Agent Skills:摒弃营销,看些真正本质的东西
最近后台收到一些兄弟的留言,说skills更新了,希望我赶快跟上。也有人说:LLM Agent 的概念刚看完,最近又到处在讲 Agent skills,感觉隔一段时间就冒出来一个新东西,根本学不过来。
其实别被那些公司的新名词骗了,也别被那些营销号的话术骗了。天天一个颠覆性的技术,按他们那说法人类早就该机械飞升了。咱们从工程和技术的角度来拆解一下就会发现skills 根本不是什么横空出世的全新技术。从工程架构的角度看,skills 其实就是把 Agent 的能力组织方式进行了一次工程化的规范与封装。
这篇文章我想讲三件事

-
skills 到底是什么?
-
为什么将能力封装为 skills 后,Agent 的上下文表现和执行稳定性会显著提升?
-
如果模型本身不支持 Skill,怎么手写一个最小可运行的 Skill runtime。
在进入底层逻辑之前,我们先把一件事说清楚:Skill 不是横空出世的新能力,而是一种工程化的能力组织方式。
咱们长话短说。就像我们之前的两个文章梳理的【上下文】【Agent功能梳理】。
读完Google这份Agent白皮书,我才理解了什么是Context Engineering
AI 应用开发指南:一文带你快速入门 Prompt、RAG、Function Calling、MCP 与 Agent
从 Prompt 调优到 RAG,再到给模型外接各类 Tools,以及 MCP,折腾来折腾去,本质上都是在搞拼装上下文,目的只有一个:让 Agent 能真正干点活,而且行为尽量可控。
那这会儿又冒出来的 skills 是干嘛的?它解决的是一个更具体的工程痛点。以前让 Agent 做复杂任务,往往得靠一长串的系统提示词去临时规定步骤。而 skills 的思路是,直接把“这事儿到底怎么做”的代码逻辑、接口依赖,固化成一个标准化的、随拿随用的能力单元。这是什么?这不就是我们软件工程里学到的可复用、可迁移嘛?以及一个东西可以标准化、产品化的重要指标,可控,可复现。
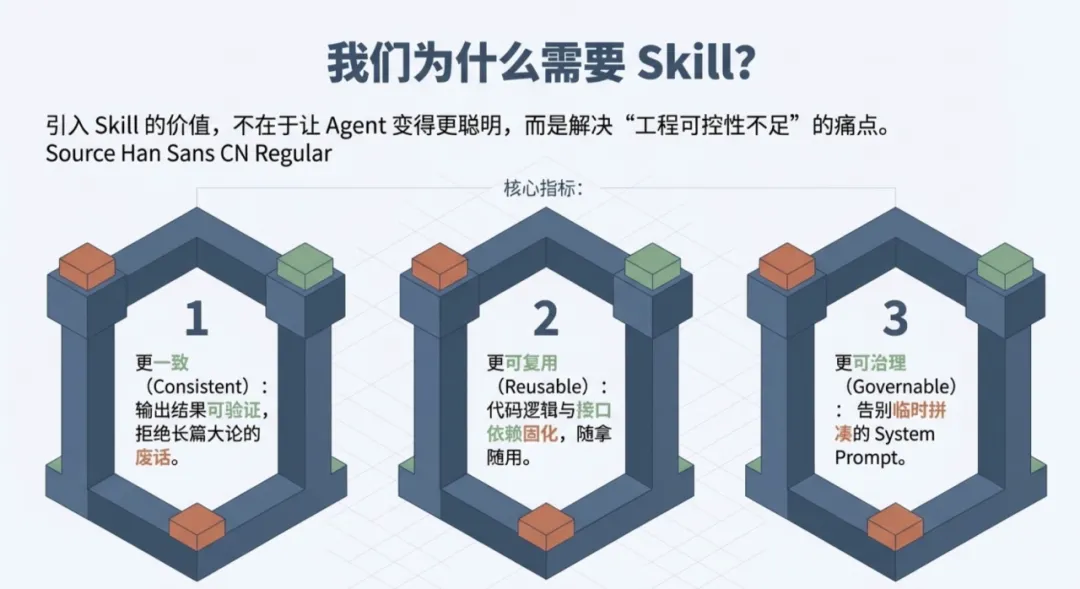
