10分钟从零组建的AI营销团队,2026年独立创作者的效率天花板,全在这里了


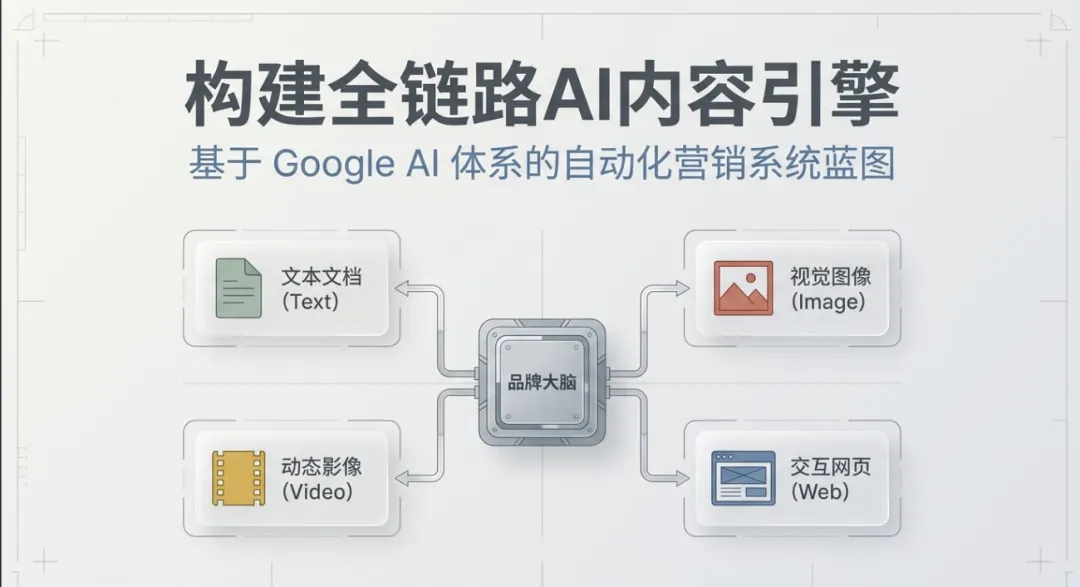
其实,如果你关注了今年的 Google I/O 大会就会发现,AI 的发展早就不再是单个聊天框的对话了。谷歌在悄悄下一盘大棋,他们把旗下几乎所有的前沿 AI 模型和自动化工作流打通了。今天,我想和大家聊聊,如何不花一分钱稿费、不招一个剪辑师,单纯依靠谷歌的 AI 生态,把一堆零散的品牌原始资料,在十几分钟内转化为一条自动运转的内容生产线。
知识库的“套娃”艺术:从零组建你的品牌终身大脑
很多创作者在用 AI 写推文或者做文案时,最痛苦的不是 AI 不会写,而是每次都要重新喂一次背景资料,或者写出来的东西总有一种“AI 腔”,完全不符合品牌的调性。
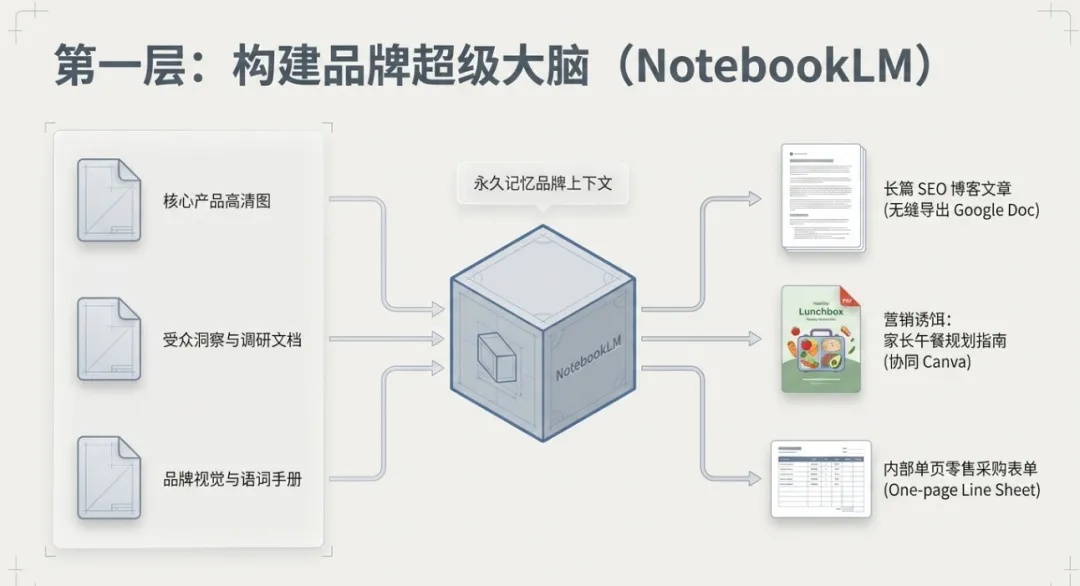
我发现一个绝佳的解法,就是利用谷歌最近直接打通并嵌入 Gemini 内部的 Notebook LM 功能。
你可以把它想象成一个拥有专属记忆的“项目空间”。比如我们要做一个健康零食品牌的营销,你可以把这个品牌所有的核心产品参数、目标用户画像、甚至之前的私域反馈 raw 文件,一股脑全部打包成一个“品牌知识库笔记本”。
最神奇的地方在于,当你回到 Gemini 的主对话框时,可以直接挂载这个笔记本。我尝试用一份标准的公众号文章大纲模板喂给它,并让它基于知识库里的产品信息生成推文框架。
它不仅能严丝合缝地遵循你的排版视觉逻辑,甚至在开启“画布模式(Canvas Mode)”后,可以直接生成排版精美、带内文插图的完整推文。因为有前置知识库的约束,生成的配图会自动调用你上传的产品图作为特征参考,出来的视觉风格极度统一。更让人省心的是,由于谷歌生态的无缝连接,你可以一键将这些带有图文排版的初稿导出到 Google Docs,团队成员可以直接在上面留批注、改细节,协作效率被瞬间拉满。
视觉裂变的降本秘密:从一张海报到全渠道像素级适配
做内容运营的人都知道,好不容易设计出了一张满意的公众号封面或者海报,接下来才是噩梦的开始:你要把它裁剪成小红书的 4:5 比例、朋友圈的 1:1 矩形,还有各种信息流的垂直比例。
在过去,这需要设计师在 PS 里一张张重新调图层。但这次更新的 Imagen 模型,其“画布迭代”和自动重组能力简直让人惊艳。
