市场状态自适应的持续学习投资组合管理
引子:训练好的策略,为什么会”过期”?
做过量化的人,大概都经历过这样一幕:回测里光鲜亮丽、夏普轻松上 2 的策略,上线之后净值曲线却一路向下,仿佛市场专门和你作对。这背后有个被反复讨论的名词——阿尔法衰减(alpha decay)。
阿尔法衰减的逻辑并不复杂:当一个可盈利的策略被越来越多的资金复制、套利,它带来的超额收益就会被市场逐渐”吃掉”。这恰恰是有效市场假说(EMH)所预言的——市场会不断适应并消化掉任何稳定的盈利模式。
更麻烦的是,金融市场本身高度非平稳。它不是一条统计性质恒定的时间序列,而更像一台不断”换挡”的机器:牛熊切换、波动率骤升骤降、宏观事件冲击……每一次结构性变化,都会让收益分布和资产间相关性发生迁移。我们把这些”在一段时间内统计性质相对稳定”的时段称为一个市场状态(regime)。一个在低波动牛市里训练出来的策略,被原封不动地丢进高波动熊市,失效几乎是必然的。
那么传统做法是怎么应对的?常见的有两类。
一是滚动窗口重训练(rolling-window retraining):每隔一段时间,用最近一个窗口的数据从头训练一个新模型。问题在于,每次都”推倒重来”,计算成本极高;而且把之前辛苦学到的知识全扔了,等于每次都在”失忆”中重新开始。
二是朴素的在线微调(naive online fine-tuning):在旧模型基础上,用新数据继续训练。这听上去更省力,却会撞上深度学习里一个经典难题——灾难性遗忘(catastrophic forgetting):模型在适应新数据的同时,会迅速忘掉旧状态下的有效经验。结果是”学了新的、忘了旧的”,当市场状态再度循环回来时,它依然手足无措。
持续学习(continual learning,CL)提供了一条更优雅的思路。它的目标,是让一个系统能在一连串任务上不断学习,逐步积累并迁移知识:既不灾难性遗忘旧知识,又能快速适应新任务。这套范式在很多非平稳场景里已经展现出价值,但把它系统性地用到投资组合管理(portfolio management,PM)上,此前一直少有人深入。原因之一,是现有方法大多没有利用金融市场两个非常独特的性质:由市场状态驱动的动态,以及市场状态的复现性(同一类状态会反复出现)。
下面要介绍的 ReCAP(Regime-aware Continual Adaptive Portfolio management,市场状态感知的持续自适应投资组合管理),正是沿着这条路给出的一套完整方案。它的核心主张可以浓缩成一句话:把投资组合管理当成一个持续学习问题来做,让智能体在市场不断换挡的过程中,持续检测状态、积累专长、并按需复用。
一、先把问题说清楚:把投资组合管理写成一个 MDP
在动手设计方法之前,得先把”投资组合管理”这件事用数学语言精确描述出来。
基本符号方面,设市场里有 个可交易资产。在每个时间步 ,市场观测记为 ,其中 是资产 的特征向量(例如 OHLCV 与各类技术指标)。组合的资金配置用权重向量 表示, 是分配给资产 的资金比例, 对应无风险现金。组合在 时刻的价值记为 。
交易智能体与市场环境的交互,可以建模成一个马尔可夫决策过程(MDP),其中 是状态空间, 是动作空间, 是奖励函数, 是状态转移, 是折扣因子。在每个时间步,智能体观测到交易状态 ,按策略 选择一个组合配置动作 ,并获得反映组合收益的奖励 。
