黄仁勋说中国市场归零,马斯克的GPU在摸鱼:AI军备竞赛的另一面
五一假期的科技圈,两条新闻撞在了一起。
五一期间,一段黄仁勋的采访在中文科技媒体上刷了屏。
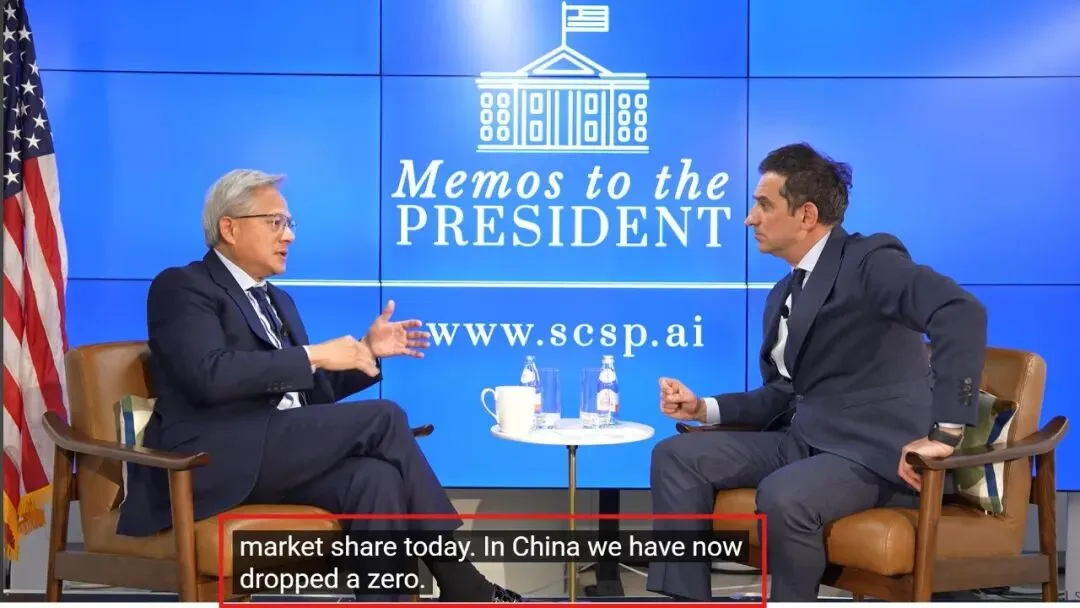
采访来自SCSP播客《Memos to the President》。黄仁勋在节目里说了一句话:
“在中国,我们现在已降为零。”
他说的是英伟达在中国AI芯片市场的份额。他用了一个词——“适得其反”——来形容美国的出口管制政策。
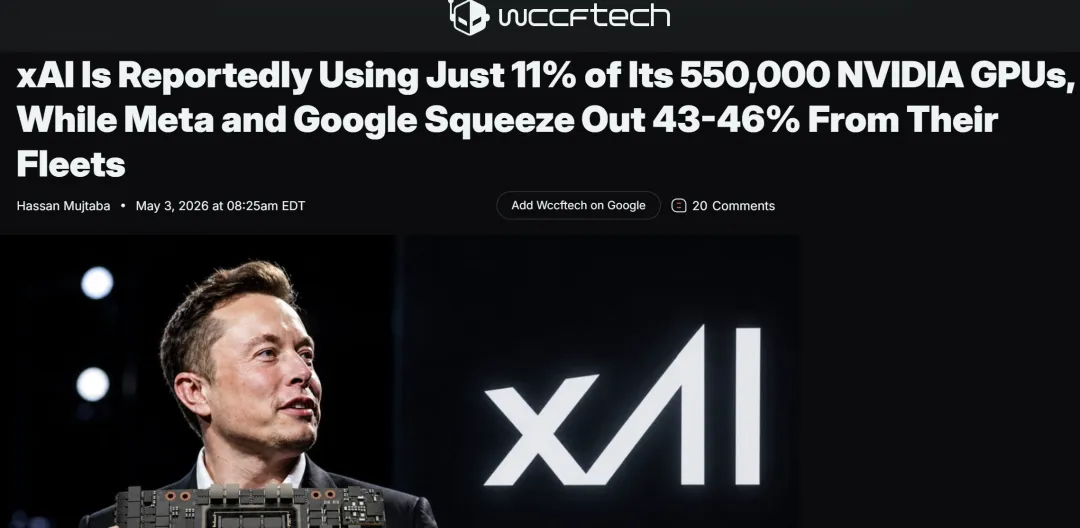
同一时间,《The Information》爆出另一件事:
马斯克的xAI,坐拥全球最大的GPU集群——约55万张英伟达GPU。但模型浮点运算利用率,只有11%。
一条是”卖不出去了”。
一条是”买了用不起来”。
放在一起看,比单独看哪一条都有意思。
55万张卡,只跑出了6万张的效果
先解释一个概念。
MFU(模型浮点运算利用率)不是任务管理器里那个GPU占用率。它衡量的是:显卡理论算力峰值,实际有多少用在了模型训练上。
11%意味着什么?