所以引入 Skills 的价值,不在于能让 Agent 变得更聪明或者能力更强,它的核心只有三个词:更一致、更可复用、更可治理也就是更符合工程。
背景交代到这,旧东西咱们不废话,需要了解直接点击上面的链接,咱们这篇文章直接往下看最核心的底层逻辑。
一、
Skills 是什么
1.1 Skills的定义和构成
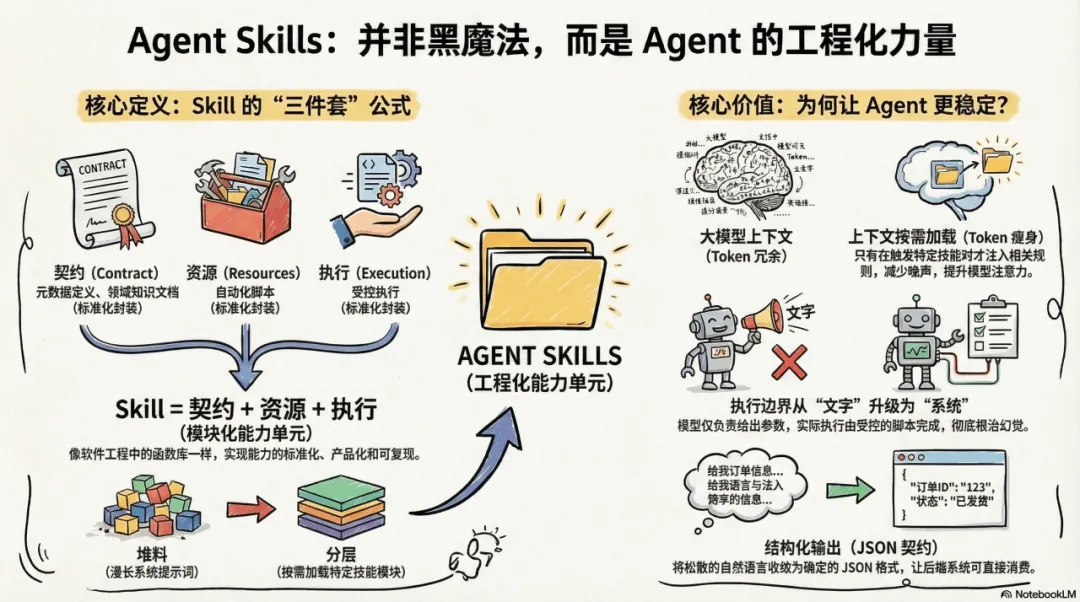
很多人刚一看到Skills这个词,以为这个东西是什么黑魔法。其实没必要,从实现形态上看,Skill 往往会落成一个本地目录;但从工程本质上看,Skill 是一组被标准化组织起来的能力单元:契约、资源、执行逻辑,以及围绕它们的调度流程。
那这个文件夹里装了啥?其实就是把处理某类问题的方法、流程规范以及相关工具代码,全都打包放在一起。当大模型遇到相关任务时,按需加载、按流程办事。
比如我们看一个官网给出的处理PDF的例子,打开这个名叫 pdf-skill 的文件夹,你会看到这么几个部分:
-
元数据(描述我是谁,什么时候用我)
---name: pdf-processingdescription: Extract text and tables from PDF files, fill forms, merge documents. Use when working with PDF files or when the user mentions PDFs, forms, or document extraction.---
-
指令(告诉模型第一步该干嘛)
# PDF Processing## Quick startUse pdfplumber to extract text from PDFs:```pythonimport pdfplumberwith pdfplumber.open("document.pdf") as pdf:text = pdf.pages[0].extract_text()```For advanced form filling, see [FORMS.md](FORMS.md).
