从95%到0%,中国GPU市场的"后英伟达"时代
|
份额「清零」与算力狂飙的背后:谁在填补英伟达留下的千亿空白? |
上个月,英伟达CEO黄仁勋在接受美国智库SCSP采访时表示:受美国芯片出口管制政策影响,英伟达在中国AI GPU市场的份额“已降至0%”,中国企业填补了这一空白。
海外媒体分析认为,美国的出口管制加速了中国实现自给自足的进程;摩根士丹利预测,到2030年,中国76%的AI芯片供应将由本土企业提供,10年内深远改写AI芯片的竞争格局。
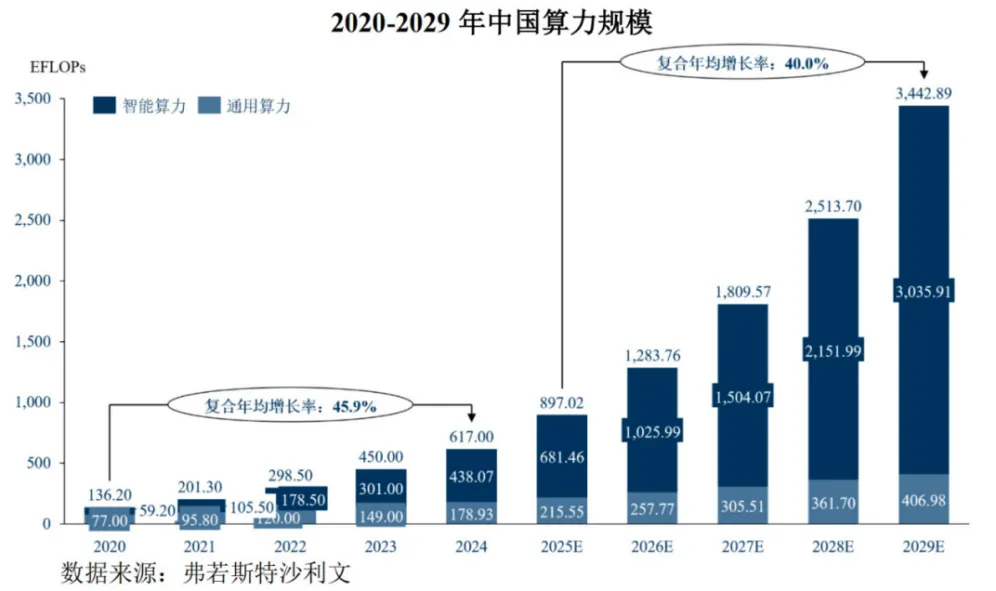
随着AI和大数据技术的广泛应用,中国算力规模呈现快速增长态势,整体规模从2020年的136.2 EFLOPs增长至2024年的617 EFLOPs(1 EFLOPs = 1018 FLOPs),年均复合增长率为45.9%。其中,
-
智能算力是引领算力规模指数级增长的核心,规模从2020年59.2 EFLOPs增长至2024年的438.07 EFLOPs(占比71%)。
-
通用算力规模2024年为178.93 EFLOPs,得益传统行业的数字化转型,如企业日常办公、数据存储管理、业务系统运行等常规计算场景释放稳定需求。
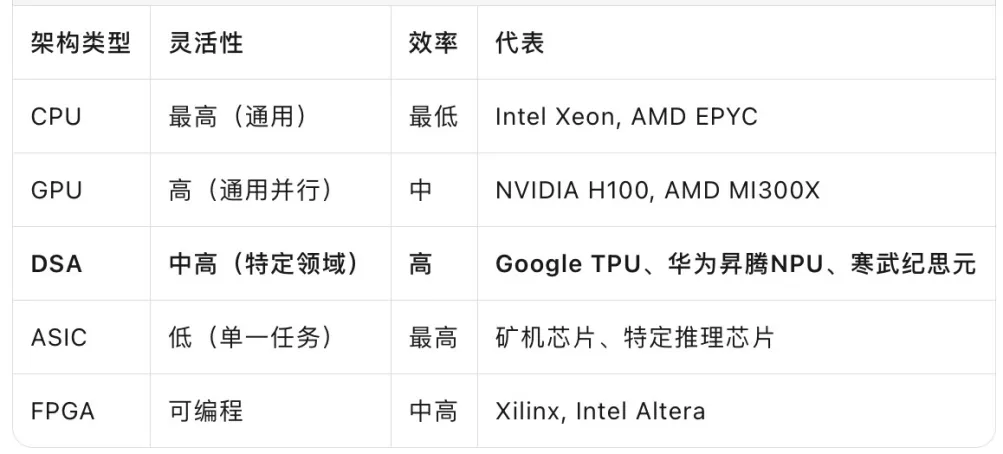
在此背景下,AI算力加速芯片作为专用计算引擎应运而生,按架构形态可分为GPU、ASIC、FPGA及新兴DSA四大类,各有其适用场景与技术路线。
 GPU,AI训练与推理的主流选择
GPU,AI训练与推理的主流选择
