血洗大模型市场:DeepSeek V4 两天两次降价,优惠再延长:百万 Token 仅 2 分钱!


[!INFO] 文章概览
文章字数:约 3000 字 预计阅读时间:约 9 分钟 内容摘要:DeepSeek V4 发布后 48 小时内连续降价两次,输入缓存命中价格降至首发价 1/10,叠加限时 2.5 折优惠(已延长至 5 月 31 日)后低至 0.025 元/百万 Tokens。本文梳理降价细节、竞品对比、用户反馈,并分析这场价格战对开发者和行业的真实影响。
01 两天降两次,DeepSeek 把 AI 成本打到了地板价
4 月 24 日,DeepSeek 发布 V4 系列模型(V4-Pro 和 V4-Flash),开源权重、支持 1M 超长上下文。发布即开源,这在闭源模型主导的当下,本身就是一个重磅消息。
48 小时内,DeepSeek 连续两次降价,力度之大,堪称行业地震。
第一次(4 月 25 日):V4-Pro 限时 75% 折扣(2.5 折),原定截至 5 月 5 日。
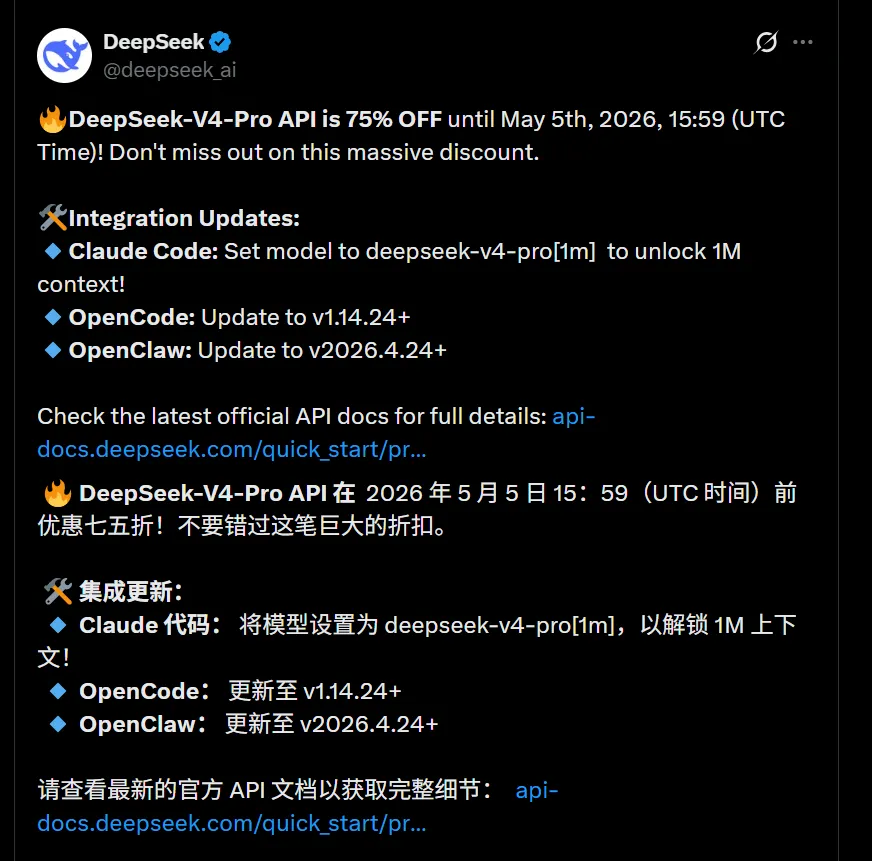
第二次(4 月 26 日):全系模型输入缓存命中价格永久降至首发价的 1/10。
最新进展(4 月 28 日):DeepSeek 宣布 V4-Pro 的 2.5 折优惠期延长至 5 月 31 日,比原计划多送近一个月。

叠加后是什么概念?
|
|
|
|
|
|---|---|---|---|
|
|
¥0.025 / 百万 Tokens |
|
|
|
|
¥0.02 / 百万 Tokens |
|
|
💡 价格说明:V4-Pro 原价为输入缓存命中 ¥0.1/百万 Tokens、缓存未命中 ¥12/百万 Tokens、输出 ¥24/百万 Tokens。2.5 折后分别为 ¥0.025、¥3、¥6。
百万 Tokens 2 分钱,这是全球大模型价格的绝对新低。
对比一下国际主流模型:
-
GPT-5.5 Pro:输入约 ¥210/百万 Tokens(按$30 估算) -
Claude Opus 4.7:输入约 ¥210/百万 Tokens -
Gemini 2.5 Pro:输入约 ¥88/百万 Tokens
DeepSeek V4-Pro 缓存命中价格,约为 GPT-5.5 的 1/8000。
即使不算缓存,标准定价下也是 GPT-5.5 的 1/7、Claude Opus 4.7 的 1/6。
Hacker News 用户 mudkipdev 评论:”This is refreshing right after GPT-5.5’s $30.”(刚从 GPT-5.5 的 30 刀过来,DeepSeek 令人耳目一新。)
用户 woeirua 更直接:”Looks like DeepSeek is just about 2 months behind the leaders now.”(DeepSeek 现在只比全球领先者落后约 2 个月。)
这意味着什么?中小团队也能用顶级模型跑通商业模式了。
02 为什么敢这么降?