-
资源和代码(具体的文档和执行脚本)
pdf-skill/├── SKILL.md # 也就是上面包含元数据和指令的入口文件├── FORMS.md # 处理表单的详细说明文档├── REFERENCE.md # 其他参考资料└── scripts/└── fill_form.py # 真正干活的 Python 脚本
到这,我们可以总结出一个公式:

Skill = 契约(Contract)+ 资源(Resources)+ 执行(Execution)
我们结合这个PDF的例子,对应的关系实际非常清晰:
-
元数据 = 契约(Contract)
头部的 name 和 description 明确定义了触发条件和能力边界。
-
Markdown 文档 = 资源(Resources)
像 FORMS.md 就是给 Agent 准备的业务领域知识(比如处理表格)。
-
代码和脚本 = 执行(Execution)
里面的 Python 代码段和 scripts/fill_form.py,就是实打实的动作(填写表格的脚本)。
注:实际这个SKill做的事情就是把PDF文件中的数据提取出来,然后填写回表格里面。
1.2 Skill的运行流水线
既然知道了 Skill 是个文件夹,那 Agent 到底是怎么把它跑起来的?抛开那些花里胡哨的框架,实际底层就是一条 5 步流水线:
-
发现(索引):扫一眼所有 Skill 文件夹头部的元数据,知道自己有哪些能力。
-
选择(路由):根据用户输入做意图识别,决定“当前该调哪个 Skill”。(发现当前任务需要处理 PDF,于是激活上文提到的PDF的Skill。)
-
注入(上下文工程):这也是 Skill 能省 Token 的核心机制(渐进式披露)。它不会把整个文件夹塞进上下文,而是先把契约和基础规则放进去。(激活Skill后读取指令里的 Quick start,如果是简单的文本提取,直接拿里面的代码片段去跑。如果发现任务涉及复杂的表单填写,它看到指令里面说 “see FORMS.md”,才去读取 FORMS.md(资源))。最后根据文档里的说明,调用 fill_form.py(执行)来完成任务。
-
执行(受控边界):如果需要“做事”,模型按契约输出参数,系统拿着参数去跑对应的脚本。
-
汇总(结构化输出):把脚本跑完的结果整理成稳定格式输出。
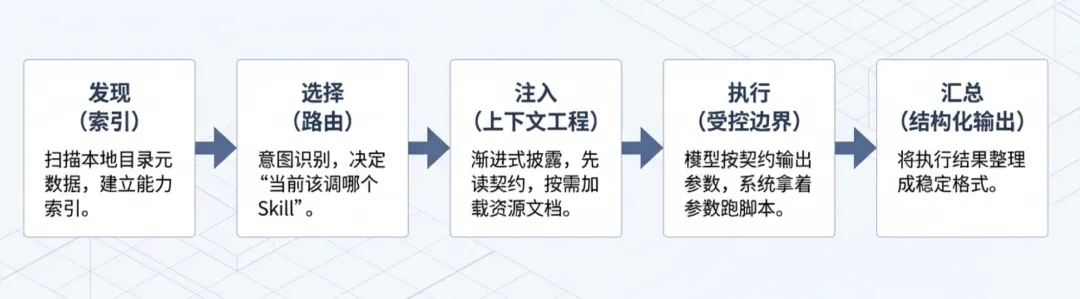
所谓“支持 Skill 的模型”, 本质上是把这条发现、选择、注入、执行、汇总的运行机制内置到了 runtime 里。
1.3 Skill 的核心价值
引入 Skill 的价值,不在于模型突然变得更强,而在于它把原本散落在 Prompt、文档和代码里的东西,组织成了一个可以复用、可以维护、可以约束的整体。
从工程角度看,Skill 带来的稳定性主要来自三点:
第一,输出变得可验证。
原来模型给你的是一段自然语言,看起来头头是道,但系统很难自动消费,也很难判断它到底是不是在胡说。封装成 Skill 之后,我们通常会配合结构化约束,把输出收敛成更稳定的中间结果。
第二,上下文变成按需加载,而不是一锅乱炖。