随着深度学习的发展,GPU在AI训练与推理领域逐渐成为主流选择。
GPU最初用于图形渲染,逐渐发展为通用计算加速引擎,其大规模并行计算架构可同时执行海量计算任务,成为现代计算基础设施的核心组件。
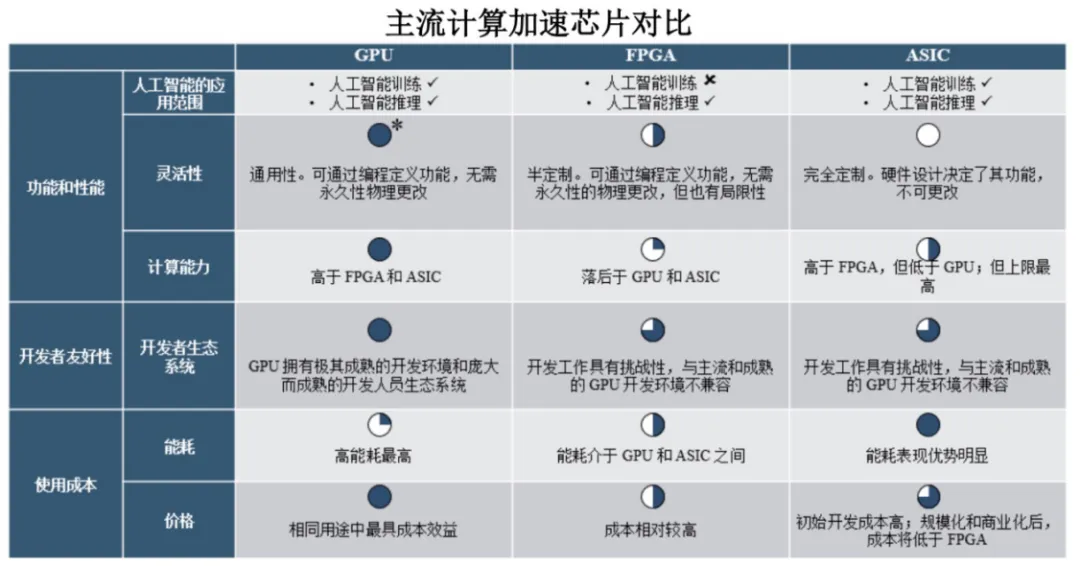
尽管GPU耗电量较高,但因应用灵活性、计算性能、开发友好性上的突出优势,使其成为AI计算场景中兼具效率与普适性的优选方案。具体,
-
从应用覆盖看,GPU同时适配AI训练与推理场景;在功能特性上,相较FPGA的半定制局限与ASIC的完全定制且不可更改性,适配性更优;在计算能力维度,以英伟达B200为代表的GPU产品性能远高于当前FPGA和ASIC相关产品;开发生态层面,GPU依托成熟开发环境与庞大开发者生态系统,远胜FPGA以及ASIC在开发工具兼容性上的事实表现。
-
GPU依然是AI市场的主导芯片:
其增长速度最快,市场份额预计从2024年的71%至2029年的80%。以ASIC和FPGA为代表的其他类型芯片也已实现商业化,并在市场中占据一定比例。
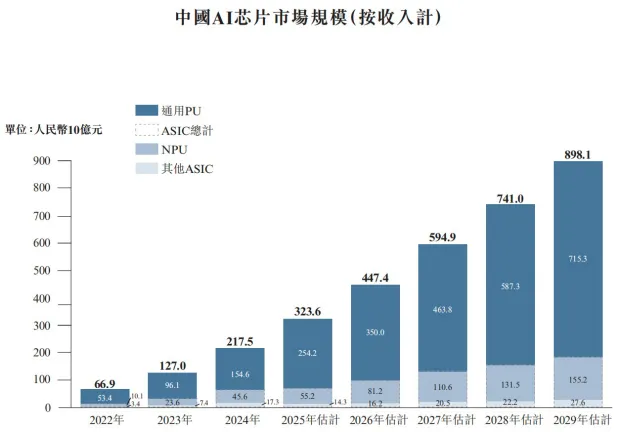
注:FPGA目前仅占整体AI芯片市场相对较小的比例(2024年<3%),故未将其显示为单独区块。
根据IDC数据,训练型AI服务器中GPU的价值占比高达73%,而推理型AI服务器中GPU的价值占比约为25%。
从英伟达训练服务器BOM占比来看,英伟达最近三代GPU产品A100、H100、B100配套的服务器中,GPU占比分别为69%、76%和79%,呈现不断上升的趋势。
-
GPU的技术壁垒:
GPU技术壁垒极高,需要协同攻克硬件架构设计、微处理器核心、存储层次结构、并行计算算法、编译优化、驱动开发以及完整软件生态等多个深度耦合的技术领域,形成了环环相扣的技术链。
GPU的构成
GPU的关键组件包括决定其处理能力和运算效率的微架构,以及由开发工具、程序库和应用程序接口(API)组成的强大软件生态系统,生态系统确保了开发者能够在各类应用场景中高效调用GPU的计算能力。
①硬件构成
GPU的硬件构成主要包括(按层级):GPC(图形处理簇) > TPC(纹理处理簇) > SM(流式多处理器,具体执行实际任务,核心组件又包括:核心、共享内存/L1 cache、寄存器、Warp Scheduler-线程调度器等)。
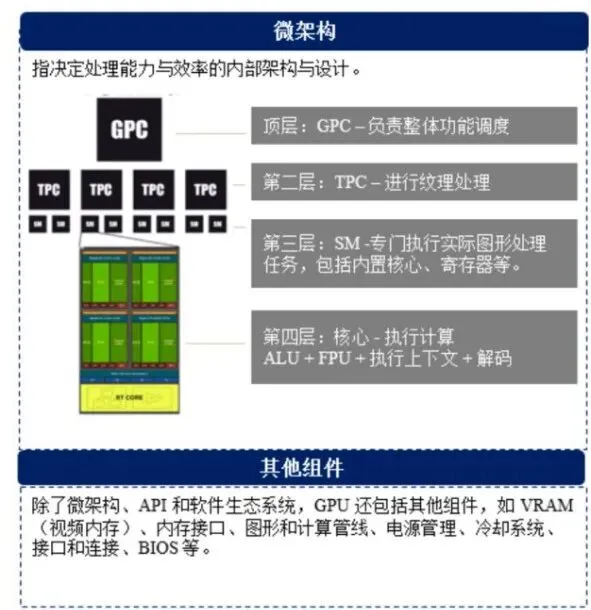
注:现代数据中心GPU虽然保留了GPC/TPC/SM的层级命名,但内部结构已大幅偏向通用计算,纹理单元在计算卡中被弱化甚至移除。
SM具有「复制」特性,每个SM结构完全相同,独立执行不同的线程块(Block),这就是GPU SIMT架构的本质——单指令多线程,通过SM复制实现大规模并行。
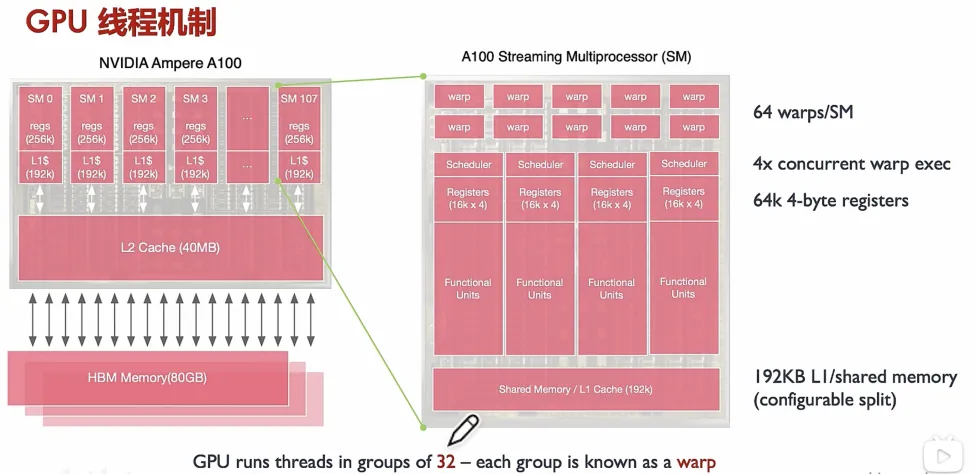
②软件生态系统
GPU生态系统由上层算法库;中层接口、驱动程序、编译器和底层硬件架构等构成。

-
主流通用GPU编程生态系统:
通用GPU行业由英伟达CUDA平台主导,自2006年推出以来,全球开发人员一直依赖该系统编程及训练AI模型,从而创造庞大的技术生态系统。
