观测值,我们的目标是为每个加油站在每个提前给定的若干营销强度下,都得到对于销量的估计,从而使得对于加油站个体效应的评估成为可能。
2.2 聚类分析
前期的探索性分析结果表明,不同加油站的销量水平之间存在较大差异,对所有加油站进行整体建模的估计效果较差。这提示不同加油站的自身属性、干预措施、投入等协变量与销量间的关系可能存在差异。为了更好地刻画协变量与销量间的关系,从而进一步提升模型对于反事实销量的预测表现,现有研究采用先聚类后建模的方式,首先将数据分割为各自同质的多份数据,其次在多个数据集上分别建模,以提升整体的模型拟合与预测效果[25-26]。本研究基于加油站的历史销量分布对站点进行聚类,并假定每一类中的加油站是同质的,进而对每一类内的加油站分别构建反事实销量预测模型。
本研究使用的聚类方法为快速柯尔莫哥洛夫-斯米尔诺夫K均值聚类[27](Fast Kolmogorov-Smirnov K-means clustering),该方法基于加油站销量的经验分布函数,使用K均值聚类的思想,对加油站进行聚类。加油站与加油站、加油站与类中心的距离使用标准化Kolmogorov-Smirnov统计量进行度量。聚类分析基于所有加油站2020年的日度销量数据进行。
本研究对聚类类别数进行探索发现,类别数量设置为3时能够实现对站点更为合理的划分。因此,考虑3类站点,并根据其销量分布情况,将其分别命名为低销量组、中销量组和高销量组,在后续分析中对各类别加油站进行分别建模。
2.3 生成对抗网络
本研究使用生成对抗网络进行每个加油站在不同营销强度下的销量预测。生成对抗网络是博弈理论在有监督学习方面的成功应用,能够更好地得到贴近真实数据分布的销量估计值[28-29]。举例说明,某加油站在某一周都保持了1元的单位油价降幅,销量有明显增长。使用生成对抗网络,可以估计得到若在这一周没有做任何营销,该加油站的柴油销量。实际得到的观测值和生成对抗网络生成的反事实销量的差值,可用于衡量该加油站销量对于1元的单位油价降幅的敏感程度。
本研究使用的生成对抗网络适用于连续干预值[30],其共有三部分构成,分别为生成器、判别器和用于反事实销量预测的推断模型。三部分模型均为神经网络模型。生成器和判别器的结构如图1所示(以两种干预措施为例)。记加油站属性及环境特征为观测到的销量为,接受的干预(营销/非营销)和投入为,以及一些噪音变量(例如多元正态分布),则生成器可表示为:

在实际建模时,本研究使用的数据为所有加油站2021年6月的日度数据。加油站属性和环境特征变量包括加油站所在城市、挂牌价格、部分历史信息(往期销量、往期提枪次数、往期折扣、往期每升折扣、往期挂牌价格)、加油站附近的车流量信息(2km和3km内车流量)、加油站周边环境信息(总人口、人群活动指数、道路长度、建设用地面积、建筑物面积、夜光指数、平均海拔、平均坡度、稳定夜光指数)。投入变量为每升折扣,考虑到没有营销对应的投入变量只存在0这一种取值,因此,本研究将干预变量设置为相同的值,只通过投入变量的取值来区分是否进行了营销。当投入变量取值为0时,对应没有营销;当投入变量大于0时,对应不同的营销强度。