DeepSeek 不是慈善机构。敢这么降价,背后有几个关键支撑。
技术创新:KV Cache 显存占用降至 10%
根据开发者分析,V4 在工程层面有多项创新:
-
百万级调用场景下,单 Token 推理算力消耗降至 V3.2 的 27% -
KV Cache 显存占用仅为原来的 10% -
磁盘缓存技术(Context Caching on Disk)默认开启
这意味着什么?同样的硬件,能服务更多请求。
国产算力适配:昇腾 950 下半年放量
IT 之家报道中提到一个关键信息:
官方确认:受限于高端算力,目前 Pro 版服务吞吐有限。预计下半年昇腾 950 超节点批量上市后,Pro 价格还将大幅下调。
华为、寒武纪、摩尔线程等国产算力厂商已在 Day-0 完成适配。华为实现 V4 Pro 约 20ms、V4 Flash 约 10ms 低时延推理。
换句话说,现在的价格可能还不是底价。
战略意图:抢开发者、抢企业用户
上海财经大学胡延平教授评论:
DeepSeek 意在延揽企业用户、开发者和 Agent 用户。
36 氪报道中提到,4 月 25 日 V4-Pro 调用量 136 亿 Token,较前日增长近 4 倍;4 月 26 日 V4-Flash 调用量 814 亿 Token,环比增长**62.2%**。
低价换市场,这招很有效。
03 全球开发者沸腾了
海外社区:震惊 + 点赞
Reddit r/DeepSeek 官方公告帖下,用户评论:”That’s crazy!”(太疯狂了)
有用户特意指出:输入缓存命中降价是永久的,不同于昨日的限时折扣,这意味着长期成本可以大幅降低。
Hacker News 讨论更热烈,正面评价占主导:
-
用户 mudkipdev:”Looks like DeepSeek is just about 2 months behind the leaders now.”(DeepSeek 现在只比全球领先者落后约 2 个月) -
用户 daemonologist:”1.47 / M i n p u t , -
用户 creamyhorror:关注到 V4-Pro-Max 在标准推理基准上超越 GPT-5.2 和 Gemini-3.0-Pro
一位海外开发者在 Reddit 上分享:”通过第三方免费试用渠道使用 V4-Pro,初期体验不佳,数小时后恢复正常。”——这反而说明社区需求旺盛,团队在快速修复。
国内社区:理性看好
知乎上有用户分析:
感觉主要是揭示了 coding plan 的实际成本。DeepSeek 的定价大家都知道没什么水分,而且他模型结构也是最省钱的,所以低于 DeepSeek 定价的部分必然就是补贴。
言下之意:DeepSeek 把真实成本摊开了,其他家的定价有泡沫。
也有开发者关注服务稳定性,这恰恰说明市场对 DeepSeek 的需求非常旺盛。官方已明确表示,下半年昇腾 950 超节点批量上市后,服务吞吐能力将大幅提升。
04 未来展望:更大的惊喜在后面
国产算力加持,成本还有下降空间
DeepSeek 官方在公告中明确表示:
受限于高端算力,目前 Pro 版服务吞吐有限。预计下半年昇腾 950 超节点批量上市后,Pro 价格还将大幅下调。
IT 之家报道中提到,华为、寒武纪、摩尔线程等国产算力厂商已在 Day-0 完成适配。华为实现 V4 Pro 约 20ms、V4 Flash 约 10ms 低时延推理。
这意味着什么?现在的价格可能还不是底价。
21 世纪经济报道中提到一个重磅消息:
腾讯和阿里正在接触 DeepSeek 融资事宜,估值或超 200 亿美元。
如果这笔融资落地,DeepSeek 的算力储备和抗风险能力将大幅提升,长期低价策略更有保障。
模型能力持续进化
DeepSeek 自承:
V4 代码交付质量接近 Claude Opus 4.6 非思考模式,但与 Opus 4.6 思考模式仍有差距。
但别忘了,V4 是开源模型(MIT 许可),社区贡献和迭代速度可能远超预期。
另外,V4 目前不支持多模态,但官方技术报告确认正在开发中。一旦多模态上线,V4 将成为全能型选手。
对于只需要文本推理的场景,V4 已经足够强大。华泰证券分析报告指出:
长上下文成本下降后,复杂 Agent、多文档分析、长周期任务等场景可用性大幅提升。
05 对开发者意味着什么?