如今,超过80%的AI场景依赖该平台进行研发。即使出现新的通用GPU产品,兼容该平台对于应用广泛推广仍然至关重要。
 三大细分GPU产品
三大细分GPU产品
根据功能定位,GPU主要分为全功能GPU、图形GPU和GPGPU。
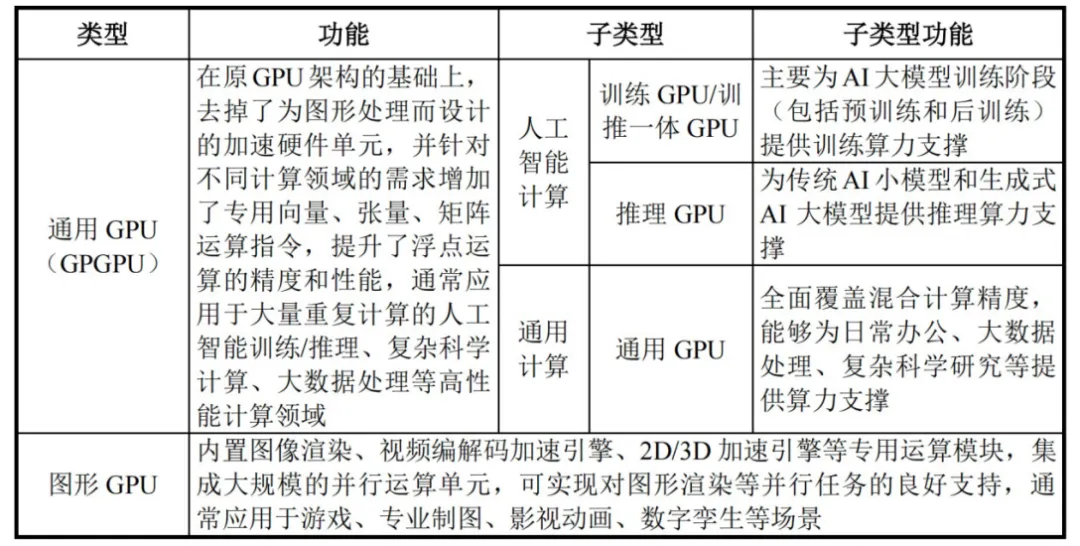
①全功能GPU
这类GPU具备功能完备性与计算精度完整性,在工作效率、生态完整多样性以及兼容性等方面更具优势,能够更好地适应未来新兴及前沿计算加速应用场景的需求。
功能完备性:体现为在单一GPU芯片中集成了AI计算加速、图形渲染、物理仿真和科学计算、超高清视频编解码等多种能力,满足多样化的计算需求;
精度完整性:体现为单一芯片支持FP64 Vector、FP32 Vector、TF32 Tensor、FP16/BF16 Tensor、FP8 Tensor、INT8 Tensor等不同计算精度,满足GPU加速不同场景的计算需求。
②图形GPU
专为图形渲染和PC游戏应用而设计,针对高清显示及高性能2D/3D图形计算进行了优化。计算机的图形处理任务主要由显卡承担,图形GPU作为显卡的核心部件。根据Jon Peddie Research数据,2024年全球独立显卡出货量为3470万张,同比增长12%。
因为图形处理往往涉及到大量的矩阵运算,计算量大但易于并行化,GPU通过简化控制单元并集成大规模的并行运算单元,实现对图形渲染等并行任务的良好支持。图形GPU通常内置图像渲染、视频编解码加速引擎、2D/3D加速引擎等专用运算模块。
③GPGPU(通用GPU)
