如果 K 线是一种市场语言,AI 写出来的未来该怎么验证?
如果只把 Kronos 看成一个“AI 画 K 线”的项目,很容易错过它真正有意思的地方。语言模型可以续写文字,K 线能不能也被切成 token,变成一种可以续写的市场语言?
Kronos 做的事情,是先给市场造一套机器词典,把连续的价格、成交量状态压成 token,再用 Transformer 一步步生成后面的市场状态。
打开 demo 时,最先看到的就是这样一张图:左边是已经发生的 K 线,右边是模型生成的未来区间。
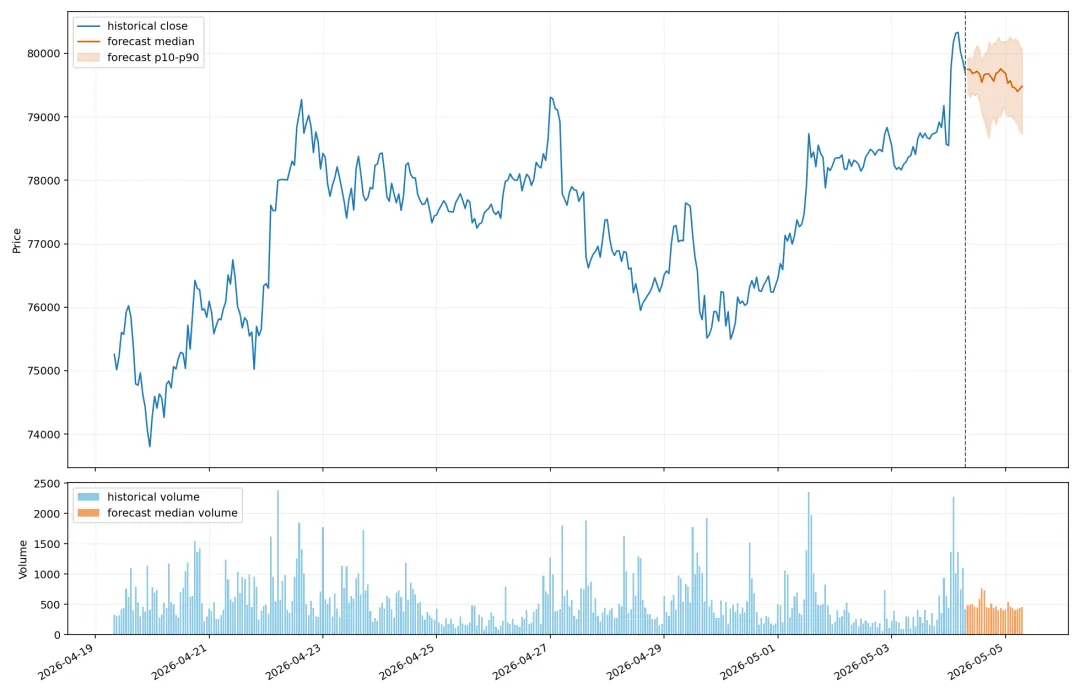
图 1|这张图适合作为入口:左边是历史价格,右边是模型生成的未来区间。后面的实验要问的是:真实价格后来有没有落进这片区间。
如果模型只输出一条线,我们当然可以问它准不准。可 Kronos 输出的是一组路径:同一段历史,可以被续写出很多种可能。
这篇文章就沿着这个问题往下走:Kronos 怎么把 K 线变成一种机器可续写的市场语言;把时间倒回去 200 次之后,真实价格有多少次会落进 AI 当时给出的范围。
01 给 K 线造词典
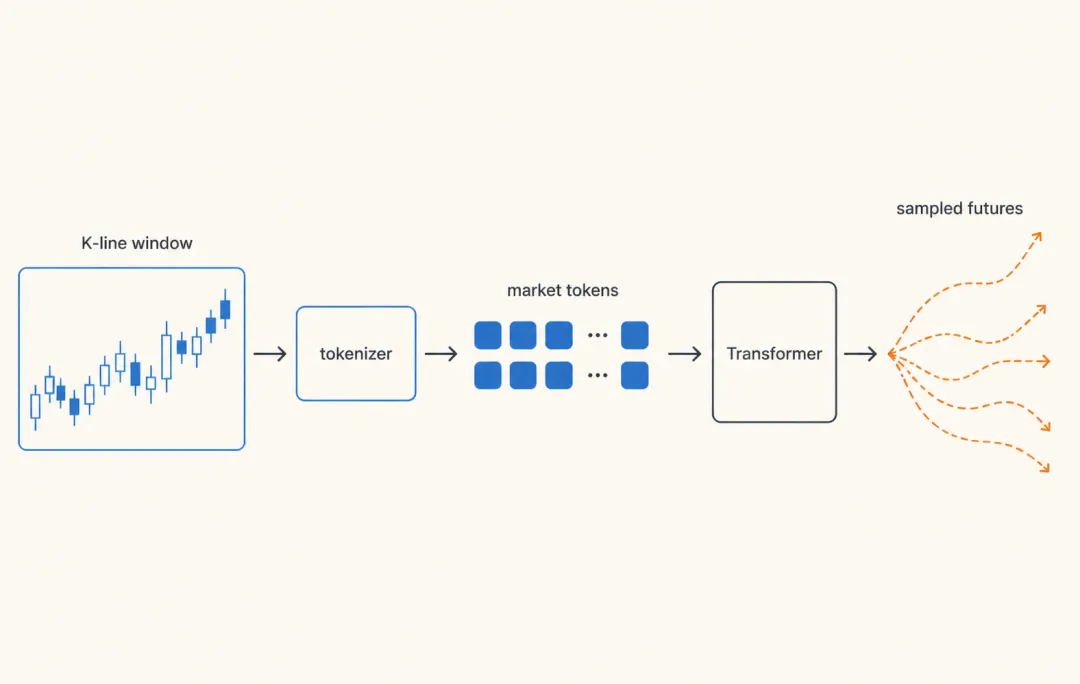
图 2|Kronos 的核心路径:先把历史 K 线压成 market tokens,再用 Transformer 生成多条 sampled futures。
K 线本来是连续数值:open、high、low、close、volume、amount。语言模型更习惯处理 token,也就是一个个离散符号。Kronos 先训练 tokenizer,把连续的市场状态压缩成机器可用的 token。
“离散化” 就是:价格和成交量原本有无数种小数变化,模型先把它们归到有限个状态里。就像人说话时通常不会记录每个发音细节,会用有限的字词把意思说出来。
这里藏着一个大胆假设:K 线里存在某种可以被压缩、复用、续写的结构。