以前很多规则、样例、说明,都是直接一股脑塞进 System Prompt。结果就是上下文越来越长,噪音越来越多,模型的注意力越来越分散。Skill 把这些知识拆成契约、规则和资源文件,只有在需要的时候才加载相关部分。这样做的直接好处,一方面是节省上下文成本,另一方面更重要的是:把能力组织从“堆料”变成“分层注入”。
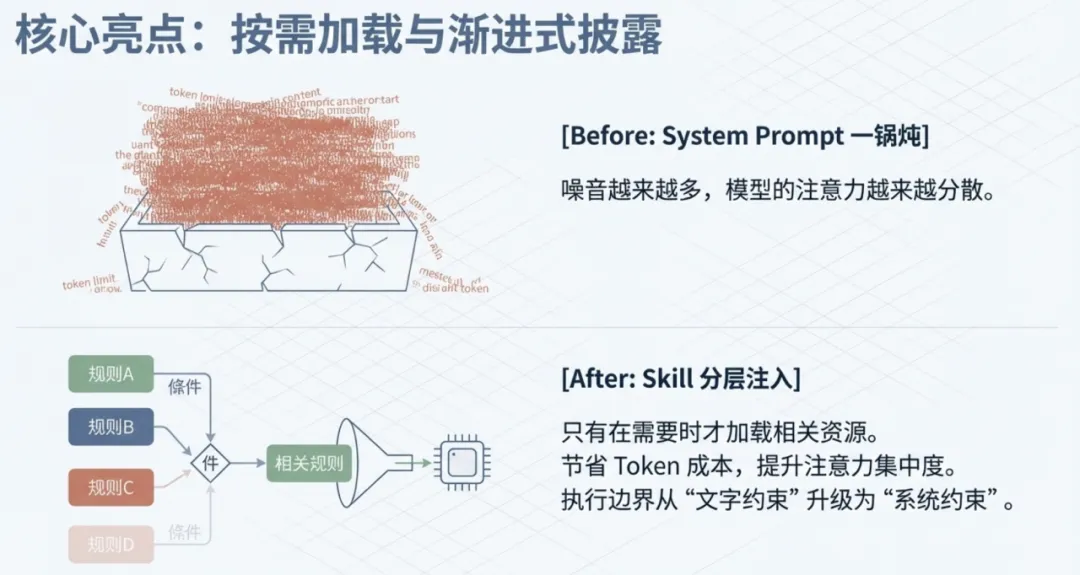
第三,执行边界从“文字约束”升级成“系统约束”。
光靠 Prompt 告诉模型“你不能乱执行”“你只能做这个”,不够。模型会幻觉,也会被污染输入带偏。真正稳的做法,是把脚本和工具放到系统控制里:模型只负责给出意图或参数,执不执行、怎么执行、允许访问什么,由 runtime 决定。你原稿这部分非常好,我基本保留,只把行文更顺了一点。
所以从头到尾,Skill 解决的都不是“智能不足”,而是“工程可控性不足”。
了解了这些,这时候我们再反推一下,为什么Skill的“三件套”缺一不可?
-
只有契约:我们又回到了初始时代所有的内容都不可控。
-
这就退化成了纯 Prompt 工程。你只告诉模型“你要解析 PDF”,但没给它提供 pdfplumber库和底层脚本,大模型只能依靠自身权重的概率去生成文本(也就是幻觉),无法产生实际的解析动作。
-
只有资源:模型的上下文窗口受限,没法处理那么长的内容。
-
相当于你直接把几十页的 PDF 规范文档丢进上下文窗口。没有触发条件(契约)来收敛范围,也没有明确的操作入口,Agent 会在冗余信息中迷失,检索提取效率极低。
-
只有执行:语言本质上是模糊的,两个完全功能不同的函数可能起了一个类似的名字,导致调用出错。
-
系统里注册了一堆工具函数(Tools),但缺乏输入规范和上下文指导。Agent 调度时极容易传错参数,或者在不该调用的环节触发脚本,导致程序报错中断。
通过这种文件夹级别的模块化封装,不可控的大模型概率生成,就被有效的收敛成了确定的系统调用。这样也就完成了工程化,我们可以用大模型来做更多的产业上的事情了。
二、
案例
讲了那么多原理,我们来捋一个简单的Skill来看看吧。
我们平时做开发,最头大的场景是什么?绝对是半夜 on-call 的时候被报警电话吵醒,睡眼惺忪地打开电脑,面对屏幕上疯狂滚动的报错日志抓瞎,谁都没睡醒还得强撑起精神去分析问题。
这时候如果有个 Agent 能帮你扫一眼,直接告诉你哪儿挂了,那是真救命。但就像我们前面说的,普通的对话模型靠不住,你把日志扔给它,它可能顺着你的日志一通瞎分析,给你列出一堆什么检查版本了,重启服务了,我保证这是最后一次,一定能解决。想要让大模型真正干活,就得把它封装成 Skill。
我就以之前最熟悉的“Java 日志排障”为例,按照前面的“三件套”公式,手把手拆解一个Skill 到底长什么样。
2.1 定契约
这里第一步不是上代码,而是先定契约。原因很简单:如果输出仍然是一段松散的自然语言,那么后续系统很难接它,也很难判断它到底有没有说准。
在日志分析这个场景里,一个更工程化的做法,是约束它输出一个结构化结果。比如:
-
summary:一句话总结故障点。
-
severity:严重等级(比如 P0/P1/P2/INFO,这里最好有举例说明)。
-
signals:提取的关键异常类名或特征码。
-
evidence:证据链(必须附带原生日志片段)。
-
next_steps:下一步具体的排查动作建议。
-