省去了与图形显示和渲染相关的功能,专注于利用GPU架构执行通用并行计算任务。并针对不同计算领域的需求增加了专用矢量、张量、矩阵运算指令,提升了浮点运算的精度和性能。目前,已成为智算芯片的首选。
-
GPGPU特征:
1)高度并行性:GPGPU拥有大量并行计算单元,多条流水线可以在单一控制部件的集中控制下运行。
2)高内存带宽与多级缓存:GPGPU通常集成高速的GDDR或HBM显存颗粒,提供高访存带宽以处理数据密集型运算;GPGPU的多级缓存体系包括全局内存、共享内存、寄存器等,大幅提高数据访问效率、降低延迟
GPU的缓存机制:
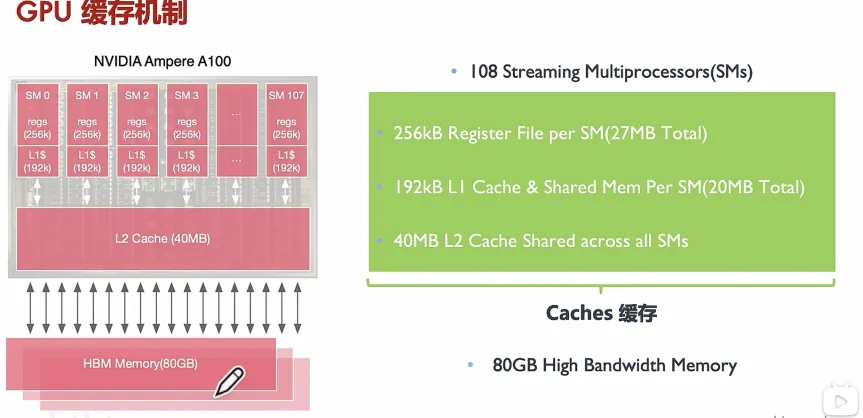
 关键参数
关键参数
GPU的性能由多个关键参数决定,包括核心数量、工作频率、显存容量、显存带宽、计算能力与精度覆盖范围等:
参考英伟达的A100、H100芯片的性能对比,两者用于AI计算等场景:
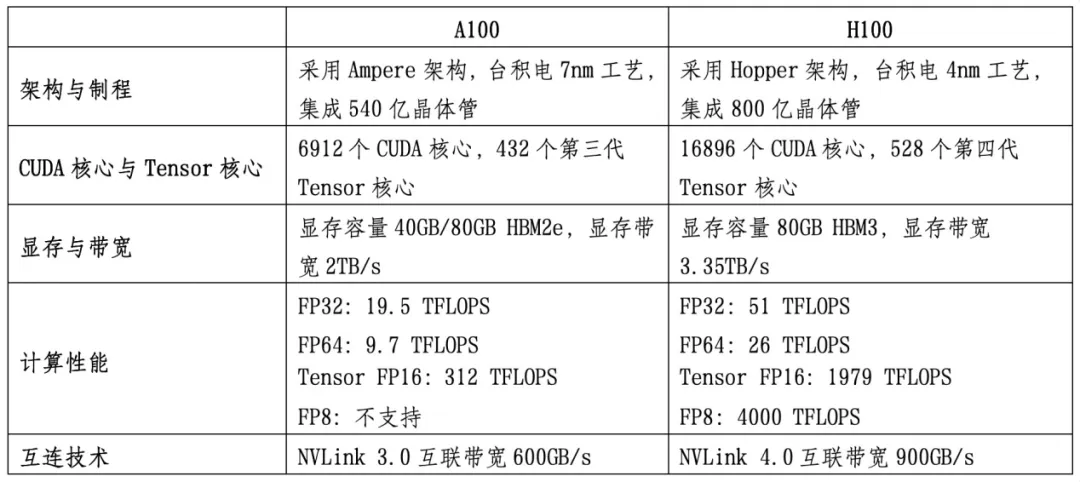
1)核心数量
作为GPU的核心指标,核心数量越多,GPU在处理图形渲染、科学计算、AI计算加速等任务时能够处理更多线程,提升运算效率。核心数的增加不仅可以显著提升性能,也能有效分摊工作负载,从而更好地满足高强度计算需求。
GPU拥有成千上万个简单的计算核心,能够同时处理大量的计算任务。相比之下,CPU的核心数量较少(通常为4-64核),更适合处理复杂的单线程任务。如,英伟达的H100芯片:16896个CUDA核心,528个第四代Tensor核心。
2)时钟速度/频率