利好:长上下文场景成本大降
如果你有以下场景,DeepSeek V4 可能是目前性价比最高的选择:
-
批量处理文档(缓存命中率高) -
多轮对话系统(系统 prompt 可缓存) -
长周期 Agent 任务(上下文复用频繁) -
RAG 检索增强生成(知识库可缓存)
华泰证券分析报告指出:
长上下文成本下降后,复杂 Agent、多文档分析、长周期任务等场景可用性大幅提升。
机会:国产模型 + 国产算力的组合拳
21 世纪经济报道中提到:
腾讯和阿里正在接触 DeepSeek 融资事宜,估值或超 200 亿美元。
如果这笔融资落地,DeepSeek 的算力储备和抗风险能力会更强。
对于开发者来说,这意味着:
-
服务稳定性将大幅提升 -
长期低价策略更有保障 -
生态工具链可能更完善
建议:尽早测试,抢占先机
注意,V4-Pro 的 75% 折扣(2.5 折)已延长至 5 月 31 日,比原计划多送近一个月。缓存命中 1/10 是永久降价。
优惠延期意味着什么?
这说明 DeepSeek 对 V4-Pro 的推广力度超出预期。一般来说,限时折扣到期不续是常态,但 DeepSeek 选择延长优惠期,可能有几个原因:
-
市场反响热烈:4 月 25 日 V4-Pro 调用量 136 亿 Token,较前日增长近 4 倍,需求旺盛 -
产能爬坡中:官方承认”受限于高端算力,目前 Pro 版服务吞吐有限”,延期可以给产能调整留出时间 -
抢用户窗口期:5 月是传统淡季,延长优惠可以吸引更多开发者在淡季完成接入测试
对于开发者来说,这意味着测试窗口更充裕了,不用急着在 5 月 5 日前赶工。
建议:做成本测算时,按标准定价(缓存命中 1/10)计算,限时折扣当它是 bonus。但现在 bonus 多送了近一个月,可以更从容地测试和优化。
关键是尽早接入测试,趁现在竞争还没那么激烈,先跑通你的业务场景。
06 行业影响:AI 普惠时代加速到来
DeepSeek 降价后,资本市场已有反应:
-
MiniMax 股价跌 3.54% -
智谱股价跌 2.19%
这看似是冲击,实则是行业洗牌的信号。
花旗研报指出:
开源与闭源模型两极分化加剧,中间玩家最难。
换句话说:要么像 DeepSeek 一样把成本压到极致,要么像 GPT-5.5 一样做到性能绝对领先。夹在中间的,最难受。
高盛分析报告认为:
V4 核心意义在于以更低成本支持更复杂智能体应用落地。
这才是关键:价格战不是目的,让复杂 Agent 应用真正落地才是目的。
中信建投分析:
V4 与 GPT-5.5 同期发布,前者将百万上下文推理成本降至极低水平,为 Agent 应用铺平道路。
AI 普惠时代正在加速到来。
07 总结:AI 普惠时代,别错过这班车
DeepSeek 这波降价,对开发者是实打实的利好。
百万 Tokens 2 分钱,这不是噱头,这是实打实的成本革命。
如果你的应用场景能充分利用缓存命中率,那 DeepSeek V4 可能是目前性价比最高的选择。
最后给三个建议:
-
实测缓存命中率:别只看定价表,实际跑一下你的场景,看缓存命中率能到多少 -
关注国产算力进展:昇腾 950 下半年放量后,成本可能还会降 -
尽早接入测试:趁现在竞争还没那么激烈,先跑通你的业务场景
[!NOTE] 总结
适合人群:
需要长上下文、高缓存命中率的开发者 对成本敏感的中小企业 想尝试国产大模型的团队 核心优势:
全球最低价格(缓存命中场景) 开源权重(MIT 许可) 1M 超长上下文支持 国产算力持续加持 一句话:价格很香,但别只看价格。关键不是工具本身,而是你能用它创造出什么。
参考资料
-
DeepSeek API 官方定价页 – https://api-docs.deepseek.com/quick_start/pricing -
DeepSeek V4 发布公告 – https://api-docs.deepseek.com/news/news260424 -
DeepSeek Context Caching 文档 – https://api-docs.deepseek.com/guides/kv_cache -
IT 之家:DeepSeek V4-Pro 限时 2.5 折 – https://www.ithome.com/0/943/528.htm -
新浪财经:DeepSeek-V4 价格暴降 90% – https://finance.sina.cn/stock/jdts/2026-04-27/detail-inhvwwms7962626.d.html -
36 :DeepSeek 两天两次降价 – https://m.36kr.com/p/3784523493202952 -
证券时报:DeepSeek 击穿大模型底价 – https://www.stcn.com/article/detail/3821826.html -
21 世纪经济报道:DeepSeek 击穿大模型底价 – https://www.21jingji.com/article/20260428/7587bba573cba50a7eede34369f7bbdf.html -
Reuters: China’s DeepSeek slashes prices for new AI model – https://kfgo.com/2026/04/27/chinas-deepseek-slashes-prices-for-new-ai-model/ -
Reddit r/DeepSeek 官方公告帖 – https://www.reddit.com/r/DeepSeek/comments/1sw6y3c/ -
Hacker News V4 技术报告讨论 – https://news.ycombinator.com/item?id=47884933