missing_info:要定位根本原因,目前还缺什么信息(比如需要另一台机器的日志,或者具体的 Trace ID)。
这里重点说一下 evidence 这个字段。这是干嘛的?这就像咱们有时候用模型查东西,他会给我们标记出处网址。 这里是类似的你不能光告诉我服务挂了,你必须把导致服务挂的那一行日志原文贴出来,我才能确定你不是胡说。
2.2 定资源
接着是资源。处理后端日志,我们有很多硬性的经验法则。比如:
-
常见异常模式库:数据库连接池打满(HikariPool timeout)、内存溢出(OOM: Java heap space)、垃圾回收开销过大(GC overhead limit exceeded)。
-
常见噪音过滤库:K8s 的 /actuator/health 健康检查无用日志、SLB 把 HTTPS 请求错打到 HTTP 端口报的字节解析异常。
在之前做Agent的时候,我们会把这些规则全写在 System Prompt 里。但实际会导致很严重的问题,比如上下文窗口不仅贵,而且内容越长,模型的注意力越涣散,它可能经常会用处理 OOM 的规则去套连接池的问题。
有了 Skill 之后,所有的模式库和噪音库都会作为独立的 Markdown 文件(比如 java_patterns.md 和 noise_filters.md)放在文件夹里。平时模型是不看它们的。只有当契约判定当前进入的是 Java 后端报错排查流程时,系统才会按需读取这些文件,注入到上下文中。这就是 Skill 在上下文工程层面的真正价值:不是让上下文更长,而是让上下文更干净。
2.3 试一试
理论说完了,咱们直接上代码跑一遍。假设半夜系统触发报警,抓取到下面这段日志:
2026-03-05 03:14:15.123 ERROR [http-nio-8080-exec-10] o.a.c.c.C.[.[.[/].[dispatcherServlet] : Servlet.service() for servlet [dispatcherServlet] in context with path [] threw exception [Request processing failed; nested exception is org.springframework.transaction.CannotCreateTransactionException: Could not open JDBC Connection for transaction; nested exception is java.sql.SQLTransientConnectionException: HikariPool-1 - Connection is not available, request timed out after 30005ms.] with root causejava.sql.SQLTransientConnectionException: HikariPool-1 - Connection is not available, request timed out after 30005ms.at com.zaxxer.hikari.pool.HikariPool.createTimeoutException(HikariPool.java:696)...