55万张卡的理论算力,实际产出的训练吞吐量,只相当于约6万张卡。剩下89%的算力,不是在计算——是在等。
等数据搬运。等隔壁机柜传参数。等上一次同步完成。
做一个对比:
|
|
|
|---|---|
| xAI |
|
|
|
|
|
|
|
|
|
|
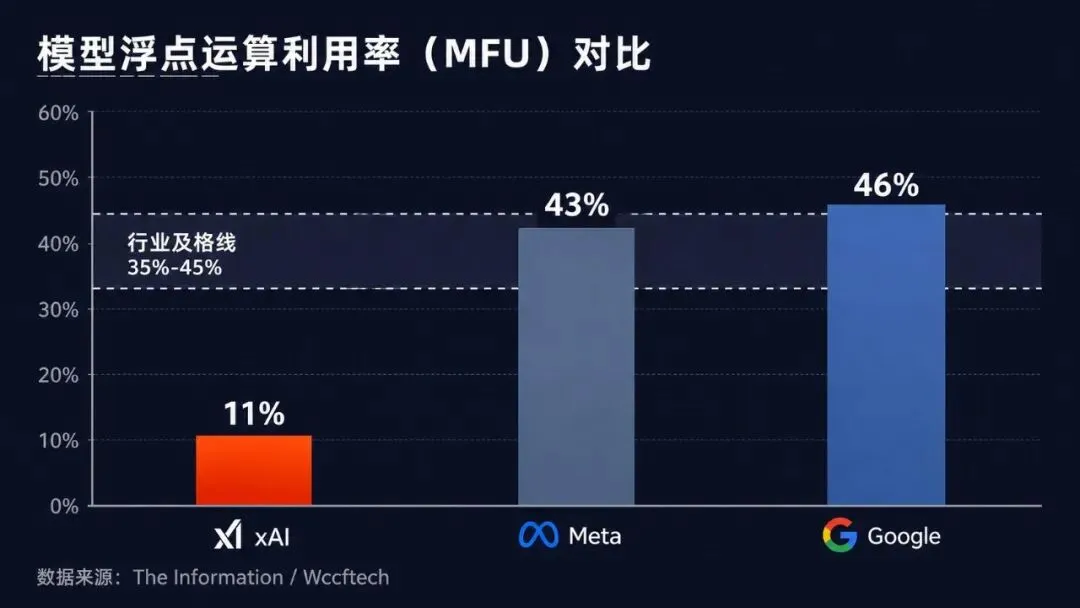
不是差一点。是差了一个数量级。
说个背景。
xAI建集群的速度是行业传奇。
孟菲斯Colossus超算,从开工到上线,122天。 常规数据中心需要18-24个月。黄仁勋自己都说过:这”通常需要四年”。
快的代价,是软件没跟上。
Colossus的硬件部署是极限操作。分布式训练框架、并行策略、故障恢复机制——这些”软”的东西,加人没用。得熬时间,攒经验。
尤其是当集群从千卡级扩展到十万卡级,跨节点通信延迟会指数级放大。你的卡再快,也要等隔壁机柜把数据传过来。
NVIDIA自己的Megatron-LM基准测试早有印证:在6144张H100集群上,弱扩展场景MFU约47%;在4608卡的强扩展场景中,MFU约42%。通信开销始终是首要瓶颈。
xAI从1万张扩到55万张,这个问题放大了几十倍。
“硬件优先”,这次不太灵
熟悉马斯克的人对这个套路不陌生:先造出来,再优化。
特斯拉超级工厂。SpaceX火箭回收。星链卫星网络。都是先把物理资产铺下去,边跑边迭代。
制造业和航天领域,这个打法屡试不爽。
但在AI领域,情况不太一样。
制造业的瓶颈通常在硬件端——产线不够、良率太低。AI的瓶颈在软件端——训练框架、并行策略、数据处理管线。 硬件可以加速硬件,但硬件加速不了软件工程。
11%只是其中一件事。
时间轴拉长,问题不止这一个:
今年2月。 SpaceX以全股票交易收购xAI,合并估值1.25万亿美元——人类史上最大并购案。
一个月后。 xAI的11位联合创始人,全部离职。
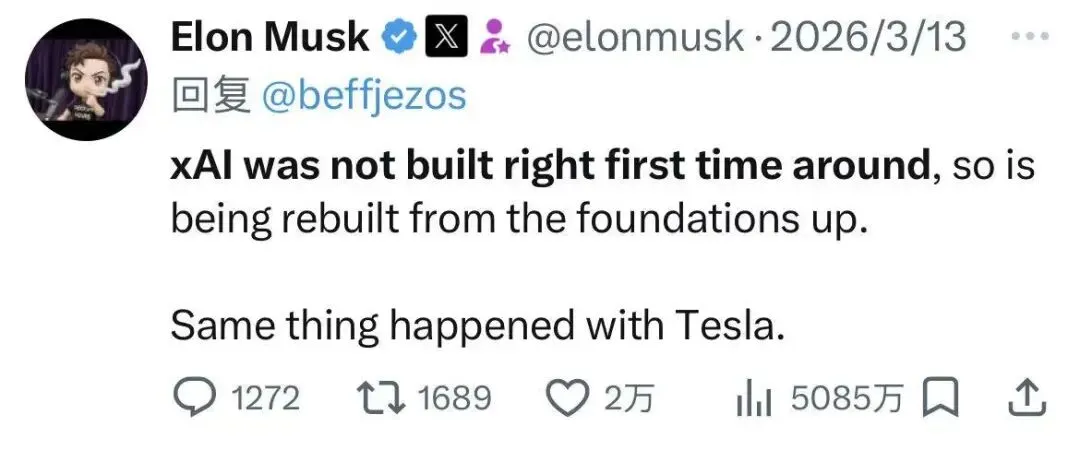
马斯克自己在X上发帖承认:
“xAI was not built right first time around, so is being rebuilt from the foundations up.”(”xAI第一次没有建好,要从底层重建。”)
还是3月。 Cursor的两名核心工程师——Andrew Milich和Jason Ginsberg——跳槽到xAI。不是xAI的人出去创业,是反过来,从创业公司挖人补自己的编程工具短板。
4月21日。 SpaceX宣布获得以600亿美元收购Cursor的选择权。不收购?那也得付100亿美元”合作费”。Cursor自己估值已超500亿——花超过一家独角兽的钱,补xAI编程能力的坑。
4月15日。 马斯克确认特斯拉AI 5芯片流片成功,2027年量产。
再往前,3月。 他宣布启动TERAFAB——特斯拉、SpaceX、xAI联合英特尔,”人类史上最大芯片制造项目”,目标年产1太瓦算力,约等于当前全球AI芯片总产出的50倍。

超算、模型、编程工具、自研芯片——摊子越铺越大。
但最核心的模型训练效率,11%。
规模不等于能力。
黄仁勋的”0%”,是同一枚硬币的另一面
回到开头黄仁勋那句话。
2024年,英伟达在中国AI芯片市场还有约66%的份额。
华尔街投行Bernstein年初预测,这个数字会跌到约8%。
黄仁勋在节目里的原话是:降到了零。
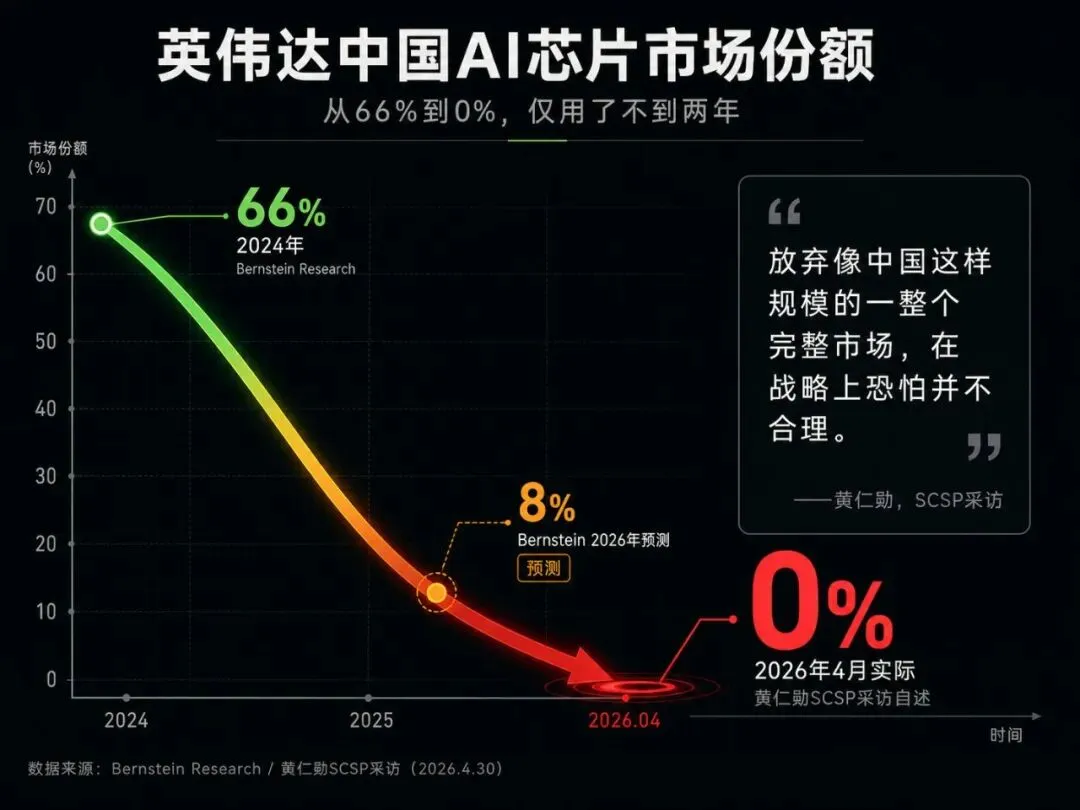
比华尔街最悲观的预期还快。
美国的逻辑很简单:卡住先进芯片,就能卡住中国的AI。
但现实走的是另一条路。
华为昇腾950,芯片采购价只有英伟达同类产品的四分之一。单卡算力,比对华特供版高出2.87倍。
4月24日,DeepSeek V4发布。这是第一个把华为昇腾与英伟达GPU并列写入硬件验证清单的模型——八大国产芯片,全部Day 0适配。

黄仁勋的总结很直白——视频里是这么说的:
“放弃像中国这样规模的一整个完整市场,在战略上恐怕并不合理。我认为这在很大程度上已经产生了反效果。”
