如何利用GEO做内容营销?

|作者:李逸和
全文4106字,预计阅读需6分钟
最近有一个朋友说,他们客服投诉无端端增加一百多个。
我说,这是咋回事,她说全是豆包的锅?
去年有一段时间他们的产品搞促销,原价1000多的,那段时间都是卖859元。
来源是两年前一个测评账号发的文章,很多博主赶上薅羊毛,顺手把活动价记进去。文章发出去,被各种平台转来转去,现在还活得好好的。
搞得用户问豆包这个东西多少钱,豆包一直回复是859元,一直问客服要优惠价,这那还有这个价格,都不是促销种草的阶段了。
所以,很多人就觉得他们品牌割韭菜,有人直接要求按859补差价,还有人聊了半天,最后一句”我再想想”,然后就没有然后了。
后面他们市场部也发了好多通稿想抹掉这个消息,发现都石沉大海,刚好我最近也在研究GEO优化。
我们一起来看看豆包究竟喜欢什么内容吧。

SEO与GEO的区别
先说一个很多内容团队都有过的经历。
百度后台数据好看,关键词排名稳,阅读量也过得去。
但有一天甲方拿着手机问:怎么豆包没有收录我们的品牌内容?
打开一看,豆包给出了一段行业介绍,引用了三四个来源,没有一个是自己做的内容。
很多人第一反应是内容质量不够好,其实不是。
是因为SEO和GEO压根就是两场不同的游戏,评分标准从一开始就不一样。
SEO解决的是排名问题。链接权重、关键词匹配,谁布局更合理谁就排得靠前。用户看到一个列表,自己决定点哪个。
GEO解决的是被引用的问题。
豆包在回答问题时,不给用户列链接,它从海量内容里筛出最可信、最准确的片段,整合成一段话直接告诉你。
用户看到的是已经处理过的答案,根本不知道背后哪些内容参与了竞争,哪些被淘汰。
因为争排名和争被引用是两件事。

这两套体系不是替代关系。如果你的团队至今只在做第一列,第二列的阵地就一直空着。
别人为了获得引用会随便整合信息发布,这就会造成像我朋友遇到的情况一样,你不去做正确的信息发布,就会造成信息漏洞。
那GEO这套评分体系,具体在看什么?这就要说到一份文件了。

GEO收录来源与评分标准
很多人研究GEO,绕不开谷歌的一份文件。
2025年9月最新版的谷歌《搜索质量评估指南》,全英文版共182页,为了大家阅读方便,我已经使用Claude进行全文通读,精华的部分已经提取到本文,如果你感兴趣可以私信回复“01”获取原版手册。
这套评分框架最早是为了YMYL(Your Money Your Life)领域而诞生的,通译为中文叫“你的钱财与人命”,因为涉及6大方向:医疗健康与人身安全,金融安全与资产,公民、政府与法律,新闻与时事,特定社会群体,重大人生抉择。
这些领域信息一旦出错会严重影响人身安全,所以谷歌在全球雇佣了数万名第三方“人工质量评估员”(Quality Raters)。
这些人的工作不是直接修改搜索排名,而是像“神秘顾客”一样,去给谷歌现有的搜索结果打分。谷歌的工程师再根据这些人工反馈,去训练和优化机器算法。
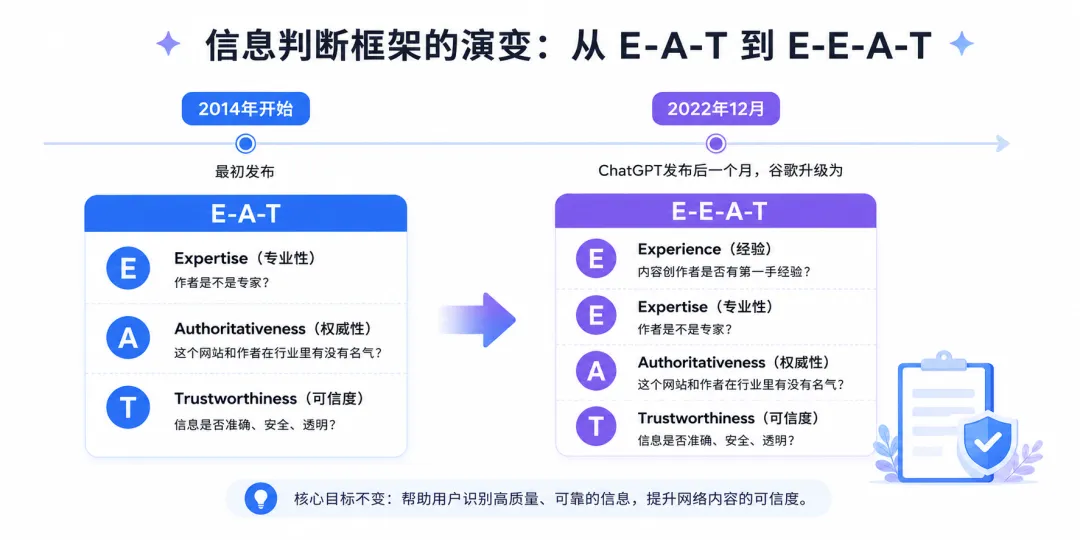
2014年开始这个拿来判断信息的框架,最开始是E-A-T。
-
Expertise(专业性):作者是不是专家?