对于一组生成的干预-投入对,对应的反事实销量预测为ycf(t)=G(x,tf,yf,z)(t),基于生成器生成的所有干预的投入-销量对,判别器将对这些数据进行判别,以区分其是否来自于真实的干预和投入。判别器由两部分组成,分别为干预判别器DW:X×∏w∈W(DW×У)nW→[0,1]k和投入判别器DW:X×(DW×Y)nW→[0,1]nw,其中nw为设置的对应于干预的投入水平的数量。干预判别器用于判别每一个干预为真实干预的概率,投入判别器用于判别每一个投入水平为真实投入水平的概率。
整体的判别器定义为DH:X×∏w∈W(DW×Y)nW→[0,1]∑nw,当生成器和判别器训练完成后,为了在没有真实干预措施和投入的情况下得到反事实销量预测,需要进一步训练一个推断模型。推断模型定义为I:X×T→Y,其输入为加油站自身属性和环境特征,以及想要得到的反事实销量对应的干预和投入,输出为反事实销量预测值。本研究尝试了多种模型作为推断模型,包括神经网络、随机森林、提升法和极端梯度提升法,综合考虑时间和拟合优度,选取了极端梯度提升为最终的推断模型,其在测试集上的拟合优度为0.9023。
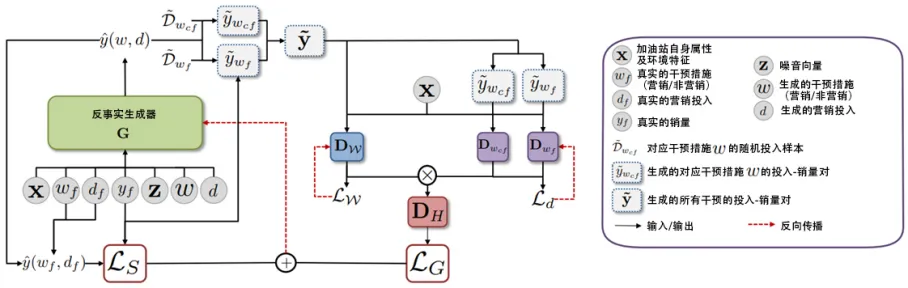
图1 生成对抗网络生成器和判别器结构示意(以两种干预措施为例)
生成器和判别器的训练通过对下式进行优化求解实现。
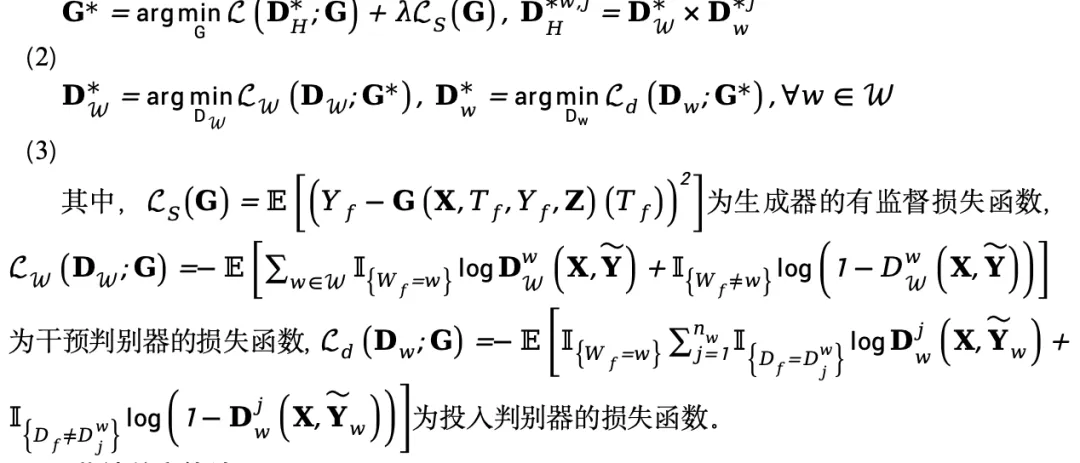
2.4 营销效应估计
模型对各个加油站在不同营销水平下的销量估计值进行预测。在已有历史数据中,营销强度介于0元/升至1.6元/L之间,但是营销强度介于1元/L至1.6元/L的观测数量非常少,例如2021年4月份的33458条数据观测中,仅有210个观测的营销强度介于1元/L,这对于估计反事实结局变量与营销强度之间曲线上强度大于1元/L的部分非常不利。因此,本研究考虑11种营销强度d0,d1,…,d10分别为0.0,0.1,…,1.0,其中营销强度为0即为不营销的情况。在该种设定下,每个站点将基于预测模型产生11个销量预测值,分别代表不进行营销的基准销量水平y0和10种非零营销投入下的销量水平yd1,…,yd10。
基于不同销量预测值,考虑以下指标对站点营销效应进行量化。首先,在给定某个营销强度d下,计算各个加油站的个体条件绝对营销效应T(d)=yd-y0;考虑到加油站自身的销量规模对个体营销效应的潜在影响,可将个体绝对营销效应与基准销量相除求得各个加油站的个体条件相对营销效应△(d)=(yd-y0)/y0,T(d)和△(d)均为给定某营销强度d下的条件营销效应(Conditional ITE,CITE)。根据各个站点的CITE,通过加权平均可得整体的个体绝对营销效应(AITE)T和个体相对营销效应(RITE)△,其中权重的选择考虑为等权重,在实际应用时也可考虑与d的大小成比例,或参考业务经验设定。站点的T和△即为反应该站点对于不同营销水平下营销效应的综合度量,将其称为该站点的ITE。