这个假设不能直接当真。Tokenization 可以压缩噪音,也可能只是把噪音包装得更像语言。
市场像不像语言,不靠比喻成立,靠回放里的真实价格来检查。
论文里的 tokenizer 还把 token 拆成 coarse 和 fine 两层。coarse 可以理解成较粗的市场状态桶,fine 负责桶里的残差细节。coarse 不等于简单的上涨或下跌,它更像模型学出来的一组市场状态编号,人类未必能直接读懂。
Kronos 没有把“头肩顶”“三角整理”这类人工形态塞进去。它让模型自己学习市场状态如何被编码。可以把它想成一套机器内部的市场词典,只是这本词典不是写给人看的。
02 续写市场语言
有了 token,下一步就很像大模型。
Kronos 使用 decoder-only Transformer,一步步预测下一个市场 token。生成下一步后,再把这一步放回上下文继续生成。这个过程叫 autoregressive,可以理解成“边写边往下续”。
给它过去 360 根 1 小时 K 线,它会先把历史变成 token 序列,再生成未来 24 小时的 token,并解码回价格路径。
同一段历史,采样一次得到一条未来路径;采样 30 次,就得到 30 条可能路径。对未来第 1 小时,我们有 30 个预测价格;对未来第 2 小时,也有 30 个预测价格;一直到第 24 小时。把每个未来小时的这些价格从低到高排,就能整理出 p10、p50、p90 三条分位线。
p10 是偏低的那条线:在同一个未来时点,大约 10% 的预测价格低于它。p50 是中位线:一半价格在它上面,一半在它下面。p90 是偏高的那条线:大约 90% 的预测价格低于它。p10 到 p90 之间,就是这组生成路径形成的主要范围。
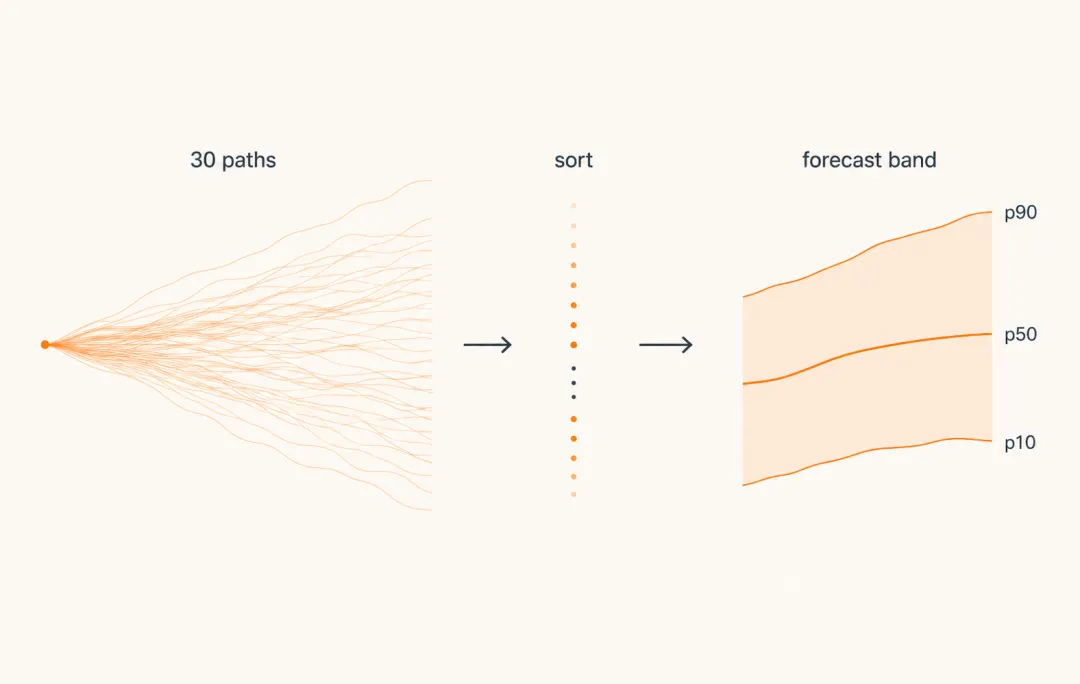
图 3|同一段历史可以采样出多条路径。把每个未来时点的价格排序,就能得到 p10、p50、p90 形成的经验区间。