-
Authoritativeness(权威性):这个网站和作者在行业里有没有名气?
-
Trustworthiness(可信度):信息是否准确、安全、透明?
后来,2022年12月,ChatGPT发布后一个月,谷歌在前面加了一个E,变成E-E-A-T。
-
Experience(经验/第一手体验):创作者对该主题的第一手或生活经验程度
原因很直接,AI能把行业框架背得滚瓜烂熟,但它没有真的带过项目、接过客户、踩过坑,Experience是AI伪造不了的东西。
现在中文平台还没有统一标准化的GEO收录标准,所以本文援引谷歌指南作为参考,不代表中文平台机制与之完全一致。但AI运作技术逻辑具备一致性,仍有非常大的学习意义。
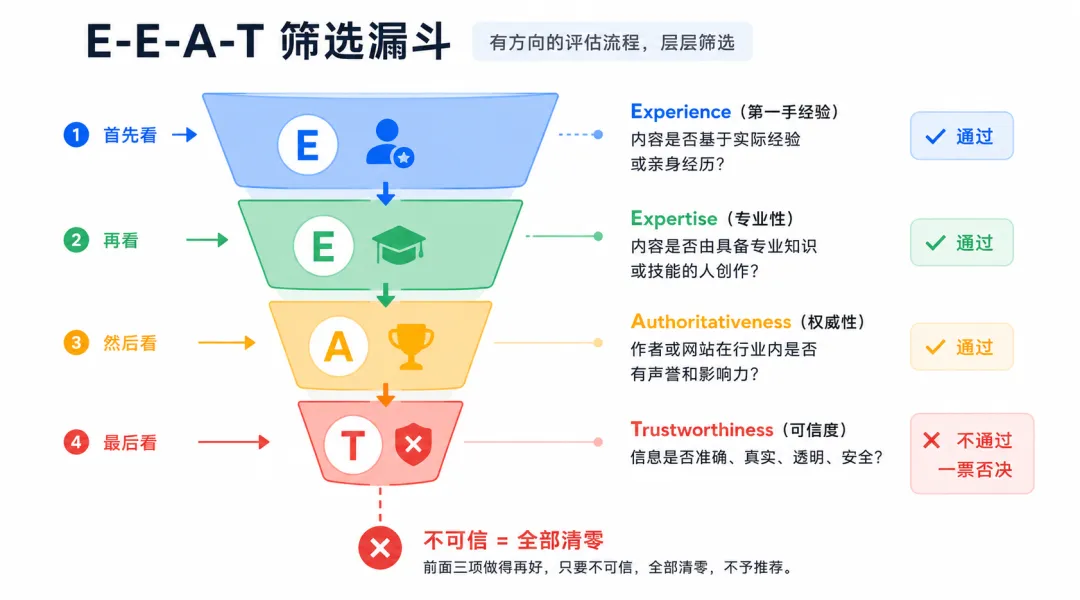
搜索指南把E-E-A-T设计成一个有方向的筛选漏斗,先看有没有第一手经验,再看专业性够不够,再看在行业里有没有声誉,最后T是一票否决,前面三项做得再好,只要不可信,全部清零。
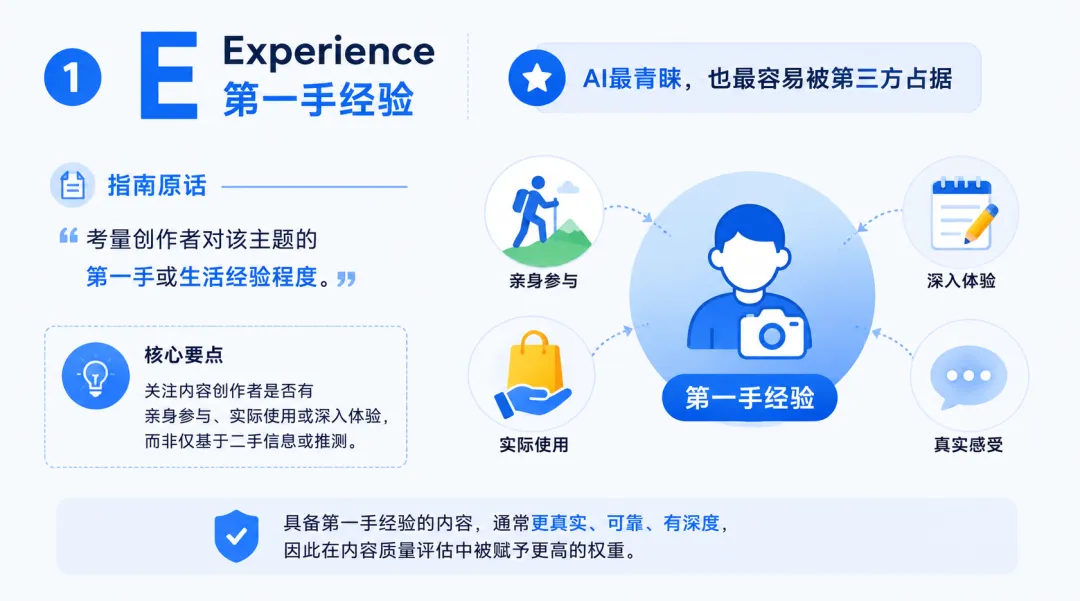
1)第一个E,Experience,第一手经验
AI最青睐,也最容易被第三方占据
指南原话是:考量创作者对该主题的第一手或生活经验程度。
说白了,你问一个用过这个产品的人和一个没用过的人,你更信谁?
问题就出在这里,第一手经验最真实、最被AI青睐,但这类内容也最容易出问题,时效性差、信息有误差、传播出去就很麻烦。