2.5 反事实结局变量估计
基于2021年6月份的数据,本研究发现估计得到的反事实结局变量具有较大的波动性。具体来讲,在不同的数据训练集、测试集、验证集划分下,分别拟合模型、估计反事实结局变量进而得到ITE,基于不同数据划分的ITE波动性较大。举例说明,图2是2021年6月份的数据在两种不同数据划分下得到的各个站点的AITE和基准销量估计值的散点图,可见虽然部分典型站点在两次数据划分下相同(例如N046、A157、L040、C066等),但基准销量和AITE存在一定的波动。
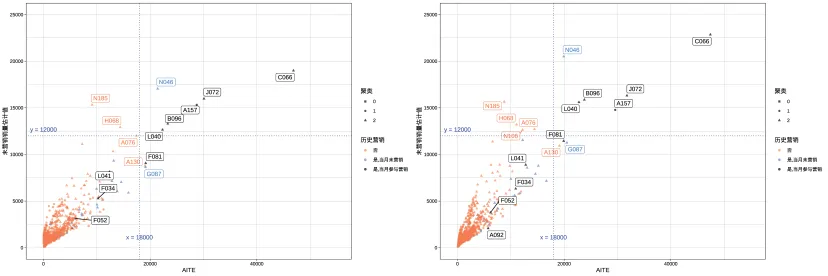
图2 2021年6月份数据在两种数据划分下的站点AITE与基准销量估计值散点图
为了减轻模型结果的波动性,本文结合随机森林等集成学习的思想,将不同数据划分下的结果进行模型平均[31-32],具体做法如下。按照固定的比例将数据划分为训练、测试、验证集,独立划分K次(例如K取5次)。选定一组超参数组合,在K次数据划分下,都分别在各自的训练集上拟合生成对抗网络,并在验证集上基于拟合的生成对抗网络得到结局变量的估计以及估计的均方根误差(RMSE),将K个验证集上的RMSE取平均。对于不同的超参数组合,都得到相应的RMSE均值,选取最优的RMSE对应的超参数作为最终选定的超参数组合,并基于这一组合重新拟合K次数据划分下的生成对抗网络,并基于各自的生成对抗网络得到所有反事实结局变量的估计,拟合各自的推断网络。在K个拟合的的推断网络上分别得到估计的反事实结局变量估计值,它们的平均值即为基于模型平均的反事实结局变量估计。当K=4时,如图3展示了两次模型平均结果的各个站点的AITE和基准销量估计值的散点图,可以发现相较于图2,图3的两张散点图明显结果更为接近,稳定性更好。此外,从数值层面,相比于未平均结果,基于模型平均估计结果的变异系数减小70%,大幅降低了结果的波动性。
综合来讲,模型平均结果的稳定性都远优于未平均的结果,说明该建模思路能够有效减小估计的波动,得到更稳定、更可靠的结果。
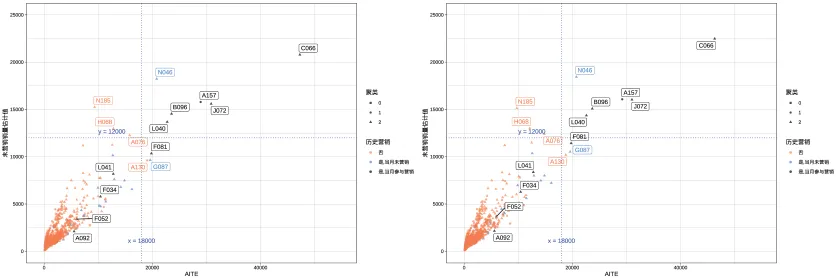
图3 对于6月份数据在两组4次数据划分模型平均下的站点AITE与基准销量估计值散点图
2.6 估计结果