所以 p50 不一定是某一条真实采样路径。它更像每个未来时点的“中间位置”连成的线。p10-p90 也不是模型承诺的置信区间;更准确地说,它是这组生成路径在每个时点展开后的范围。
橙色区域代表的,是多条生成路径摊开之后留下的一片范围。
p50 很容易被看成“预测线”。但中位线只是摘要。真正该看的,是整组路径形成的分布。
这也是 Kronos 比单点预测更值得讨论的地方。它给出的不是一个价格点;它给出的是一组可能的市场延续,天然适合用 coverage 和 calibration 检查。
coverage 指真实未来落在预测区间里的比例。calibration 关心预测分布和真实结果之间是否贴合。如果模型经常给出一个范围,而真实价格经常落在里面,我们才有资格继续讨论它学到了什么。
03 和传统量化的差别
传统量化通常从任务开始:预测下一小时收益、预测波动、给资产排序,或者判断事件后的价格反应。题目定好之后,再设计特征、定义目标、训练模型,进入回测、成本、风控和执行。
Kronos 的起点不同。它先学习市场状态表示,再用这种表示生成未来路径,或者服务下游任务。传统量化更像 task-first,Kronos 更像 representation-first。
这个差别很大,但不要把它理解成新模型天然更接近交易。传统量化在目标、风险、成本和回测纪律上反而更清楚。Kronos 提供的是另一种看市场序列的方式:把 K 线当成可以编码、续写、多路径采样的市场语言。
04 为什么要自己复现
官方 demo 是很好的入口。它让你看到:给模型最近 360 小时的 BTCUSDT 1h K 线,它可以生成未来 24 小时的概率路径。
我们读完论文、repo、公开 demo 和 model card 之后,把公开模型跑了起来。主实验用 NeoQuasar/Kronos-mini 和 NeoQuasar/Kronos-Tokenizer-2k。mini 的理由很朴素:速度更快,在我们的小样本检查里也更实用。
基础复现跑通后,我们没有停在“生成一张类似 demo 的图”。真正要做的,是把它改造成可以回放的实验:每次预测都留下 CSV、图、交互页面和 summary 指标。