品牌不主动占这个位置,第三方内容发送多了就会被AI引用。那篇写了859元的测评博客,就是这么进来的。
所以品牌自己要下场说”我们做过”。案例要有真实数据,不能只写过程不写结果;”我们在某个客户身上验证过,复购率从12%涨到31%”比”研究表明”有分量得多。价格、参数类内容要标注发布时间,定期更新。
用户写了第一手体验内容,要有机制及时跟进,不能任由它在外面流传。
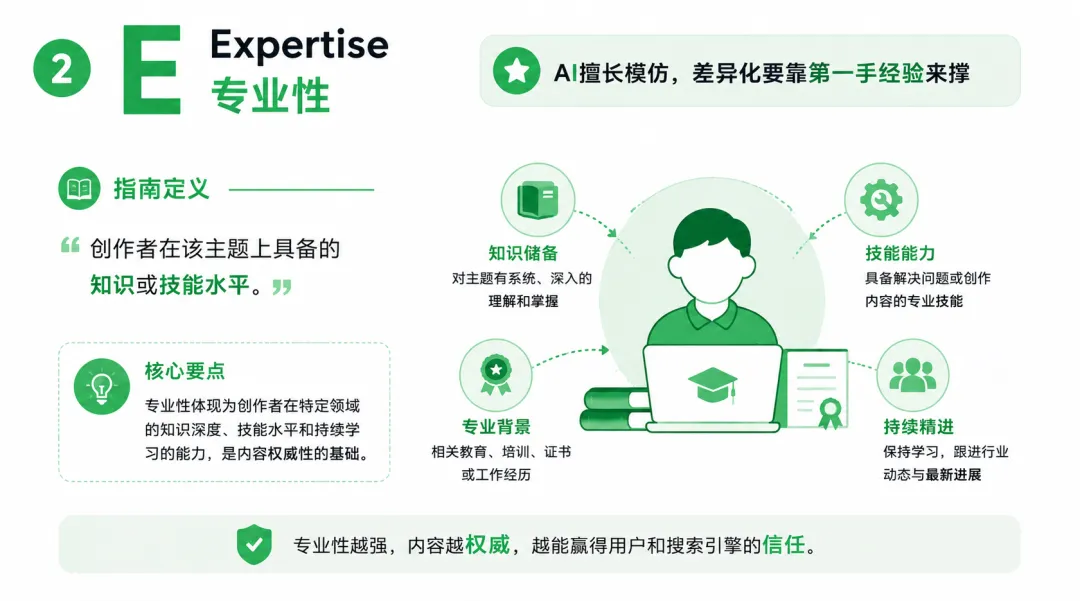
2)第二个E,Expertise,专业性;
指南的定义是:创作者在该主题上具备的知识或技能水平。
AI擅长模仿专业性内容,差异化内容要靠第一手经验拉开差距
E-E-A-T里AI最容易复制的是专业性,因为AI本身用来练习的资料就是各种专业的知识库,如果你只做专业性内容很与别人拉开距离。
豆包天然更喜欢第一手经验的内容,也就是Experience,纯经验也不行,最好你的内容是专业化的第一手内容。
同样写私域运营,一篇是框架介绍,另一篇是”帮客户做了三个月,复购率从12%涨到31%,踩了这几个坑”,放在豆包面前哪个更可能被引用,不难判断。知道框架是专业,用框架做出过结果是第一手经验,叠在一起才有分量。
写的时候框架逻辑要经得起推敲,同一概念不要换着叫法,洞察要比跟风的人快半步,慢了是重复,快了才有记忆点。
懂得专业是什么,下一个问题是:在这个行业里,凭什么是你说的算?