时钟速度指GPU每秒可执行的时钟周期数,对数据处理速度和性能输出具有直接影响。更高的时钟速度意味着在同等时间内能够完成更多的运算任务,满足对实时性、低延时的应用场景需求。
如,一个频率为1MHz的时钟信号,每秒会完成100万次周期性变化(时钟周期数 = 1秒/时钟频率)。
3)显存
GPU内的显存技术以HBM和GDDR为主,其中HBM相较GDDR(图形双倍速率同步DRAM)的传输速度更快、功耗更低,在高性能GPU芯片中应用广泛。
-
显存容量:
显存是GPU临时存储数据的空间,容量的大小在处理大型数据集、高分辨率图像或视频时尤为重要。较大的显存容量可减少GPU与系统内存之间的频繁数据传输,在多任务或高分辨率场景下有效提升性能和效率。
-
显存带宽:
显存带宽指单位时间内GPU内部存储器可传输的数据量。较高的显存带宽确保了在面对高负载时,数据能被快速送达处理核心,进而维持流畅的运行效率。对需要高吞吐量的应用(如深度学习推理或复杂图形渲染)而言,显存带宽是关键的性能瓶颈之一。
4)计算能力
计算能力通常以GFLOP/S(每秒十亿次浮点运算)表示,是衡量GPU并行计算性能的主要指标。
如,FP16 作为衡量人工智能训练芯片的核心指标之一,数值越大,代表芯片产品的计算能力越强。
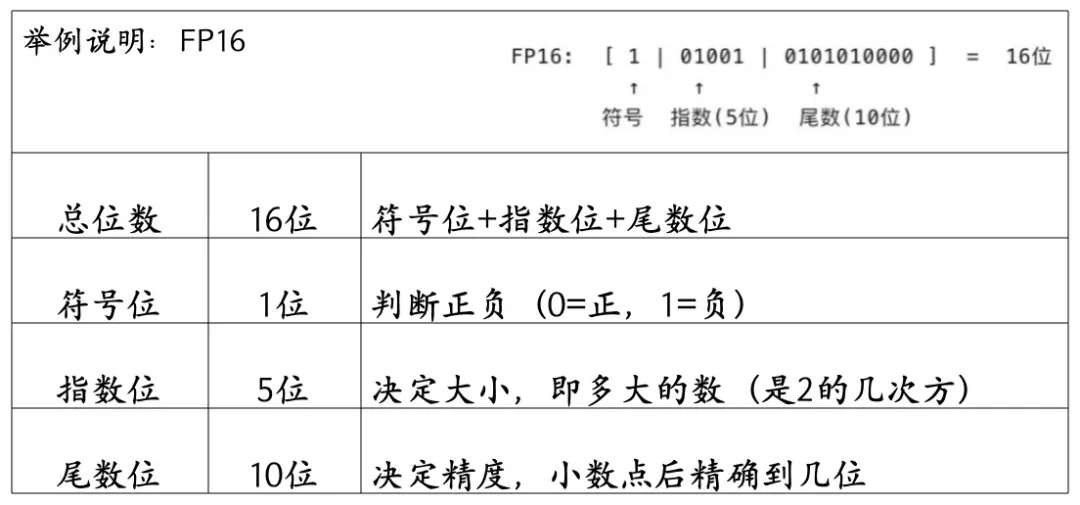
5)计算精度覆盖范围
GPU支持的计算精度范围(如FP64、FP32、FP16、FP8、INT8等)反映了其在多样化任务中的灵活度。
能够支持多种精度水平的GPU不仅具备更高的灵活度,也能在多样化的AI任务中实现更佳的性能与能效。
 多卡互连
多卡互连