基于求得的ITE估计结果进行可视化如图4所示。其中,横纵坐标分别代表AITE值和无营销投入时的基准销量估计;蓝色为历史数据中当日未参与营销的站点,红色是一直未开展营销的站点,黑色表示当日参与营销的站点;以AITE值等于18000和基准销量等于12000为分界对坐标系进行划分,在第一象限内的站点基准销量和AITE均较高,包括N046、A157等,其中A157参与了历史营销。这类站点既对于营销敏感,相同投入下能有更高的销量提升,又有很高的基准销量水平,能抢占市场,要给予较大的关注;对于AITE值较低但自身基准销量较高的第二象限中站点,应继续保持一定的营销水平维持住销量;聚集在坐标原点附近的站点因其AITE值和销量均表现不佳,不应在开展营销的重点关注对象范围内,这类站点虽不具备AITE和基准销量上的优势,但仍存在部分营销站点,例如当日参与历史营销的L041,其AITE其实已经大约在13000,对于营销具有不错的敏感程度;第四象限的高AITE站点A130未参与往期营销,并且存在较大的营销潜力,站点G087这一值得营销的站点参与了往期的历史营销。属于第一、第二、第四象限的站点都属于典型加油站点。
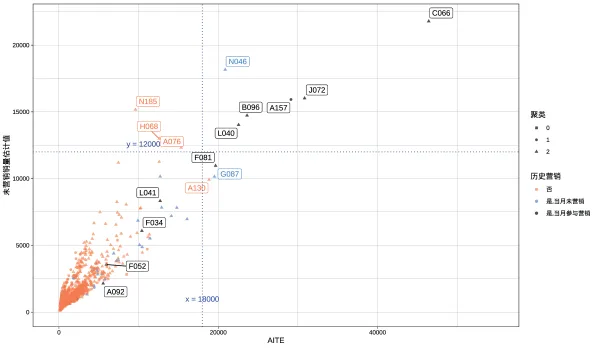
图4 基于AITE的站点营销效应散点图
下面进一步对图4中部分典型站点的地理分布进行探索。图5给出了典型站点的地理分布情况,其中蓝、黄、红三色的圆点分别表示图4中第一、第二、第四这3个象限内标注出编码的典型站点,绿色的圆点代表工业园区;第一象限的点,即蓝色点,代表本身销量高且AITE也高的站点,它们基本都处于主干道和工业园附近,应当给予它们重点关注;图5中黄点为第二象限的点,这些点代表基准销量较高、AITE不拔尖的站点,它们处于主干道附近、或临近沈阳的大片工业区,是车流量较大、竞争激烈的区域;第四象限的三个点,也就是红色的点,它们代表基准销量不高、但非常有潜力的站点,它们大多分布在主干道上。
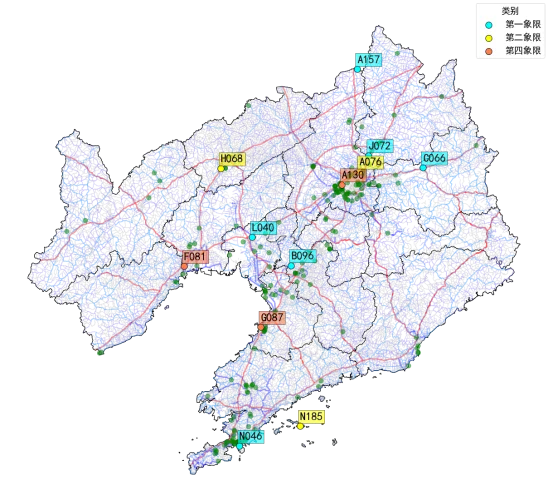
图5 典型站点分布
图6进一步提供了地理位置与AITE大小情况的可视化分析结果。其中,圆点的颜色表示站点是否加入历史营销(蓝色表示参与但当日未参与,黄色表示当日参与,红色表示不参与),其大小表示AITE的大小,绿点为工业园区。由图6可见,A130的ITE较大,位于沈阳的工业区附近,有非常大的潜力。除此之外,A076等几个未营销站点,呈现较大的AITE,具有一定的营销潜力,是未来可以关注的站点。
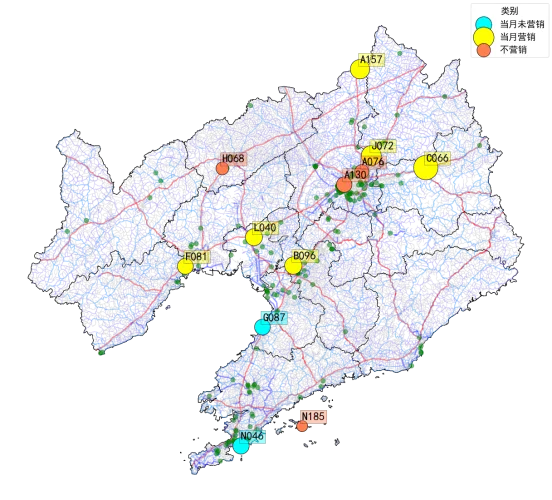
图6 典型加油站AITE大小与地理位置分布
除了上述分析的典型站点,图7展示了整个历史营销时期内营销站点的分布情况,其中蓝色和红色分别表示是否加入历史营销,可见参与历史营销的站点广泛分布在L省内的各大城市中,该结果也进一步表明在实际制定营销方案、选定营销加油站时,可能需要在各大城市均选择一些站点开展营销,增大影响范围。
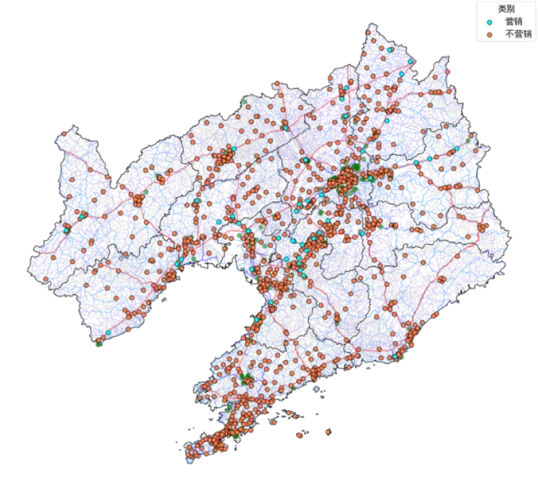
图7 营销站点分布