如果是普通的大模型,他会用一大堆废话跟你解释:“您好,这是一个数据库连接超时错误,HikariCP 连接池在 30 秒内没有获取到可用连接。建议您检查数据库状态是否正常,或者调整连接池的配置参数……”
这段话对人有用(甚至可能无用,有时候模型会给出一些明显不是错误的原因的排查过程),但对工程来说毫无价值。我们不能在告警系统里面匹配相应的段落,进行后续的流程化处理。
但如果我们调用的是上面定义好的日志排障 Skill,大模型吐出来的将是严格遵守契约的 JSON:
{"summary": "HikariCP 数据库连接池耗尽,获取连接超时 (30005ms)","severity": "P0","signals": ["org.springframework.transaction.CannotCreateTransactionException","java.sql.SQLTransientConnectionException","HikariPool-1"],"evidence": "java.sql.SQLTransientConnectionException: HikariPool-1 - Connection is not available, request timed out after 30005ms.","next_steps": ["检查底层数据库负载和慢 SQL 情况","排查是否有业务代码获取连接后未释放 (Connection Leak)","检查 HikariCP 配置的 maximumPoolSize 是否过小"],"missing_info": "当前日志缺失慢查询日志 (slow query log) 和应用实例的 CPU/Memory 监控快照"}
我们有了这个格式化的JSON 之后,系统代码就可以写个明确的 if 语句,只要读到 severity == “P0” 且 signals 包含连接池异常,就可以自动触发脚本收集慢 SQL,或者直接把这个规整的 JSON 发送到 DBA 的IM。我们把不确定的 AI 变成了流水线上一个稳定的数据处理节点,并且可以切实的帮我们处理一些负担。
这个Skill的相关内容我们放在这里,供大家参考:
---name: java-log-analyzerdescription: 分析 Java 后端错误日志,提取关键异常并输出结构化 JSON 报告。当用户提供应用日志或要求排查线上 Java 报错时调用。---# Java Log Analyzer## Role (你的角色)你是一个资深的 Java 后端排障专家。你需要严格分析输入的日志,不能有任何废话。## Constraints (强制约束)- **必须且只能**输出合法的 JSON 格式,绝不允许输出任何 Markdown 代码块符号(如 ```json)。- 输出的 JSON 必须包含以下字段:summary, severity, signals, evidence, next_steps, missing_info。- `evidence` 字段必须是导致错误的原始日志片段,绝对不能自己瞎编。## Resources (依赖资源)在分析具体异常时,请参考本目录下的 `patterns.md` 文件,匹配已知的错误特征和噪音过滤规则。
# Java 常见异常模式与应对策略## 1. 数据库连接池耗尽 (HikariCP)- **特征提取**: `java.sql.SQLTransientConnectionException: HikariPool-1 - Connection is not available, request timed out`- **严重等级 (severity)**: P0- **下一步动作 (next_steps)**:1. 检查数据库慢查询 (Slow SQL) 导致连接被长时间占用。2. 检查代码中是否有开启事务但未提交的情况 (Connection Leak)。3. 确认数据库当前的连接数监控面板。## 2. 内存溢出 (OOM)- **特征提取**: `java.lang.OutOfMemoryError: Java heap space`- **严重等级 (severity)**: P0- **下一步动作 (next_steps)**:1. 立即保留现场,使用 jmap 导出 Heap Dump。2. 检查是否有大对象(如巨型 List 或大文件加载)被放入内存。
三、
最小实现
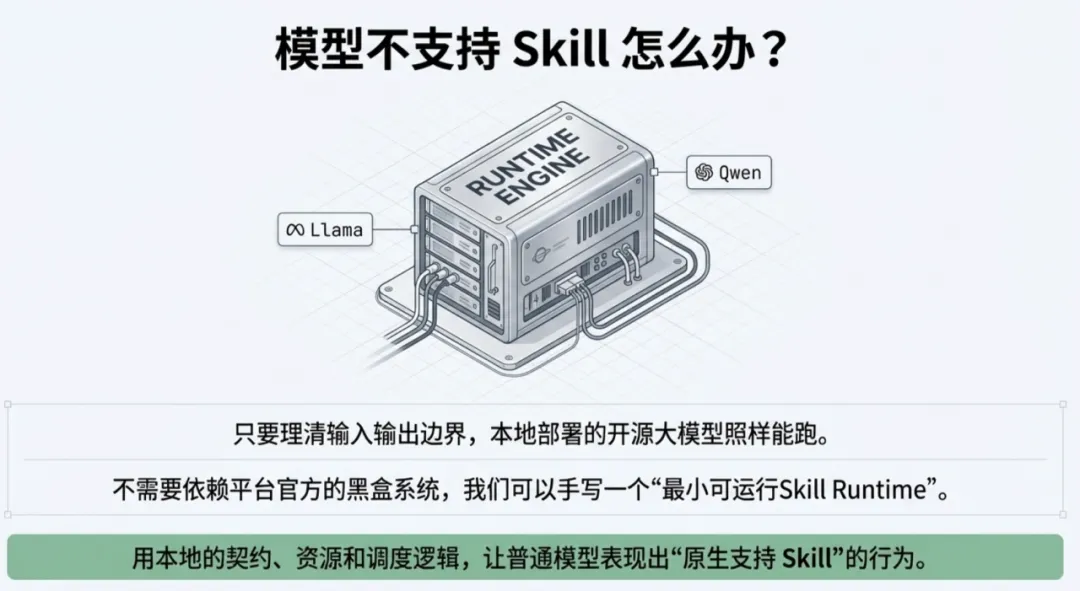
这里实现的不是某个平台官方意义上的 Skill 系统,而是一个最小可运行的 Skill runtime:它用本地 Skill 契约、资源和调度逻辑,让普通模型也能表现出“像支持 Skill 一样”的行为。
前面讲了这么多原理,很多兄弟可能会问:如果我用的开源大模型(比如本地部署的 Llama 或者 Qwen)原生不支持 Skill,难道就不能用了吗?