当你需要一张网站焦点图时,Imagen 生成的第一版往往就足够惊艳。如果你觉得中间的某个元素不合适,不需要重写长篇大论的提示词,直接用内置的“画笔工具(Sketch Tool)”在图上圈出那个产品,敲一行字“去掉它”,AI 就能完美理解上下文并进行无痕消除。
更厉害的是它的“重组布局(Recompose Layout)”能力。你只需要把一张现有的正方形视觉素材喂给它,告诉它:“帮我重新排版成适应手机全面屏的竖版垂直比例,并保持品牌视觉一致。”
只需要短短 10 秒钟,AI 就会自动识别出背景、主体和延伸视觉,给你生成一张可以直接拿去发视频号或朋友圈的全新构图素材,完全没有生硬拉伸的拼接感。
为了帮大家在实际运用中彻底摆脱反复测试提示词的痛苦,我特意将谷歌官方营销案例中的核心工作流,以及一套可以直接套用的《Imagen 意图级提示词与AB测试模版》整理成了 PDF 文件。这份资料重点梳理了如何从粗糙初稿一步步微调出商用级视觉的“迭代阶梯”技巧,能帮你省下大把的测试额度。如果你需要的话,直接在咱们公众号后台私信回复 【谷歌营销】 就能免费获取。
如果每次做图都要重新调教 AI,这显然不符合我们追求自动化的初衷。为此,你可以利用“Gemini Gems”功能,打造一个专属于你、具备特定技能的“数字分身”。比如,你可以创建一个名为“电商摄影师”的专属 Gem,把你们品牌的标准视觉调性、产品包装的标准尺寸、甚至灯光风格说明作为底座知识喂给它。以后团队任何人只需要传一张手机拍的产品图进去,它就会自动调用 Imagen 模型,批量吐出工业级、高保真的场景大片。
物理级视频模型的降临:打破多镜头 character 崩塌的魔咒
文字和图片搞定了,那现在最吸流的短视频怎么办?这就要提到谷歌最近惊艳科技圈的 Veo 模型了。
以前用 AI 做视频,最大的痛点有两个:一是画面不符合现实世界的物理规律,经常出现物体凭空消失或扭曲;二是前后镜头的人物经常“变脸”,换个角度就像换了一个人。
而 Veo 模型的底层逻辑是具有强烈的“物理感知推理能力(Physics-aware reasoning)”。
当你上传几张产品图,并让它生成一段“模特拿着产品在厨房里微笑着向观众展示”的 10 秒短视频时,你会发现,无论是模特的肢体动作、光影在产品包装上的折射,还是多镜头切换时人物面部特征的稳定性,都无限逼近真实拍摄。
当然,目前的视频模型每天的生成额度非常珍贵,为了避免盲目测试浪费额度,我建议你先用专门的“分镜 Gem”帮你策划脚本。把品牌诉求和官方提示词指南喂给它,让它先吐出逐帧的画面描述和分镜示意图。当你对分镜的逻辑和视觉满意后,再把这些分镜图作为 raw 素材正式喂给视频引擎,这样出来的成片可控度会高出成倍。