图8补充展示了往期营销方案中RITE与基准销量的散点图。图中横纵坐标分别代表RITE值和无营销投入时的基准销量;蓝色为参与2021年6月18日的营销但当日(模型测算当天)未参与营销的站点,红色是未参与的站点,黑色表示当日参与历史营销的站点;与AITE相较而言,在考虑RITE时,部分自身基础销量较高站点的ITE优势有所减弱,同时,部分站点对于营销投入表现出高于自身基础销量(大于2倍)的提升。
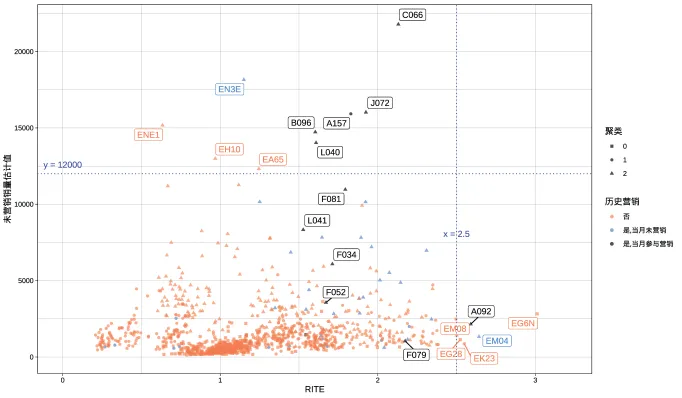
图8 基于RITE的站点营销效应散点图
3 模型应用
3.1 站点营销优先级排序
根据各个站点的CITE,进行不同站点间的比较分析。根据AITE、RITE和投入产出比(IOR)三种效应指标,分别绘制指标在不同营销强度下的排序热力图(见图9—11)。这3个图仅展示了在不同营销强度下效应指标中位数排序位于前60的示例站点;热力图颜色接近红色代表站点的指标排序靠前(效应值较高),颜色接近白色则表明排序靠后(效应值较低)。
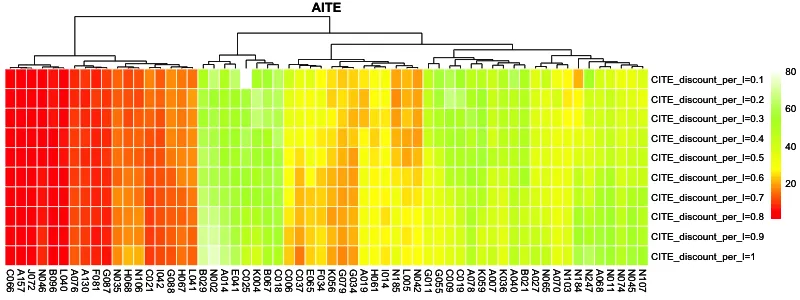
图9 不同营销强度下的绝对营销效应值AITE排序热力图
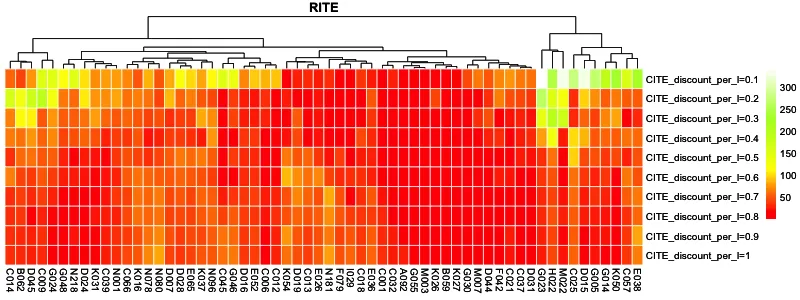
图10 不同营销强度下的相对营销效应值RITE排序热力图
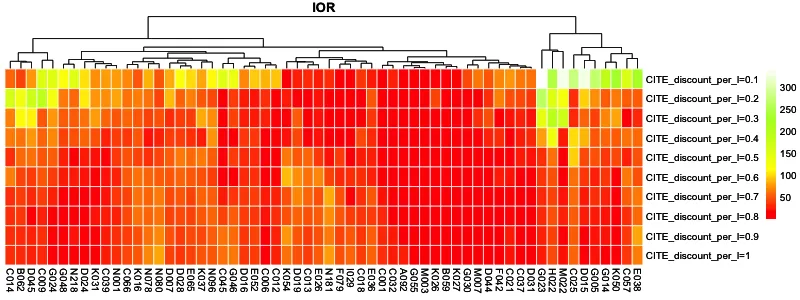
图11 不同营销强度下的投入产出比IOR排序热力图
1)从不同的效应指标结果对比来看,在不同的营销指标下排名中位数水平靠前的站点及站点在各营销强度下的排序情况均有一定差异。具体来看,AITE反映了绝对意义上的销量提升水平,RITE关注销量提升的水平相较自身基准销量的比例,IOR则对每单位(元)营销投入所能带来的销量提升进行量化。在实际应用中,建议结合业务经验和实际需求对使用的衡量标准进行确定。2)从站点在不同营销强度下的效应值变化来看,各站点对于营销投入的敏感程度各有差异。以图9为例,位于最左侧的少部分站点在各营销水平下均呈现出显著的AITE优势;位于中部的C037站点在较高的营销强度下AITE值较低(排序较为靠后),而在低投入下营销表现较为优越;而中右部分的一些站点(例如N185站点)则反之,在高投入下效应值排序靠前,而对较低水平的营销投入表现欠佳。因此,根据各站点对营销投入的敏感程度(销量提升潜力)或投入产出情况进行选站并确定其最优营销投入强度是具有实际意义的。
具体地,一方面,在方案制定过程中,在D个营销强度d1,d2,…,dD下,可以求得AITE(RITE)与营销投入的梯度,每个站点会有D-1个梯度,梯度越大的地方代表该站点对于该营销投入力度越敏感,对当前力度的营销反馈越理想;另一方面,出于节约成本的考量,方案希望能够通过更低的营销投入来实现整体销量提升的目标,因此投入(营销投入)产出(销量提升)杠杆值高的营销强度更为青睐。使用AITE、RITE或投入产出比确定营销强度衡量是对于不同营销效果,也可以考虑构建三者的综合指标比如加权平均作为确定营销强度的指标,这取决于决策者期望达到的营销效果。此外,本研究考虑将除站点自身营销效应值以外的选址原则归纳为“业务经验”,譬如,在选站的过程中可能要优先考虑规模较大的站点等;并在方案制定过程中将该部分经验信息与营销指标进行综合考虑完成营销方案的制定。