这里有几个量化从业者熟悉的细节。状态由最新的多资产市场特征构成,记为 , 是特征提取函数, 是可选的历史特征;动作即组合权重向量,需要满足做多约束(本工作不考虑做空):
即时奖励取对数组合收益:
状态转移则由市场演化隐式决定,既受智能体动作影响,也受外部因素影响。
关键的一步,是把它升级成”持续投资组合管理”。真实市场是非平稳的,可以看作一连串市场状态的序列 ,每个 是一段统计性质相对稳定的连续时段。要点在于:状态的边界和特征,事先都是未知的。
为刻画这一点,ReCAP 把问题进一步写成一个带动态 MDP 的持续强化学习(continual RL,CRL)问题 。注意下标 :在不同市场状态 内,转移动态 和奖励函数 可能各不相同,对应着波动率或收益分布的变化。于是,智能体面对的是一连串彼此相关、但最优策略会随状态切换而漂移的 PM 任务。
整个 CRL 过程在”适应”与”部署”之间交替进行:一旦检测到状态边界,智能体就在刚刚结束的状态 上(用其专属的 )训练,得到适应后的策略 ;随后把它部署到下一个状态 上做配置决策,直到下一次状态切换被检测到。最终的优化目标,是整个时间跨度上的累计组合收益最大化:
其中 表示在 中使用的策略, 是状态 内的交易步数, 是该状态专属动态下的奖励。
这个公式看似朴素,却把三个核心挑战逼了出来:其一,如何实时检测并切分状态切换?其二,如何在不付出过高算力与存储代价的前提下,保留并复用状态专属的经验?其三,如何动态融合历史知识与新学到的知识,实现对新状态的快速适应?ReCAP 的三个模块,正是分别冲着这三个问题去的。
二、方法总览:ReCAP 的两阶段架构
ReCAP 的整个工作流分成两个阶段:预训练(pretraining)与持续交易(continual trading)。
预训练阶段先在覆盖长时间跨度的大量历史数据上,用标准强化学习算法训练一个基础策略,其参数记为 。这一步是离线的,目的是让智能体先掌握市场的”通识”。接着,自适应状态检测模块(ARD)分析历史数据,找出结构性变化点,把数据切分成若干市场状态 。对每个检测出的状态 ,以基础策略 为起点做微调,得到适应该状态的策略 ,并定义一个策略向量(policy vector)。所有这些向量汇集成策略库(policy library),存起来以备复用。
持续交易阶段则是在上线之后,框架持续监控市场,并实时运行 ARD 检测状态切换。一旦发现状态边界,就用刚结束的那段数据做适应,产生一个新的策略向量 ,供后续交易使用。
具体地,在每个时间步 :策略网络接收资产级的交易状态 ,而状态门控模块(RGM)接收一个市场级的状态特征向量 (由市场指标和聚合后的资产信息构成)。RGM 输出一组在策略库(以及适应期内的当前状态向量)上的权重 。于是 时刻的有效策略参数被组合为:
其中 是当前状态正在学习的策略向量, 初始化为零。组合权重 则由策略网络输出经 softmax 归一化得到:
这里 是由组合出来的参数 决定的策略网络。
整套设计里最关键的一点是:训练时只更新 RGM 的参数 和当前状态向量 ,而基础策略 与策略库 始终冻结。这正是它对抗灾难性遗忘的”机关”——已经学好的知识被锁住,不会在新一轮训练中被覆盖。训练结束后,新向量 会按一定规则自适应地并入策略库,知识就这样一点点积累下来。