3.1 核心模块
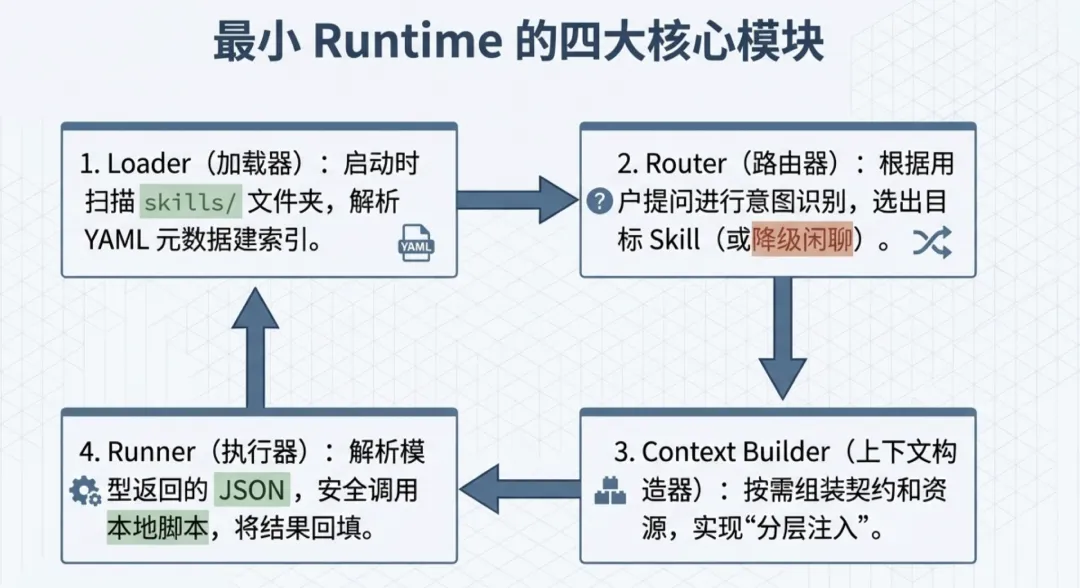
根据我们对原理的梳理,一个能跑起来的“最小 Skill 运行时(Runtime)”,核心其实只有 4 个模块:
-
Loader(加载器):负责在系统启动时,扫描本地的 skills/ 文件夹,把所有的元数据(契约)读到内存里建个索引。
-
Router(路由器):当用户提问时,根据问题做简单的意图识别(最简单的甚至可以用关键词匹配),挑出当前该用哪个 Skill。
-
Context Builder(上下文构造器):这就是实现“分层注入”的地方。把选中的 Skill 契约、基础规则和相关资源拼装成最终发给大模型的 Prompt。
-
Runner(执行器):解析模型返回的 JSON,调用对应的本地脚本,然后把执行结果回填给上下文。
我们看一下这个Python代码的框架:
class MinimalSkillRuntime:def __init__(self, skills_dir="./skills"):self.skills_dir = skills_dirself.skill_registry = {}self.load_skills() # 1. 启动时加载所有 Skilldef load_skills(self):# Loader 逻辑:扫描文件夹,解析 SKILL.md 中的 YAML 元数据passdef route_skill(self, user_query):# Router 逻辑:根据 user_query 匹配最合适的 Skill# 伪代码:return best_match_skill_namepassdef build_context(self, skill_name, user_query):# Context Builder 逻辑:按需组装契约和资源# 伪代码:return prompt_string_with_resourcespassdef execute_skill(self, action_json):# Runner 逻辑:解析模型输出的 JSON,安全执行脚本# 伪代码:# script_path = get_script_path(action_json['action'])# result = run_subprocess(script_path, action_json['args'])# return resultpassdef run(self, user_query):# 核心流水线target_skill = self.route_skill(user_query)context = self.build_context(target_skill, user_query)# 调用大模型获取响应 (假设返回了 JSON)llm_response = call_llm(context)if not llm_response.get("is_finished"):# 执行本地代码,并进入下一个循环execution_result = self.execute_skill(llm_response)# ... 将 execution_result 塞回上下文继续推演 ...