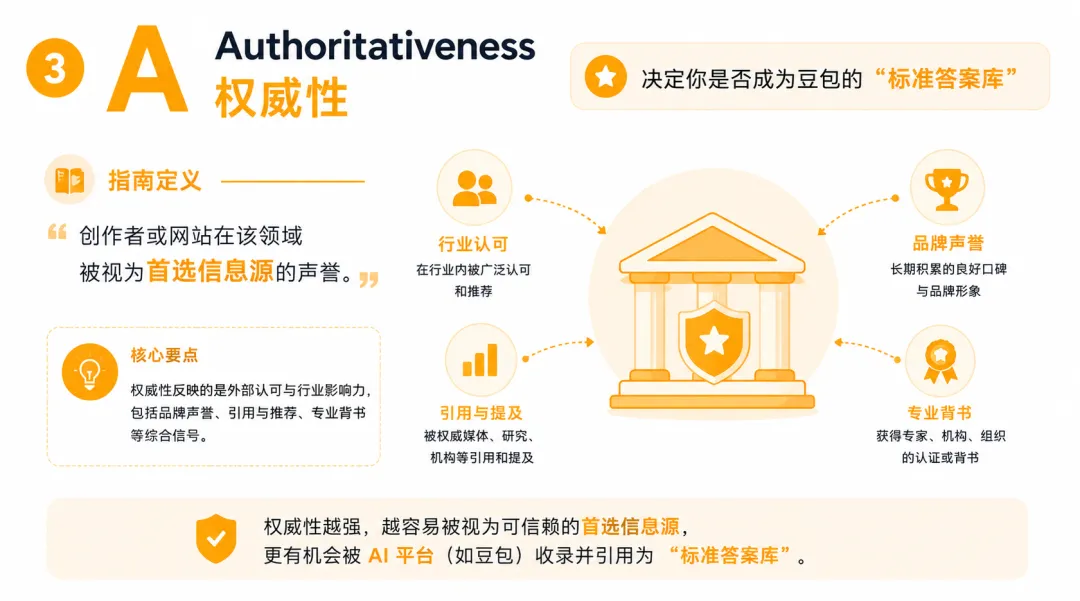
第三个A,Authoritativeness,权威性:
决定你是否成为豆包的”标准答案库”
指南的定义是:创作者或网站在该领域被视为首选信息源的声誉。
很多人搞错一个逻辑:权威性不是自己说的,是别人怎么引用你说的。
官网写”行业领先”不是权威性,行业报告引用了你的数据才是。
被引用这件事本身,就是权威性积累的方式。
在一个垂直方向上持续输出,比什么热点都追有效。
被行业媒体、头部账号引用,是建立权威性最直接的路径。
客座文章、联合出品,是在多个平台建立存在感的方式,某个平台规则变了,还有其他地方的积累在。
前三项都做到了,最后这关才是整个框架真正的地基。
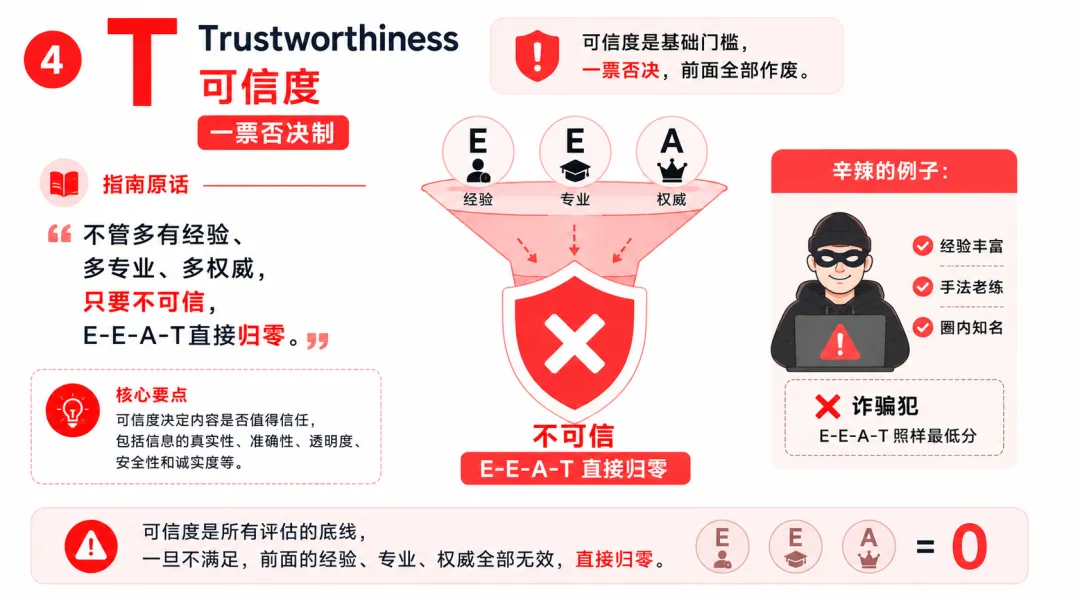
4)第四个T,Trustworthiness,可信度:一票否决制
