市场再被点燃!DeepSeekV4“迟到”了,但国产AI等到了
本文深度梳理 DeepSeek 背后的故事:靠毫秒级交易赚钱的量化团队,为什么愿意花 180 天,造一条国产AI全新的路。
全文干货,建议先点赞收藏,转发给身边关注中国科技、AI 发展的朋友。
2026 年 4 月 24 日,DeepSeek V4 终于来了。
万亿参数规模,百万级上下文窗口,首次深度适配昇腾国产芯片 —— 消息一出,国产 GPU 概念股直线拉升,中芯港股大涨 8.3%,华虹飙升近 19%,整个国产 AI 产业链再次被点燃。
但如果你只看到了这些参数和盘面涨幅,就错过了这背后最精彩、也最提气的故事。
过去 180 天里,这家中国最神秘的 AI 公司,被质疑掉队、被唱衰没落,它到底在做什么?
一、”矛盾” 的起点:用毫秒赚钱的人,做了件无期限的事!
要理解 DeepSeek,得先理解它的 “出身”。
深度求索脱胎于国内头部量化基金 —— 幻方量化。量化投资是什么?是以毫秒为单位计算的高频交易,光速都是需要被考虑的成本。能比别人快万分之一秒下单,就是真金白银的利润。
但偏偏,就是这样一个 “快到极致” 的行业,孕育出了一家 “慢到极致” 的 AI 公司。
创始人梁文锋,17 岁考入浙大,2008 年金融危机后开始用机器学习做量化交易,2015 年创立幻方量化,巅峰期管理规模达千亿级别。2019 到 2021 年间,他先后投入近 12 亿元打造 “萤火一号”” 萤火二号 “AI 训练平台,积累了上万张 A100 显卡规模的算力基础设施。
2023 年,梁文锋做了一个让全行业看不懂的决定 —— 创立深度求索,全力投入通用人工智能。
初创期完全依托幻方量化与创始团队自有资金,形成了 “无到期日” 的长期资本池,无需被季度营收、短期商业化绑架,唯一核心 KPI 是 AGI 底层技术的范式突破。
这是它能长期坚守底层研发、拒绝跟风做应用的核心底气。
一个靠 “快” 赚钱的人,选择了最 “慢” 的事业。
这种 “慢” 不是犹豫,而是一种有底气的笃定。幻方量化的利润,给了 DeepSeek 一种其他 AI 创业公司不具备的奢侈品 ——不被资本裹挟的自由。当别的 AI 公司还在为下一轮融资焦虑,为商业化路径发愁时,DeepSeek 可以把全部精力放在技术研发上。
梁文锋自己说过:”如果一定要找一个商业上的理由,它可能是找不到的,因为划不来……主要是好奇心驱动。“
从量化的毫秒级交易,到 AI 的无期限研发 —— 这是一种既矛盾、又合理的浪漫。
二、V4 跳票 180 天:不是掉队,是在 “推倒重来”
2026年初,DeepSeek V4一再跳票。自2025年12月V3.2发布后,这款承载着长期记忆、工程级编程与原生多模态突破的旗舰模型迟迟未上线。
数据不会哄人:平台用户使用率从峰值7.5%掉到3%,官网流量一度下滑近三成,token调用量从42%萎缩到16%。曾经下载破亿、周活逼近9700万的App,在苹果效率榜上只排到第36位。
不少人开始问:那个一年前颠覆行业的DeepSeek,是不是不行了?
多家国产模型供应商人士推断,V4的推迟,核心原因是——全面适配昇腾等国产芯片。
别的厂商,是在高速公路上踩油门加速;DeepSeek干的事,是在一片还没铺好的路面上,硬生生造出一条高速公路,然后再在上面跑车。
英伟达的CUDA生态有十几年积累,算子覆盖、内存管理、通信调度都极其成熟。而昇腾的CANN框架在这些方面仍有差距。这意味着DeepSeek工程团队需要在大量底层细节上进行针对性优化,甚至手动重写关键算子。
一个算子的性能下降,可能影响整条计算链路。这不是修bug,是重建地基。
2026年3月底,DeepSeek经历了成立以来最长的一次服务中断——长达12小时。多名供应商分析,这是V4在进行C端”隐身测试”,冲击更高性能架构时,新旧架构在底层存储聚合层出现了冲突。
与其说是一次模型延迟,不如说是中国顶尖算法团队与国产芯片体系之间的一次深度磨合。
2026年1月,梁文锋亲自署名发表论文,提出Engram条件记忆架构,通过哈希查找替代传统神经网络计算,部署成本有望直降90%。2月,上下文窗口从128K扩展至100万Tokens。同月,DeepSeek-OCR 2发布,采用创新的DeepEncoder V2方法,让AI像人类一样按逻辑顺序”看”图像——不再机械地从左上角扫描到右下角,而是基于语义理解驱动视线流动。
3月,网页端悄然上线了”快速模式”和”专家模式”两种交互方式。业内猜测,这是V4在做隐身测试。
这家公司,在所有人以为它”泯然众人”的时候,完成了一次底层架构级的全面革新。
“2026年4月24日,DeepSeek V4-Pro和V4-Flash正式发布并开源。
模型上下文处理长度扩展至1M,首次增加KV Cache滑窗和压缩算法,大幅减少Attention计算和访存开销,并通过模型架构创新更好地支持了Agent和Coding场景。
本地芯片+本地模型,用国产的卡训练的。
既不至于哪天老美真把卡收紧了,再临时适配国内资源;同时也是为了从最底层,推动国产大模型持续进步,甚至领先。
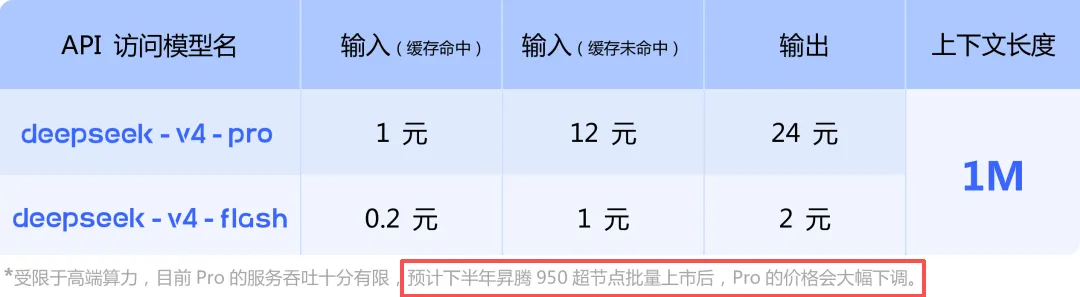
HW计算官方确认:昇腾超节点全系列产品支持DeepSeek V4系列模型。昇腾950通过融合kernel和多流并行技术,实现了V4-Pro模型20ms、V4-Flash模型10ms的低时延推理。
寒W纪也在发布首日完成了”Day 0″适配,适配代码同步开源。
这一天,中国AI产业在摆脱对国外技术生态依赖、推进”去CUDA化”进程中,迈出了重要一步。
回头看,V4的这次”迟到”,恰恰印证了这家公司最根本的底色:
不是为了暂时的领先,而是愿意为了长期的正确,承受短期的不被理解。
从量化的毫秒,到AI的漫长迭代,再到芯片底座的底层重构——DeepSeek用近乎”笨拙”的方式证明了一件事:真正改变世界的技术,从来不是赶出来的。
本文涉及的任何内容及观点仅供参考,不构成投资建议或依据,投资需自主决策、自行承担风险。投资有风险,入市需谨慎!