测试时,ARD、RGM 与基础策略 、策略库 协同工作,为每个状态实时生成动态的策略参数,再算出组合权重。这种结构既支持高效的零样本推断,也能稳健地适应不断演化的市场状态。
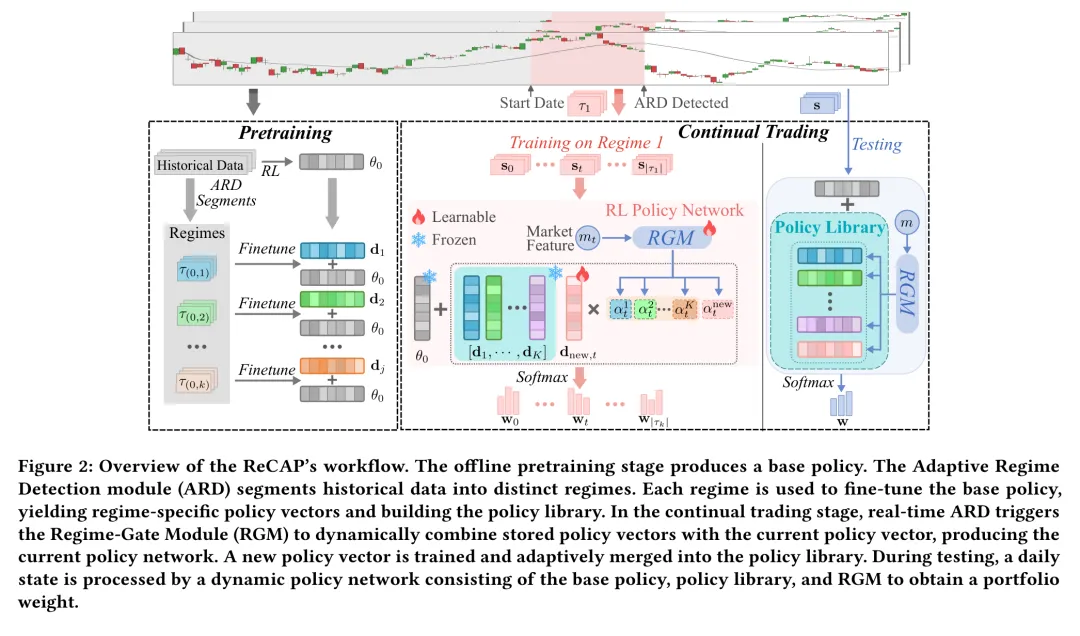
图: ReCAP 的整体工作流——离线预训练产出基础策略;ARD 把历史数据切分为不同市场状态,每个状态用于微调基础策略、得到策略向量并构建策略库;持续交易阶段由实时 ARD 触发 RGM,动态组合库中向量与当前向量,生成当前策略网络。
接下来逐一拆解三个模块。
三、模块一:自适应市场状态检测(ARD)
持续投资组合管理的第一道关,是把市场切分成一个个状态。切得准,智能体才能把适应”定位”到正确的时段,进而沉淀出状态专属的专长。ARD 要做的,就是把市场分割成若干”动态近似平稳”的区间。
形式化地说:给定一段长度为 的市场观测序列 ,目标是把它划分成 个状态 ,每个 对应一段动态近似平稳的时间区间。记 为 时刻的市场级特征向量(包含 VIX、湍流度 turbulence、以及聚合资产统计量等指标)。这样,状态检测就归结为寻找一组变化点(change points),使得 的分布在每个 处发生显著改变。
ARD 采用累积和(CUSUM)算法的一个变体,来捕捉所选市场特征分布上的突变。对某个对状态敏感的标量特征 ,统计量定义为:
其中 是从历史参考窗口估出的参考均值, 是一个控制检测灵敏度的漂移参数(drift parameter)。
这个递推式其实很好理解:每来一个新观测,就把它相对参考均值的偏离 累加进 ,同时减去一个”容忍量” ;外层的 保证统计量不会跌破零。只要市场维持在参考分布附近,偏离正负相抵、再被 压一压, 就会贴着零附近徘徊;而一旦发生持续性的同向漂移(典型的状态切换信号),偏离不断同号累积, 就会被快速推高。当 超过预设阈值 时,就判定发生了一次状态切换。每检测到一个变化点后,统计量重置为零,并在后续参考窗口上重新估计 。
单一特征容易漏报,所以上述过程会在多个特征上并行运行,并把各特征检测到的变化点取并集作为最终切分依据:
其中 是 中市场级特征的集合, 是特征 上检测到的变化点集合。
拿到变化点集合 后,市场数据就被切成:
每个状态 都被当作一个独立任务,用于状态专属的策略适应。值得强调的是:在持续交易阶段,ARD 是在线运行的——它逐步更新统计量 ,一旦命中变化点就即时标记出一个新状态。这种”边走边切”的能力,正是 CRL 设定下不可或缺的。用 CUSUM 而非更复杂的检测器,是一种工程上的务实选择;后文的稳健性实验会说明,把它换成基于 BIC 的隐马尔可夫模型,结论也基本不变。
四、模块二:策略向量与策略库
这是整套方法里相当巧妙的一块,它借鉴了模型编辑(model editing)与任务算术(task arithmetic)的思想。
对每个检测出的状态 ,把策略参数初始化为 ,在该状态的数据上微调得到 。策略向量被定义为这两者之差:
直觉上, 刻画的是”从通识策略 出发,要适应状态 ,需要往参数空间的哪个方向走、走多远”。它是一个增量(delta),而不是一份完整的策略。这一点和大模型里 LoRA、任务向量的思路相通:与其为每个市场状态存一整套网络权重,不如只存这个紧凑的”适应方向”。