指南原话:不管多有经验、多专业、多权威,只要不可信,E-E-A-T直接归零。举的例子很辛辣:一个经验丰富、手法老练、圈内知名的诈骗犯,E-E-A-T照样最低分。
AI时代,T多了一个新的风险来源。不是你主动做错了什么,是你什么都没做,别人替你说了错的话。品牌内容缺位就是信息真空,AI用它能找到的填进去,准不准确不会主动核查。这才是最难防的。
要守住T,官方内容要持续更新,价格、参数、政策类信息标注发布时间;作者真实署名,不要写”编辑部”;核心观点有出处;标题不过度夸张,夸张是可信度最直接的减分项。
最后说一下很多人担心的AI工具问题。
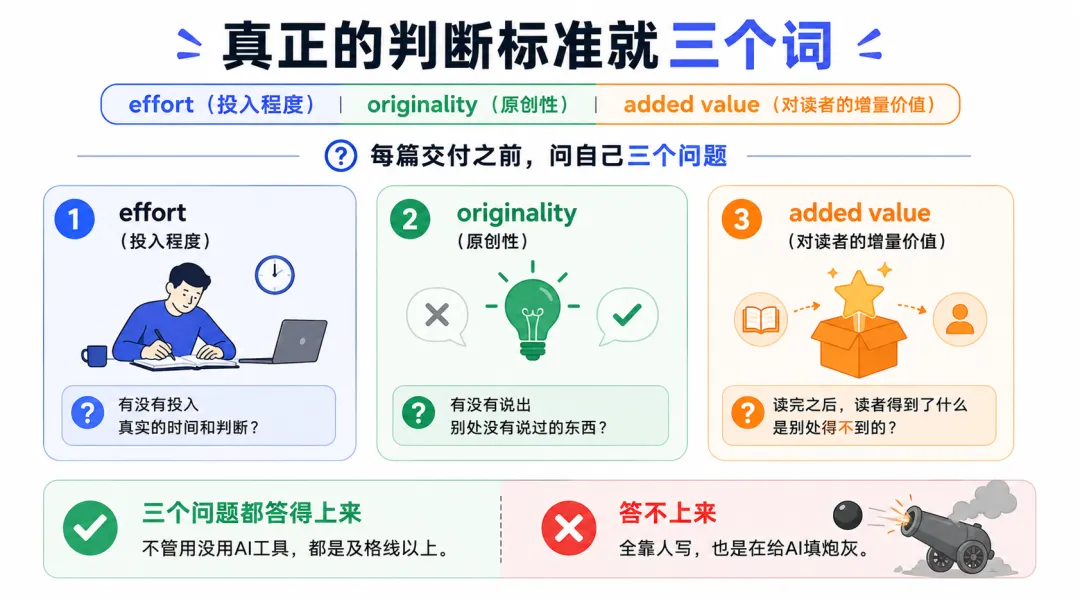
谷歌指南的立场很克制:用AI工具本身不决定内容质量,
真正的判断标准就三个词,effort(投入程度)、originality(原创性)、added value(对读者的增量价值)。
每篇交付之前问自己:有没有投入真实的时间和判断?有没有说出别处没有说过的东西?读完之后读者得到了什么是别处得不到的?