他承认,除了CUDA生态这道最后的壁垒,中国在低成本能源、数理人才、AI研究员数量上,依然是”最强劲的竞争对手”。
还有一个对比。
当马斯克55万张GPU只跑出11%利用率的时候——
DeepSeek V4的API输入缓存价,已经降到了GPT-5.5 Pro的七百分之一。
一边是堆卡用不起来。一边是没卡硬跑出路。
AI竞赛的下半场,不再是比谁卡多
过去两年,AI军备竞赛的叙事很简单:谁卡多,谁赢。
英伟达市值逼近5万亿。OpenAI融了1220亿美元,史上最大私募融资。xAI光速建超算、微软亚马逊谷歌押注Anthropic——全在抢算力。
但最近这段时间,这个叙事裂开了。
有卡不等于有用。
xAI的11%说明,十万卡级集群的软件工程挑战,不是”马斯克速度”能解决的。工程可以加速,软件架构的复杂度有底线。
卡脖子不一定能卡住。
英伟达中国份额,66%到0%,不到两年。同期国产芯片从”能用”走到了”好用”。黄仁勋的挫败感不是装的——生态壁垒在松动。
效率在重新定义竞争。
Meta 43%、Google 46%的利用率,说明软件工程才是下一阶段的胜负手。DeepSeek V4用不到百分之一的成本逼近顶级模型——算法效率,可以部分抵消算力差距。
回头看马斯克的AI布局——
超算(Colossus)。模型(Grok)。产品(Cursor)。芯片(TeraFab)。算力(特斯拉Dojo)。
每一项,都指向同一个逻辑:用规模碾过去。
但当55万张GPU只有11%在真正工作的时候。
当xAI创始人集体出走的时候。
当你要花600亿买编程工具来补课的时候。
规模,可能不是答案。
至少不全是。
数据来源:The Information、SCSP《Memos to the President》第31期、Bernstein Research、NVIDIA Megatron-LM官方基准、CNBC、IT之家、澎湃新闻、Wccftech、Tom’s Hardware、36氪、太平洋科技、中国日报。