Cerebras 与诸小龙在推理市场的竞赛
Cerebras 与诸小龙在推理市场的竞赛
我说:你见过一个晶圆有多大吗?直径30厘米,像张煎饼。英伟达把这张晶圆切成几百块小芯片卖给你;Cerebras把整张晶圆直接做成一块芯片。
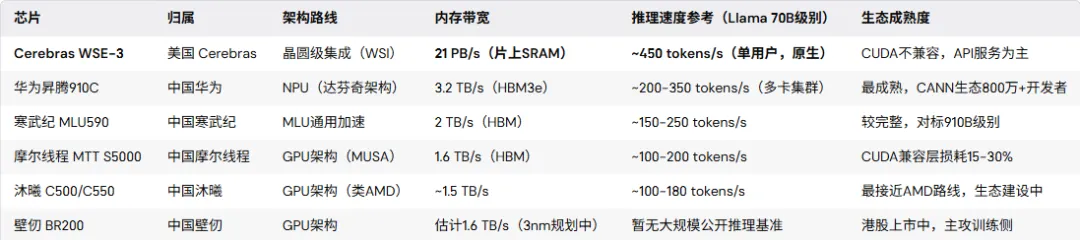
2025年底,Cerebras的WSE-3在推理Llama 4 Maverick(400亿参数MoE大模型)时,跑出了每用户2,500 tokens/秒的速度——比英伟达最新旗舰DGX B200快了2倍以上。而此时,国内最强的华为昇腾910C在单卡推理测试中,速度大约是2,300 tokens/秒。
这两个数字放在一起,你就知道为什么这篇文章值得你花10分钟读完了。
做AI,有两件大事:训练和推理。训练是”让模型学会知识”,是一次性的重资产投入;推理是”让模型回答你的问题”,是每天24小时不间断运行的成本中心。
过去三年,行业只谈训练,大家都在抢H100堆算力。但2026年的趋势已经反转——推理占全球AI算力消耗的比例预计将突破三分之二。你跟ChatGPT说的每一句话,都是推理在消耗算力。
简单说:GPU从外部HBM(高带宽内存)搬数据,来回太慢了。你有再多的计算核心,数据喂不进去,照样闲着。这就是著名的”内存墙”。英伟达H100的内存带宽是3.3 TB/s——已经是业界天花板,但还不够。
Cerebras的解法很暴力:不搬运,直接在芯片上存。
WSE-3把44GB的SRAM直接集成在晶圆上,内存带宽高达21 PB/s(拍字节每秒)——是H100的7,000倍。整个模型的权重就住在芯片里,推理时根本不用去外面取数据。
这就是为什么它跑推理这么快。原理不复杂,但执行难度是地狱级别的。
数据说明:各厂商推理速度因测试模型、批处理大小、精度设置不同而差异显著。Cerebras数据来自官方及第三方基准测试;国产芯片数据综合各厂商招股书、学术评测及知乎行业分析,仅供量级参考。
三、Cerebras凭什么这么快?三个字:架构不同
Cerebras的领先,不是堆料堆出来的,是路线选对了。
英伟达的DGX机柜要把72块B200用NVLink高速互联,协调这些芯片通信本身就是巨大的工程开销。Cerebras的WSE-3是一块芯片,900,000个计算核心直接在一个硅片上通信,延迟是皮秒级,根本不存在”多卡协调”问题。
这就是为什么WSE-3在单用户延迟(TTFT,首token时间)上表现尤其夸张——240毫秒,做到了人类感知的”即时响应”门槛之内。
推理是内存带宽敏感型任务。国产主流芯片里,寒武纪MLU590的2 TB/s已经算很高了,但和WSE-3的21 PB/s相比,量级上就差了一万倍。
(不要觉得这个对比不公平——这恰恰就是架构路线不同带来的根本差距。)
WSE-3整机(CS-3系统)功耗约23kW,却可以替代”几十块H100″的推理工作量。英伟达的DGX B200功耗则高达120kW。单位算力功耗,Cerebras并不吃亏。
说完Cerebras,不得不说说国产这几家的战力。
昇腾910C的FP16算力约780 TFLOPS,功耗310W,推理效能约达H100的60%——这意味着它已经超过了英伟达专门向中国供应的H20。而且CANN软件栈有800万开发者,算是国内生态最厚的。与Cerebras的差距主要在单用户低延迟场景,但在大吞吐量集群推理上并不输太多,只是有换个计算逻辑(机柜级pooling vs 单用户native)。
MLU590的2 TB/s带宽和80GB显存,是国内GPU架构里的技术高点。2024年Q4它才刚开始盈利,2025年前三季度已盈利16亿元,在国产芯片里算是罕见的。但对标参考物是910B而非910C——落后华为一代,更别提Cerebras。
摩尔线程和沐曦,是两家”上市了但还在爬坡”的公司。
2025年底两家同时登陆科创板,首日分别暴涨469%和569%,市值都奔着3000亿去了。(市场有时候定价的是故事,不是芯片性能。)摩尔线程的S5000完成了从GDDR6到HBM的跨越,是里程碑;但CUDA兼容层15-30%的性能损耗,是短期内无解的软件工程债。
壁仞和天数智芯,主要还是在追训练侧的蛋糕。两者核心卖点是GPU全栈能力,但推理侧尚无可与外部公开对比的系统级基准数据。
讲了这么多Cerebras的好,也要说清楚它的短板。作为投资者,这才是真正值钱的认知。
全球AI工程师都在CUDA生态里。Cerebras有自己的SDK,虽然支持PyTorch和TensorFlow,但不支持原生CUDA。企业迁移成本极高。这就是为什么它只能以”API服务”的方式卖推理能力,而不是直接卖芯片给企业部署。
一块WSE-3晶圆里有4万亿个晶体管。芯片越大,制造缺陷概率越高。Cerebras通过”稀疏冗余核心”技术来规避这个问题,但量产成本和良率控制,至今都是行业密谜。
WSE-3的44GB片上SRAM,对于Llama 70B这种模型已经够用;但下一代万亿参数模型,一块晶圆根本装不下。Cerebras有”Weight Streaming”技术来处理超大模型,但这时候它的速度优势会显著收窄。
▶ Cerebras卖的不是芯片,它卖的是”推理即服务”(Inference-as-a-Service)。
这是它和国产四小龙竞争的本质差异。国产厂商在卖硬件(把芯片塞进数据中心);Cerebras在卖算力订阅(你调用API,我出推理速度)。
2025年,OpenAI签了一份合同,让Cerebras为其提供750兆瓦的算力支撑直到2028年,合同估值超过100亿美元。这才是Cerebras IPO时给出266亿美元估值的底气所在。
而国产四小龙的商业逻辑完全不同:它们在吃国家政策驱动的国产化替代红利,客户是中国国有云厂商、政府智算中心,采购动机是安全合规,而不是追求极致推理速度。这两条赛道,短期内并不直接竞争。
▶ 问题是:如果Cerebras的推理速度变成行业标准,国产芯片会面临什么压力?
当中国互联网大厂出海、国内头部AI公司需要向海外用户提供低延迟服务时,”国产AI芯片”的性能势必经受市场选择的考验。这是一个3-5年后才会真正爆发的矛盾,但有心人应该现在就看清楚。
Cerebras即将在纳斯达克上市(代码CBRS),目标估值266亿美元,2025财年营收5亿美元,对应60倍PS。
这不是一个用传统估值框架能安心买入的价格。但如果你相信”AI推理将成为新世纪的电力基础设施”这一判断,Cerebras是迄今为止最有差异化技术路线的纯推理基础设施公司。