三个问题都答得上来,不管用没用AI工具,都是及格线以上。答不上来,全靠人写,也是在给AI填炮灰。

GEO内容生产6大建议
知道了E-E-A-T的筛选逻辑,下一个问题是:具体怎么做?
新榜智汇今年1月到3月对今日头条上被豆包引用的9012篇文章做过一次大规模实测,数据给出了几个直接可以用的实操结论。
第一,文章逻辑自洽、信息准确可靠,比账号粉丝数和爆款数据更影响AI引用。
粉丝数、获赞数与引用次数相关性几乎为零,甚至为负。
点赞、转发、收藏、阅读量,与引用次数的相关性全部接近0。
豆包不关心你有多火,它评估的是文章逻辑是否自洽、信息是否准确可靠。
第二,1000到2500字的中篇,每段有独立结论,比文章字数长短更重要。
实测数据显示字数和引用次数相关性几乎为0,被引用最多的是1000到2500字的中篇,占所有被引文章的50%。
AI截取内容是片段式的,每个段落有独立成立的结论句,能脱离上下文被直接引用,才是真正有收录价值的内容结构。

第三,标题要含有用户真实问题的关键词,AI才能匹配上。
目前数据里相关性最高的因素,是标题与用户问题的关键词匹配度,系数0.227。
很多人习惯写覆盖所有相关搜索的”大而全”标题,但实测结论是精准比全面更有效。
谷歌指南也明确写了,最高质量的页面标题要能准确概括页面内容,不夸张、不误导。给AI看的标题逻辑和给人看的不同,前者要的是匹配,后者要的是吸引。
第四,在专业测评和深度分析类内容上,个人认证账号比大号更有优势。
整体上认证类型对引用次数没有显著影响,但在专业测评、深度分析类问题上,个人认证达人表现更好;
在行业资讯、消费盘点类问题上,新闻媒体号更受青睐。
这和谷歌指南里Authoritativeness的逻辑一致,权威性是场景绑定的,不是全局通用的。

第五,内容发布在豆包、元宝、文小言各自对应的生态平台,是进入引用池的基础前提。
各家AI优先抓取自己生态内的内容:豆包背靠字节跳动,今日头条、头条号是天然内容池;腾讯元宝优先覆盖公众号、视频号;
百度文小言以百家号和知乎为核心信源。想在豆包出现,今日头条优先;想在元宝出现,公众号是核心;
想在文小言出现,百家号和知乎都要布局。
单平台孤注一掷风险高,某家AI引用偏好变了,曝光就清零,多平台同步是更稳的做法。

第六,在一个垂直方向持续发布,比单篇爆款更容易让AI对你形成稳定认知。
单篇被引是偶发事件,在某个垂直方向持续发布足够多的内容,AI才会在这个话题上对你建立稳定的认知。
垂直比宽泛更容易建立权威性,这一点谷歌指南和新榜智汇的数据指向的是同一个结论。

结语
新榜智汇的实测已经说清楚了:阅读量、转发数、点赞数,跟豆包引不引用你,相关性接近0。
你冲出来的爆款,在AI眼里和一篇普通文章没有区别。
内容营销的评分体系正在换一套标准,但大多数团队交给客户的月报还停在上一个时代。
现在可以做的第一件事,不复杂:打开豆包,搜一下你客户的品牌名,看看豆包说了什么、引用了谁、说对了没有。
搜完之后优先级自然就清楚了。
【参考资料】
01《2025谷歌搜索质量评估指南》
02《AI智能助手的SEO策略变革研究报告》
03《颠覆认知!豆包引用文章,和“大V、爆款、长文”统统无关》
如果你感兴趣可以私信回复“01”获取原版谷歌搜索质量评估手册。