下面给出一种综合考虑营销效应和业务需求的营销策略制定方案。其中营销效应方面考虑由站点的AITE和RITE加权求和得到的站点营销效应综合指标ITE值,业务需求方面考虑保证一定的站点基准销量,综合两方面构建综合性指标对站点进行排序。给定权重参数p1,p1a,p1r,p2,其中p1为ITE对应的权重,p2为基础销量规模(即无营销投入下的销量)确定的权重,满足p1+p2=1;而和分别为AITE和RITE在ITE项中的权重,满足。根据权重参数、ITE值和基础销量值,每个站点的投入优先级指数可以用下式表示:
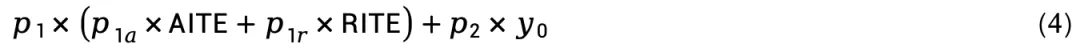
对所有站点的指数进行排序可以得到站点的营销优先级排序。
3.2 成本约束下的策略模拟
在实际应用中营销成本往往是有限的。在给定的成本约束Cmax下,按照营销优先级排序依次进行站点的逐个优选及其营销强度的确定,直至成本耗尽。具体来讲,首先选择优先级最高的站点纳入营销,得出该站点营销强度后可结合该强度下的销量预测值得到相应的营销投入估计值,在总的成本约束上减去该营销投入值,接着在剩余的营销成本中选择第二优先站点进行营销,直至投入达到给定的营销成本上限。
使用上述步骤进行模拟营销策略的制定,可以测算出一组2021年6月18日当日参与历史营销的站点(12个站)。基于当前预测数据,可求得历史营销站点的营销效应(销量提升值)为474221.3,历史营销投入为585281.3元。在参数设置P1=0.8,P1a=0.5,p1r=0.5,P2=0.2,p4=5,成本上限Cmax=585281.3下,使用ITE变化敏感度确定建议营销强度。本研究进一步测算一组的营销策略建议参与营销的最优站点(15个站),相应的营销投入(元/L)建议值分别为1.0、1.0、1.0、1.0、1.0、1.0、1.0、1.0、1.0、1.0、1.0、0.9、0.6、0.1和0.1。在该策略建议下,预计营销投入为585274.3元,销量将提升585274.3L,相较于原营销方式增加了近1/4的销量提升,是非常有效的营销策略制定方法。
4 总结与展望
在柴油市场的激烈竞争中,大规模营销投入是抢占市场的重要手段。如何制定合理的营销方案对于营销投入的产出具有重要影响。本文从数据驱动和实际需求的双重角度,提供了有效的营销方案制定模式,具有重要的意义。借助神经网络、极端梯度提升等前沿深度学习、机器学习方法,本研究提出的模型在测试集上的拟合优度达到了0.9023,并在模拟策略制定上对营销效果达到了近25%的提升。如果没有数据上的限制,能够结合其他公司的加油站运营数据,能对不同公司加油站之间的竞争关系纳入模型,进一步提升销量估计效果,并在方案制定中结合对手信息更好地制定营销方案。此外,成品油市场大环境随时间不断变化,基于往期数据可能不适用目前的环境。在新数据上测试模型的拟合优度,可以验证模型在时间维度上的迁移性,或定期对模型进行更新,增加模型在时间上的适用性。对模型的训练和模拟策略的制定进行工程化、软件化,可以使模型的更新与再训练更加便利,同时也有益于本研究成果的推广。