问题也从“看一次未来”,变成了“把时间倒回去 200 次”。
05 把时间倒回去 200 次
实验设计很简单。
我们选 BTCUSDT 的 1 小时 K 线。每次测试,都找一个历史时点当 anchor。模型只能看到这个 anchor 之前的 360 根 K 线,然后生成未来 24 小时。
关键在于:对我们来说,那个未来已经发生过。
所以每个 anchor 都是一场小型时间回放。模型站在过去,只能看过去;我们站在现在,把它生成的未来和后来真实发生的价格逐小时对齐。
本次实验设置:
-
市场:BTCUSDT -
周期:1h -
历史窗口:360 bars -
预测长度:24 bars -
anchor 数量:200 -
每次采样路径:30 -
temperature:1.1 -
模型: NeoQuasar/Kronos-mini -
tokenizer: NeoQuasar/Kronos-Tokenizer-2k
每个 anchor 上,模型生成 30 条未来路径。我们把这些路径整理成 p10、p50、p90。p10 到 p90 之间,就是这次实验里模型给出的主要预测区间。
这里 p10-p90 不是严格统计意义上的置信区间。它来自有限采样,也受到 temperature、路径数量、模型和市场状态影响。叫它 “生成路径形成的经验区间” 更准确。
这次实验不碰收益曲线、仓位、滑点和手续费。它只检查一个更基础的问题:真实价格后来有没有落进模型当时给出的范围里。
这就是 forecast calibration experiment。
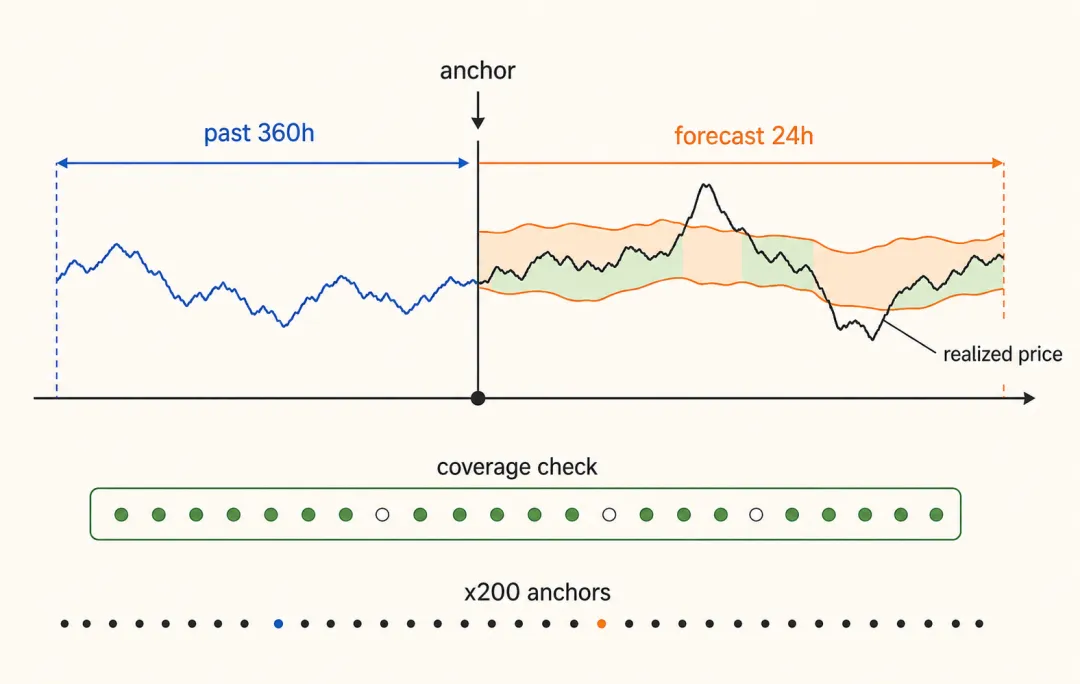
图 4|每个 anchor 只给模型过去 360 小时,再把生成的未来 24 小时和后来真实价格对齐;重复 200 次,看覆盖情况。
模型每次都站在过去;真实价格,是后来才拿回来对齐的。
06 结果:区间有没有覆盖现实?