随着模型规模、数据量、参数量的快速增长,单一芯片、单台计算设备已经无法满足不断涌现的大规模数据、多任务应用的需求。
通过集群互连弥补单卡性能不足、使用多台设备同时运算的“分布式并行”策略成为了当前及未来发展的主流选择,基于Scale Up与Scale Out的技术应运而生。

-
高速互连技术,具体落实“部署、连接和调用”:
然而进一步的,并行计算所产生的集合通信数据规模极大,如何部署、连接和调用这些分布式的计算网络或设备,以实现给定硬件条件下的最高运算效率,成为制约大模型分布式计算的瓶颈。
高速互连技术则在此环节发挥关键作用,多卡互连能力、卡间互连带宽直接影响集群有效算力,更优的互连技术方案能更好支持数据并行、流水线并行和张量并行等。
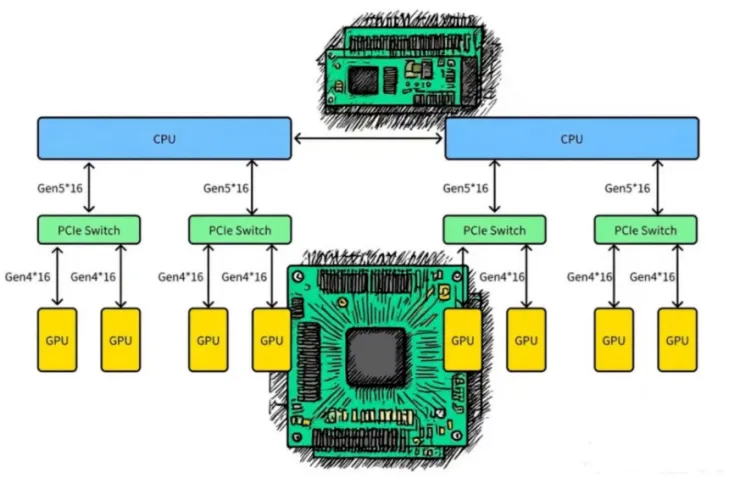
传统PCIe连接,面临NVLink等专用互联技术冲击:
传统架构中,GPU通过PCIe连接CPU导致无法直接点对点通信,且CPU提供的PCIe通道数量限制了GPU扩展。即便借助PCIe Switch实现多GPU接入和P2P通信,随着GPU占比攀升,PCIe带宽远低于处理器与本地内存的带宽,逐渐成为系统性能瓶颈。
英伟达推出的NVLink则实现了GPU之间的直接互连,相较于传统PCIe总线实现更加快速、更低延迟的系统内互连解决方案。但此类技术属于厂商私有方案,难以跨平台适配其他GPU场景,存在生态封闭性局限,也推动了开放异构智能加速系统的探索。
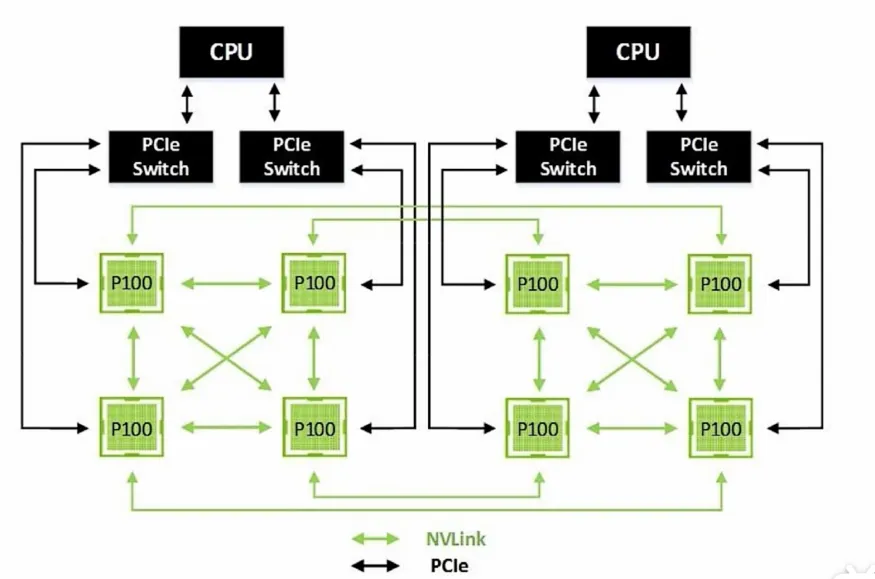
互联设备范围的拓展,GPU互联技术不仅支持GPU之间的互联,如英伟达2022年推出的Hopper架构中,还支持GPU与CPU的互联。