3.2 流程
由于我们的目标是做一个最小可运行实现,整个系统的生命周期其实可以理解成五步:
-
启动与预热
系统启动时扫描 skills/ 目录,把每个 Skill 的 name、description、约束和资源路径建成一个内存索引。
-
SKill路由
服务启动完,就在那儿等着用户发消息。用户发来一段聊天内容后,系统先拿这段话去和咱们刚才建好的“路由字典”(主要是 description 字段)做匹配(我这里直接调用了大模型进行匹配,实际中可能会有关联性更高的方法,本质上这是一次技能路由:从 Skill 描述中找出和当前任务最相关的能力单元),评估一下相关性。
-
命中与回退机制
这里有个分支:如果没有匹配到任何相关的 Skill(说明用户可能只是在闲聊),系统就直接回退到原本的普通对话模式。但如果匹配到了(比如意图识别出用户想分析日志),那就正式激活并准备注入对应的 Skill。
-
按需加载
这就是咱们前面反复强调的渐进式披露。激活 Skill 后,系统不会傻乎乎地把整个缓存全倒进去,而是结合用户的具体聊天内容再做一次判定:当前这一步,需不需要额外加载 Skill 文件夹里的某个特定资源(比如 patterns.md)?需要哪个就只拿哪个。(我这里也直接调用了大模型进行匹配)
-
执行与汇总
最后一步,把前面选好的Skill、按需抽取的资源片段,连同用户的“原始问题”全部提取出来,像拼乐高一样组装成最终的 Prompt,然后去调用大模型,就OK了。
按照上面我们梳理出来的这条骨架,只要你平时写过点后端代码,理清了输入输出的边界,绝对能自己攒出一个最小可运行的 Skill runtime。
说实话三水儿还是建议大家周末抽个半天时间,照着这个思路自己一行一行把代码敲出来。在这个手写的过程中,你对大模型能力边界的理解,以及你遇到报错时的独立思考,是任何 AI 以及我直接把代码发给你都体会不到的。
当然,如果你平时工作实在太忙,只想快点拿一份能直接跑通的代码来研究,或者想直接抄到公司的项目里做个 Demo 证明可行性,我也把我写出来的这套完整源码打包好了。当然这份代码也花了我不少的时间,需要收个9.9。
可以看到,我最终的实现在面对问题时自动路由到了相应的Skill,进行对应的回答。在这个日志分析例子里,我把“识别异常并生成 JSON”作为最小闭环;如果进一步工程化,还可以把“查慢 SQL / 查监控快照 / 查线程栈”也做成独立函数,由 Runner 在命中特定信号后调用。


四、
总结
最后,三水儿想说:Skill 并没有跳出大模型的基本规律。它没有让模型突然变成另一个物种,也没有凭空创造出一种全新的智能形态。它做的事情更朴素,也更重要:把原本散落的能力、规则和执行逻辑,组织成一个可复用、可约束、可维护的工程单元。
所以,理解 Skill 最好的方式,不是把它当成一个需要追热点的新名词,而是把它放回我们熟悉的软件工程语境里去看:
它本质上解决的是能力封装、上下文组织和执行边界这三个问题。
如果你把这三个点想明白了,那你就不会再被各种新包装带着跑。以后无论它叫 Skill、Capability、Workflow,还是别的名字,你都能迅速判断:它到底是在解决什么问题,值不值得上,应该怎么落地。
对技术人来说,真正重要的不是追着概念跑,而是能不能把一个不稳定的模型能力,收敛进稳定的工程边界里。这个能力,比记住多少新名词都更值钱。
你对技术的本质洞察,以及你遇到问题时的独立思考,才是你和 AI 之间最深的那道护城河。
如果觉得这篇硬核拆解对你有帮助,兄弟们顺手点个赞和转发,这就是对三水儿最大的支持。咱们下篇技术干货见!
END