最终这组实验跑了 200 个 anchor,每个 anchor 30 条路径。
- Direction hit|60.5%
:p50 对 24 小时后涨跌方向的判断,约 6 成与真实方向一致。 - Final p10-p90 hit|72.0%
:在 24 小时最终点,真实价格有 72% 落在 p10-p90 区间。 - Mean path p10-p90 coverage|73.8%
:逐小时看,真实价格约 73.8% 的时间落在 p10-p90 区间。 - Mean final pct error|1.08%
:p50 最终点与真实最终价格的平均偏差约 1.08%。 - Median final pct error|1.01%
:p50 最终点与真实最终价格的中位偏差约 1.01%。
这组数字里,60.5% 最容易被误读。它看起来像一个可以直接行动的指标,但这里没有成本、仓位和风控,也没有和简单基线比较。
我会把注意力放在 72.0% 和 73.8% 上。
在这段 BTCUSDT 1h 样本里,真实价格在相当一部分历史回放中落进了模型生成的 p10-p90 区间。这说明生成路径有一定 coverage。换句话说,这些橙色区间并非完全乱画。
这组数字的含义需要收窄。72% 不意味着模型“看见未来”。73.8% 也不意味着区间已经充分校准。它只说明:在这个很窄的样本切片里,Kronos 生成的概率区间和后来真实价格之间,有值得继续检查的关系。
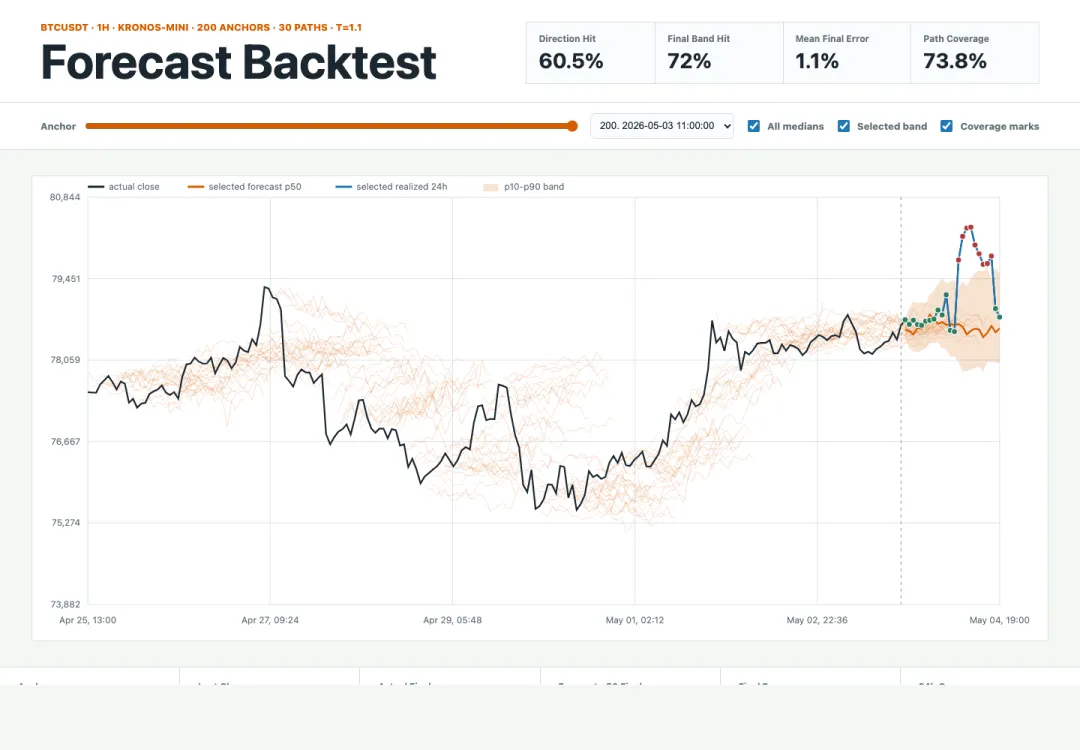
图 5|这张图把 200 次回放压到一个界面里:上方是汇总指标,下方是一个 anchor 上的真实价格、p50 和 p10-p90 区间。
07 IC / RankIC,和我们看的 coverage
读 Kronos 论文时,这里容易混淆。
论文讨论 test-time scaling,重点看 IC 和 RankIC。IC 可以理解为预测分数和未来结果的相关性;RankIC 看预测排序和真实排序之间的相关性。它们常用于量化研究,尤其是横截面预测和排序问题。
论文的思路是:多采样后做平均,让预测更稳定,从而改善 IC / RankIC。
我们这次换了一个问题。我们把多次采样得到的路径拿来形成 p10/p50/p90 区间,再问真实价格有没有落进去。论文关心平均预测和未来结果的相关性;我们关心生成分布对现实的覆盖。