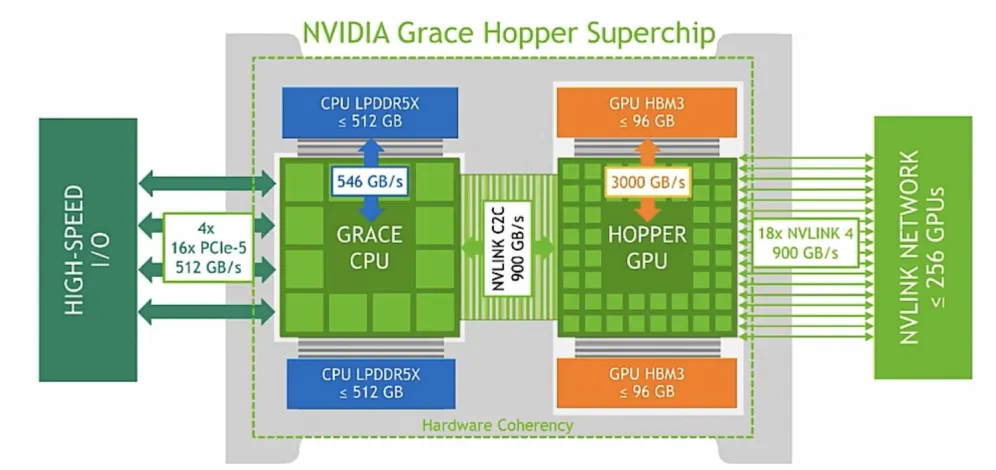
国产GPU互连方案近年来发展迅速,但整体仍处于追赶阶段,与英伟达NVLink存在一到两代差距。且,由于单卡算力差距难以短期弥补,国产厂商普遍采用超节点(SuperNode)工程化方案。
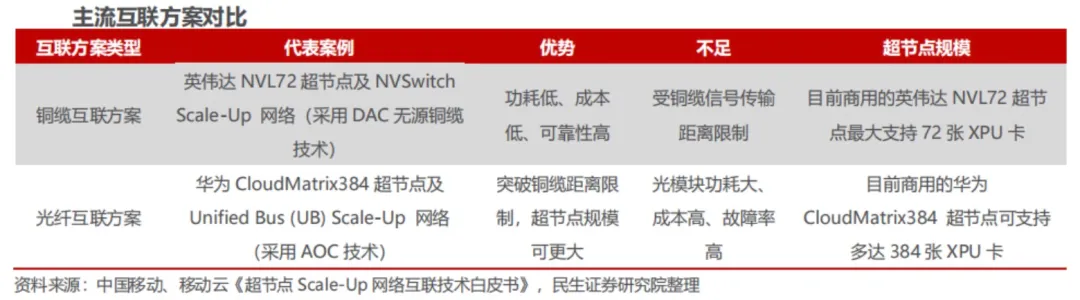
-
华为的突围:
华为在2025年Hot Chips大会上推出UB-Mesh技术,目标是用单一协议统一AI数据中心内外部节点的所有互连(即单一协议取代PCIe、CXL、NVLink和TCP/IP协议)。为实现这一目的,华为计划开源该协议。
然而,华为承认,在整个数据中心推广这一概念会带来新的挑战,尤其是从铜缆(仍在机架内部连接)过渡到可插拔光纤链路。长距离传输不可避免地需要使用光纤,但其错误率远高于电气连接。
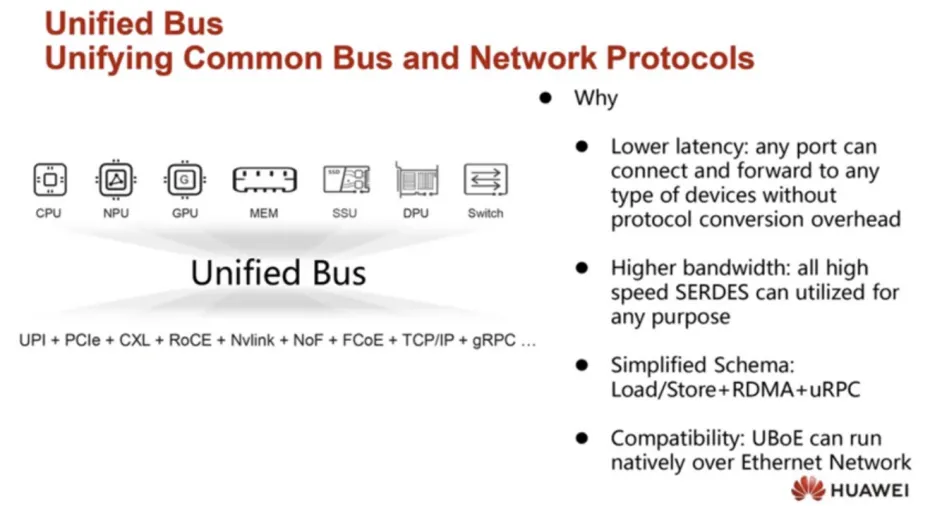
 竞争格局
竞争格局
全球GPU市场整体呈寡头垄断格局,英伟达、超威半导体2家厂商基本分割了全球市场。
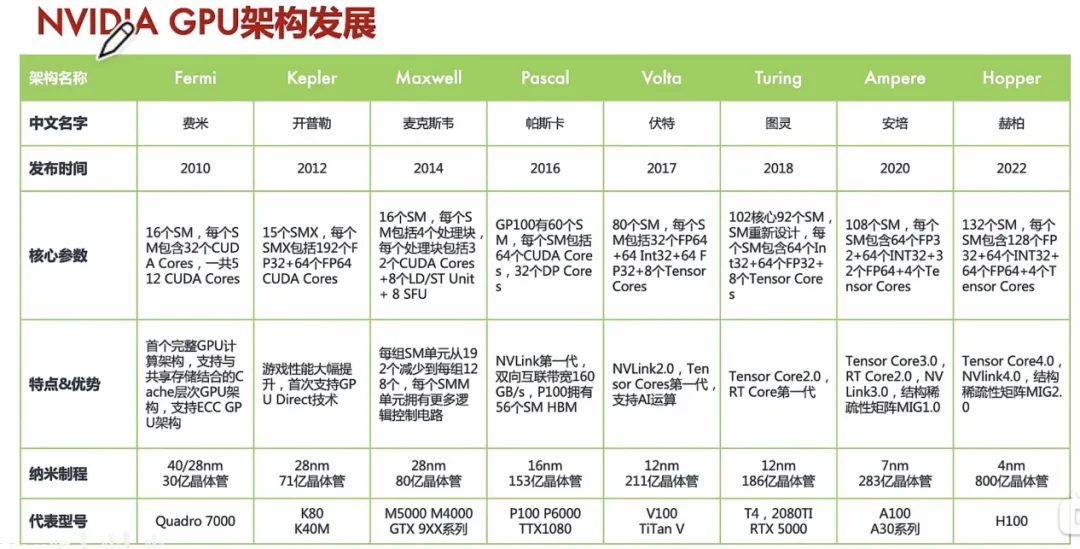
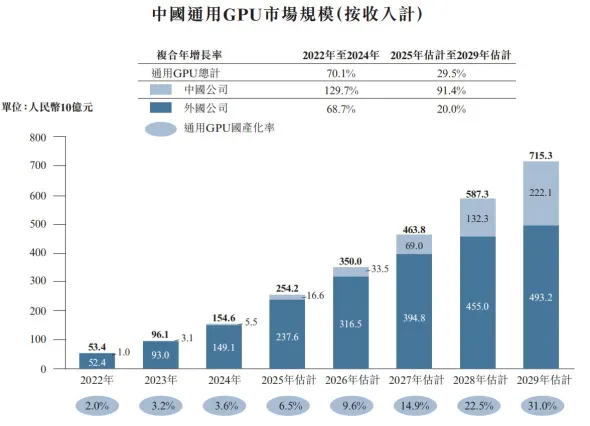
中国通用GPU市场的国产化率持续上升。按收入计,2022年到2024年,国产化率由2%增加至3.6%,预计到2029年将达31%。
算力之争终归于生态之争,国产GPU的突围不在单点超越,而在能否筑起开发者不愿离开的护城河。