参考文献:
[1]HAUSER J R. Competitive price and positioning strategies[J]. Marketing Science, 1988, 7(01): 76-91.
[2]CHOI S C, DESARBO W S, HARKER P T. Product positioning under price competition[J]. Management Science, 1990, 36(02): 175-199.
[3]刘征宇. 精准营销方法研究[J]. 上海交通大学学报, 2007(S1): 143-146+151.
[4]黄晓莉. 中石油国内成品油市场营销战略分析[J]. 经贸实践, 2017(18): 159.
[5]王世家. 新形势下成品油零售企业经营对策分析[J]. 现代工业经济和信息化,2023, 13 (07): 234-236+239.
[6]莫家钦. 成品油零售市场开放背景下加油站营销(策略)分析[D]. 北京: 中国石油大学(北京), 2020.
[7]林木. 谈谈成品油价格战[J]. 中国储运,2017(08): 36-37.
[8]CHAN T Y, PADMANABHAN V, SEETHARAMAN P B. An econometric model of location and pricing in the gasoline market[J]. Journal of Marketing Research, 2007, 44(04): 622-635.
[9]KIM J-G, KUBY M. The deviation-flow refueling location model for optimizing a network of refueling stations[J]. International Journal of Hydrogen Energy, 2012, 37(06): 5406-5420.
[10]THIEL D. A pricing-based location model for deploying a hydrogen fueling station network[J]. International Journal of Hydrogen Energy, 2020, 45(46): 24174-24189.
[11]张蕾, 仇玄, 丁少恒,等. 加油站汽油营销区域协同方法及实证研究 [J]. 国际石油经济,2023, 31 (08): 82-89.
