美国营销公司Single Grain用AI提效的四个成功经验
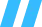
美国的头部数字营销公司Single Grain创始人Eric Siu,在自己公司里深度跑 AI Agent 工作流,系统建崩了好几次,才总结出一套真能用的东西。
我长期帮企业做 AI 落地部署,感觉他踩过的那些坑,比大多数行业报告值钱得多。
第一个坑:以为给 AI 塞越多越好
Single Grain 一开始给 Agent 加了很多”记忆”——通话录音、笔记全灌进去,想着让系统记住人类容易忘的东西。跑了三周出问题了。
持久记忆文件吃掉了上下文窗口 40% 的容量,Agent 信息量上去了,但该取的时候取不到对的,技术上确实更”聪明”了,实操里反而更乱。
信息量过了临界点,噪音就把信号淹了。
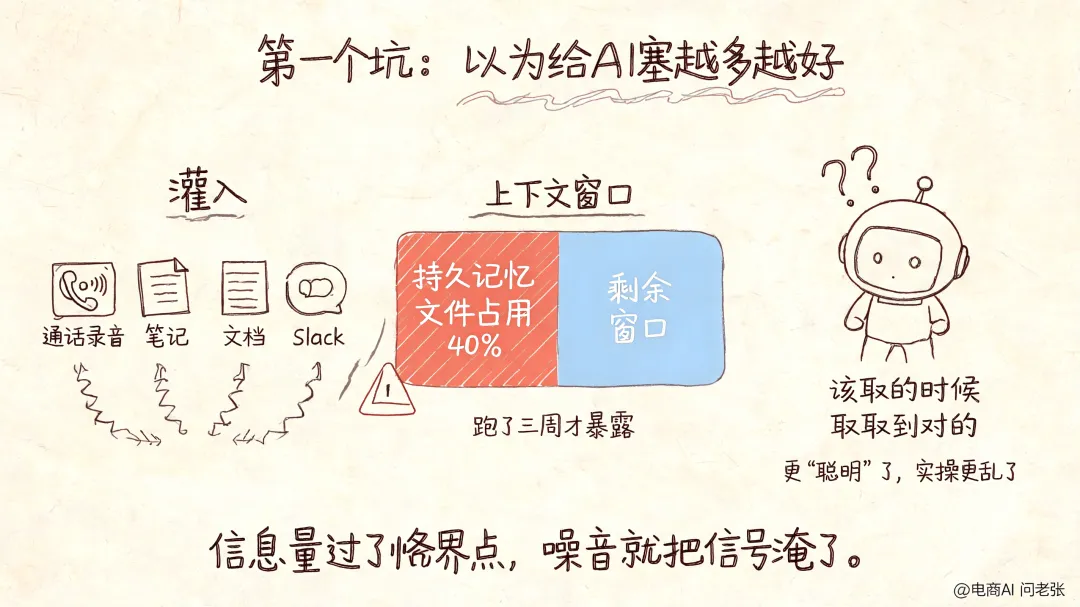
记忆是原料,检索才是刀
旧流程是一条直线:通话记录靠人记,Agent 每次冷启动,人再讲一遍。人成了路由器,工作流质量全看有没有人记住那通对的电话、复制了那笔记。这条路没法规模化。
改完之后,通话记录、CRM、SOP、Slack 全部汇到一个检索层,Agent 从那里取它需要的东西,人的纠正通过反馈循环写进规则。
以前拼的是 Agent 记住了多少,现在是 Agent 能不能在对的时刻取到对的东西。两码事。
这个认知转过来,整套系统才开始重建。
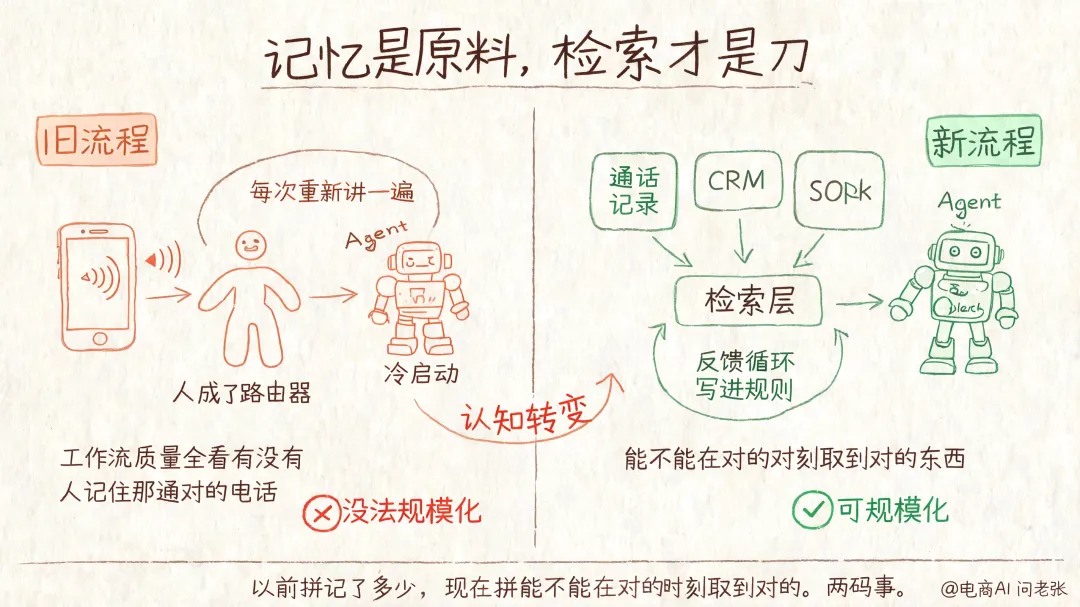
五层架构,少一层就漏
Eric 把公司大脑拆成五层:捕获、检索、信源真相、权限、反馈循环。
捕获层是大多数团队开始建、也停下来的地方。录会议、存 Slack、把文档倒进向量数据库,然后管这叫”公司大脑”。
这只是一个储物间——它不知道哪条信息过期了,不知道来源打架时谁赢。更大的存储不会自动让系统变聪明。
检索层解决精准度。Agent 不需要公司全部历史,只要跟当前任务最相关的那六七样东西。很多 AI 系统 Demo 看着聪明,因为演示者手工喂对了上下文,一上生产就崩。原因很简单:没建检索层,本质上还是人在做路由。
信源真相层解决”信哪个”。销售通话、CRM 字段、Slack 里的修正意见、旧版 SOP——四样东西互相矛盾的时候,Agent 该信谁?