如果你觉得在聊天框里一段段生成视频还是太零碎,谷歌还提供了一个叫 Google Vids 的多轨影音工作室(Flows 空间)。在这里,你可以直接创建并沉淀一个“数字品牌代言人”。只需要上传一张参考照片,选好声音调性,这个数字化角色就会永远固化在你的项目组里。
在 Flows 空间里,你甚至可以开启高级的“Agent(智能体)模式”。你只要给它一个产品链接,告诉它:“帮我生成 3 种不同运镜、不同视觉风格的视频广告预告片。”这个 AI 智能体就会自己去规划任务、调用模型,在生成前还会主动向你弹窗确认:“我已经设计好了 3 种运镜方案,是否开始渲染?” 这种仿佛在指挥一个资深视频导演的共创体验,确实颠覆了传统的内容生产流程。
最后,谷歌甚至还拿出了一个叫 Palminy 的大杀器。它能直接分析你的网站,提取你的品牌 DNA、标准色和 Slogan。分析完之后,它会自动在后台根据当下的营销热点(比如世界巧克力日),为你自动生成全套的、极其符合品牌视觉的社交媒体海报、动画文字甚至促销落地页。你甚至可以通过对话直接让它修改落地页上的“立即购买”按钮链接,一键就能发布上线。
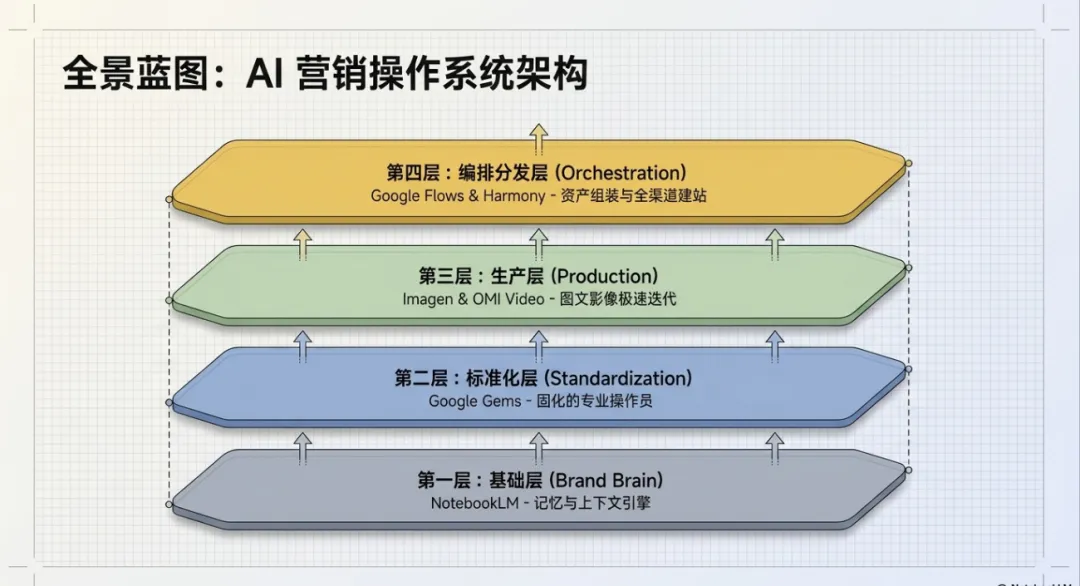
从 Notebook LM 的品牌大脑,到 Imagen 的画布迭代、Gems 的工作流固化,再到 Veo 的多轨视频智能体,谷歌其实已经把一整套内容营销的超级工厂,无缝地拼装在了我们面前。作为创作者,我们不再需要去苦修各种软件的复杂操作,而是要学会如何成为那个手握品牌 DNA、指挥 AI 矩阵的“总导演”。
每次看到这些工具的迭代,我都在想,未来的内容生态到底会变成什么样?当生产一条高质量视频或图文的门槛无限趋近于零时,我们作为创作者,最核心的壁垒究竟变成了什么?是那套独特的品牌灵魂,还是对用户痛点更细腻的洞察?
你在尝试用 AI 做内容的过程中,遇到过最让你抓狂的瓶颈是什么?是画面总是调不准,还是文字缺乏人情味?欢迎在评论区聊聊你的看法,我们一起在评论区碰撞出新的提效火花。
欢迎围观我的朋友圈

我是Leeka,一个懂技术,更懂如何用技术帮你搞钱的RPA老师,别忘了点赞关注我,下期分享更精彩!
往期文章推荐:
用Google Gemini + NotebookLM打造「最强工作流」
普通人掌握 AI 的这 3 个阶段,才是2026拉开差距的关键
END

我是谁?
#影刀RPA 优质开发者成员、高级工程师
#生财有术 抖音图文航海教练
#生财有术 RPA 航海教练