[12]JUNG H, KWON K-M, YU G J. Fuels sales through retail chains and their store traffics and revenue[J]. Asia Pacific Journal of Marketing and Logistics, 2019, 31(01): 2-13.
[13]HASTINGS J S. Vertical relationships and competition in retail gasoline markets: Empirical evidence from contract changes in Southern California[J]. The American Economic Review, 2004, 94(01): 317-328.
[14]SUN L, XING X, ZHOU Y, et al. Demand forecasting for petrol products in gas stations using clustering and decision tree[J]. Journal of Advanced Computational Intelligence and Intelligent Informatics, 2018, 22(03): 387-393.
[15]THEMIDO I H, QUINTINO A, LEITãO J. Modelling the retail sales of gasoline in a Portuguese metropolitan area[J]. International Transactions in Operational Research, 1998, 5(02): 89-102.
[16]卓慧. 大数据背景下成品油零售市场的精准营销研究[D]. 南宁: 广西大学, 2017.
[17]梁山清, 李博. 基于大数据的加油站精准营销设计[J]. 计算机与网络, 2021, 47 (06): 64-67.
[18]刘速, 杨文军. 基于互联网与大数据的加油站智慧营销[J]. 信息技术与标准化, 2019(05): 53-57.
[19]ZHOU J, WU Y, TAO Y, et al. Geographic information big data-driven two-stage optimization model for location decision of hydrogen refueling stations: An empirical study in China[J]. Energy, 2021, 225: 120330.
[20]MIGUÉIS V L, CAMANHO A S, FALCÃO E C J. Evaluating the short-term effect of cross-market discounts in purchases using neural networks: A case in retail sector[J]. Expert Systems, 2019, 36(06): e12452.
[21]PAN S-Y, LIAO Q, LIANG Y-T. Multivariable sales prediction for filling stations via GA improved BiLSTM[J]. Petroleum Science, 2022, 19(05): 2483-2496..
[22]YU L, YANG Z, TANG L. Prediction-based multi-objective optimization for oil purchasing and distribution with the NSGA-II algorithm[J]. International Journal of Information Technology & Decision Making, 2016, 15(02): 423-451.
[23]RIZVI S M H, SYED T, QURESHI J. Real-time forecasting of petrol retail using dilated causal CNNs[J]. Journal of Ambient Intelligence and Humanized Computing, 2022, 13(02): 989-1000.
[24]CAI H, JIA X, CHIU A S F, et al. Siting public electric vehicle charging stations in Beijing using big-data informed travel patterns of the taxi fleet[J]. Transportation Research Part D: Transport and Environment, 2014, 33: 39-46.
[25]HENZEL J, BULARZ J, SIKORA M. Impact of time series clustering on fuel sales prediction results[C]//Position and Communication Papers of the 16th Conference on Computer Science and Intelligence Systems. Warsaw, Poland: PTI, 2021: 13-21.
[26]NEPAL B, YAMAHA M, YOKOE A, et al. Electricity load forecasting using clustering and ARIMA model for energy management in buildings[J]. Japan Architectural Review, 2020, 3(01): 62-76.
[27]ZHU Y, DENG Q, HUANG D, et al. Clustering based on Kolmogorov-Smirnov statistic with application to bank card transaction data[J]. Journal of the Royal Statistical Society Series C: Applied Statistics, 2021, 70(03): 558-578.
[28]王坤峰, 苟超, 段艳杰, 等. 生成对抗网络GAN研究进展与展望[J]. 自动化学报, 2017, 43(03): 321-332.
[29]梁俊杰, 韦舰晶, 蒋正锋. 生成对抗网络GAN综述[J]. 计算机科学与探索, 2020, 14(01): 1-17.
[30]BICA I, JORDON J, VAN DER SCHAAR M. Estimating the effects of continuous-valued interventions using generative adversarial networks[J]. Advances in Neural Information Processing Systems, 2020, 33: 16434-16445.
[31]张新雨, 邹国华. 模型平均方法及其在预测中的应用[J]. 统计研究, 2011, 28(06): 97-102.
[32]ZHANG X, LIU C-A. Model averaging prediction by K-fold cross-validation[J]. Journal of Econometrics, 2023, 235(01): 280-301.
全文刊载于《车用能源储运销技术》2026年第2期,敬请订阅。
END

扫码关注
车用能源
订阅热线|010-62065311
投稿邮箱|cynycyx@163.com