没提前定义好优先级,系统就会变成 Eric 说的——”格式更好的自信的撒谎者”。答案措辞漂亮,但你不知道它信的是哪版真相。
权限层管边界。营销 Agent 不用碰 HR 细节,内容 Agent 不需要看客户财务数据。服务型公司这层建晚了,要么信息漏出去,要么把系统限制到没法用。
反馈循环是让系统自己滚雪球的地方。每次人纠正了 Agent,那次纠正就该变成未来的规则。
措辞生硬就更新语气规则,漏了 CRM 风险信号就更新管道扫描逻辑。没这层你只是在盯软件,有了它,每次纠错都在给整套操作系统做训练。
先答六个问题,再谈自动化
Eric 给了一个实用的自测。从你手头某个重复工作流开始,问六个问题:依赖哪些信息来源?来源矛盾时哪个赢?Agent 启动需要什么上下文?Agent 绝对不该看什么?人工纠错以什么形式反复出现?一次纠正怎么变成未来规则?
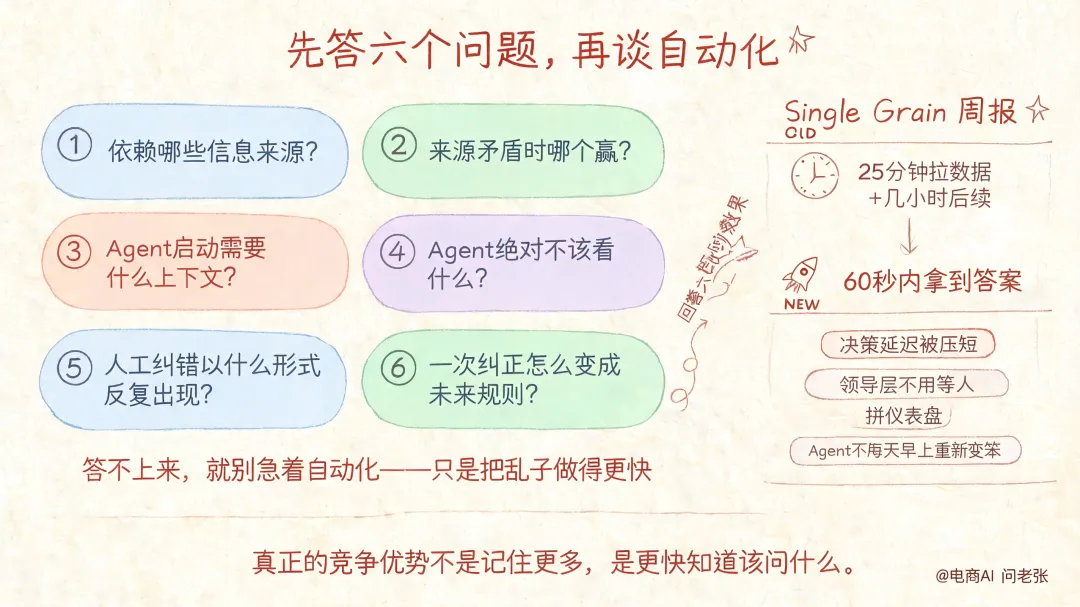
答不上来,就别急着自动化——只是把乱子做得更快。
Single Grain 的周报工作流:旧流程 25 分钟拉数据加几小时后续跟进,接入公司大脑后 60 秒内拿到答案。
时间节省是顺带的,更要紧的是决策延迟被压短了——领导层不用等人拼仪表盘,运营不从头开始,Agent 不用每天早上重新变笨。
真正的竞争优势不是记住更多,是更快知道该问什么。