两者都和多采样有关,但回答的问题不同。
Kronos 确实能生成未来路径;但这次实验没有复刻论文里的所有 benchmark,也没有证明它在所有市场上都有同样表现。我们只是抓住最直观的一面:如果它能生成很多条未来,就把这些未来当成分布来检验。
08 边界在哪里
这次实验最重要的价值,是把一张预测图变成一个可以检查的问题。边界也必须清楚。
第一,样本很窄。我们只看了 BTCUSDT、1h、一个近期窗口。换成别的资产、周期或市场状态,结果都可能变化。
第二,还没有简单基线。比如“价格不变”“延续最近趋势”“历史波动率区间”这类朴素方法,都应该拿来比较。没有基线,很多数字只能说有意思,不能说强。
第三,这还够不上完整交易评估。它没有交易成本、滑点、仓位、风控和 PnL。把 forecast calibration 直接翻译成交易结论,是最容易犯的错误。
第四,失败样本也要看。覆盖率不错,不代表每次都温和失败。风险常常藏在出界时刻:区间太窄、方向错得很坚决,或者遇到突发波动时整体滞后。
所以这里更合适的位置,是模型复现和离线研究。它帮助我们理解“市场语言模型”该怎么测,但还不能被当成任何执行依据。
09 如果 K 线真是一种市场语言
我喜欢“市场语言”这个说法,但它不能被浪漫化。
语言有语法,有上下文,有可复用结构。市场也有结构,但这些结构会变、会失效、会被交易者挤压,也会被新闻和流动性打断。把 K 线变成 token,只是打开一种建模方式;它没有消除市场本身的不确定性。
Kronos 给我的启发,是把金融预测从“猜一条线”推向“生成一组可检验的假设”。
Kronos 更像一种提问方式:把“预测”拆成可以被历史反复检查的东西。
当 AI 写出一段未来,我们不该急着相信它,也不该因为它会犯错就把它扔掉。更好的做法,是把这些可能性放回历史里,一次次问:
真实价格有没有落在它认为合理的范围内?
它在哪些时候覆盖得好?
它在哪些时候失败?
下一步该补的,是更多资产、更长周期、简单基线和失败样本拆解。等这些都跑完,再谈更复杂的用途。
AI 生成的未来不能被当成未来本身。它更像一组假设。真正有价值的工作,是把这些假设放回历史里,检查真实价格有没有落进范围,以及它在哪些时候没有。
本文是一次模型复现和 forecast calibration 实验记录,不构成任何投资或交易建议。