所有这些向量构成策略库 , 是策略参数空间的维度。它最妙的性质在于:对多个策略向量做线性组合,就能复用此前各个状态学到的策略。这给持续适应留出了巨大的灵活性——新状态不必从零学起,很可能只是旧状态的某种”配方”。
如果来一个状态就塞一个向量,库会越长越臃肿,既浪费存储又引入冗余。ReCAP 用一套基于相似度的自适应合并与剪枝机制来动态维护。预训练阶段生成全部策略向量后,计算两两之间的相似度;若 与 的相似度超过阈值 ,就把它们平均合并:
此外,那些 范数极小的”无信息”向量会被直接丢弃——它们对适应几乎没有贡献。
到了持续交易阶段,当一个新状态出现、学到新向量 时,先把它临时加入 ,然后看两件事:如果 RGM 分配给 的平均权重接近零,或者它的 范数很小,就把它丢弃。这背后的含义是,这个新状态并不需要在基础策略和已有库之外做多少额外适应,已有向量的某种组合就够用了。反之, 会按和上面相同的相似度准则,与库中已有向量合并。这套机制有效压低了冗余,确保策略库只保留那些彼此区分、确有用处的状态适应。
把它和持续学习的语言对上号:冻结 与 、只在外围增量上动手,本质上是一种参数隔离(parameter isolation)/架构型的持续学习思路;合并与剪枝则是对”记忆”的主动管理,避免库无限膨胀。这就同时回答了前面的第二个挑战——如何低代价地保留并复用状态专属经验。
五、模块三:状态门控模块(RGM)
有了一柜子”适应方向”,还需要一个聪明的”调度员”,在每个时刻判断当前市场更像哪些历史状态,并据此把库里的向量按合适比例调出来用。这个调度员就是 RGM。
在每个时间步 ,把市场级特征向量 送进一个由 参数化的神经网络,经 softmax 得到一组权重:
其中 是策略库上的注意力权重向量, 是库中向量的个数。推断时,当前策略参数被组合为:
熟悉混合专家(mixture-of-experts)的读者会觉得这套机制很亲切:库里每个策略向量是一个”专家”,RGM 就是那个根据上下文(此处是市场级状态特征)动态分配权重的门控网络。区别在于,这里组合的不是专家的输出,而是专家在参数空间里的”适应方向”,组合完再形成一张可用的策略网络。
训练时还有个细节:在每个状态上训练时,RGM 的输出头会先扩张,额外输出一个对应当前状态向量 的权重 。如前所述,只有门控参数 和当前状态向量 会被强化学习更新, 与 保持冻结。训练完成后, 按第四节的规则并入 ;如果它被判定该丢弃,RGM 的输出头就剪枝回去,只为库中已有向量输出权重。
至此,前面的第三个挑战——如何动态融合历史与新知识、快速适应新状态——也由 RGM 给出了答案。三个模块各司其职、又彼此咬合:ARD 负责”何时切”,策略库负责”存什么”,RGM 负责”怎么用”。
六、把流程串起来:两段算法骨架
为了让整个机制更具体,这里把两个阶段的算法骨架梳理一遍。
预训练的输入是历史数据 ,输出基础策略 与策略库 。第一步,用标准强化学习算法在全量历史数据上训练 ;第二步,用 ARD 检测变化点 并切分出状态 ,初始化空库,对每个状态以 为起点微调出 、算出 并加入库;第三步,对库中所有向量对,相似度超过 的合并, 范数过小的剔除。
持续交易的输入是当日数据、、库 、RGM 参数 、数据缓冲区 和 ARD 统计量 。第一步,取得 与 ,用 RGM 算权重 、组合出 、再算组合权重 ;第二步,更新 ARD 统计量 。若检测到状态切换,则进入第三步,初始化 、扩张 RGM 输出头,在缓冲区 上用强化学习更新 和 (保持 冻结);第四步做库更新——若 的平均权重或 范数过小则丢弃并剪枝输出头,若它与库中某向量相似度超过 则合并并剪枝,否则直接追加进库,最后重置 、清空缓冲区。若未检测到切换,就把 存入缓冲区,继续走下去。
整个闭环的精神,可以概括为”检测—适应—并库—复用”的循环往复。
七、实验怎么做的
实验覆盖五个数据集:美股三大基准 DOW30、NAS100、SP500;日本市场的 NIKKEI30(29 只日经成分股);以及包含 7 只主流商品 ETF 的 COMMODITY_ETF(黄金、白银、综合商品指数、原油、天然气、农产品、标普高盛商品指数)。原始数据取自 Yahoo Finance,只保留在整个区间内连续上市、数据完整的成分股,最终五个数据集分别有 29、73、398、29、7 个资产。日频数据从 2008 年 5 月 1 日到 2025 年 4 月 29 日,横跨 17 年,涵盖牛熊、金融危机、高波动等多种市场状态。前 12 年作为离线训练集,后 5 年留作在线评估。
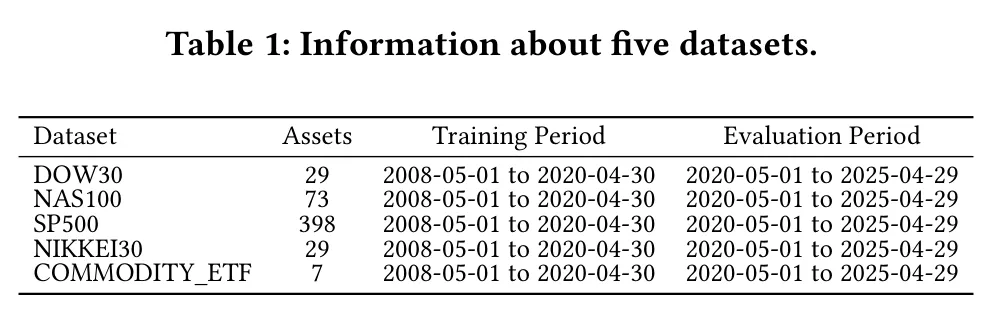
表:五个数据集的资产数量、训练区间与评估区间。
特征工程方面,原始数据是每只资产的日频开高低收价与成交量。在此基础上计算复权价、MACD、布林带以及 17 个常用技术指标,还额外引入湍流度与 VIX 来辅助状态检测。为避免前视偏差(look-ahead bias),所有预处理(含特征工程与归一化)都严格按时间序列方式进行,每个时间步只用过去和当前的信息。具体而言,资产级交易状态用到每只资产的 26 维特征:开高低收、成交量、MACD、布林上下轨、RSI-30、CCI-30、DX-30、30 日与 60 日均线、5/10/15/20/25/30 日复权价收益、归一化开高低价、复权价收益、收盘收益、VIX、湍流度;ARD 与 RGM 用的市场级输入则是 6 个对状态敏感的信号:VIX、湍流度、布林上下轨、5 日复权价收益、RSI-30。
评价指标用三个被广泛接受的金融指标:累计收益(CR)、夏普比率(SR)、最大回撤(MDD),分别刻画盈利、风险调整后盈利、风险三个侧面,默认在整个测试期上在线计算。此外,按持续学习的标准实践,还用三个基于智能体在交易不同阶段盈利的指标:平均性能(AP)、遗忘度(FG)、前向迁移(FT)。简单说,AP 衡量在所有任务/阶段上的平均表现;FG 衡量学了新状态后、对旧状态表现的退化程度(越小越好,负值代表不仅没忘还变好了);FT 衡量先前知识对新任务的助益(越大越好)。
对比基线相当全面,包括 6 个规则类方法——买入持有(B&H)、CRP、EG、UP、OLMAR、WMAMR;7 个强化学习类方法——A2C、PPO、SAC、EIIE、SARL、Cross-Insight、AlphaGAT;以及 5 个持续学习策略——滚动窗口重训练(Retrain)、持续微调(Finetune)、经验回放(ER,缓冲区 3000)、EWC 正则化微调(正则系数 1000)、约束有理激活(CoR),它们都以 PPO 为底层算法。
实现上,框架基于 PyTorch 与 FinRL 实现。每个强化学习类方法跑 10 个随机种子,报告均值与标准差。各方法的总强化学习更新预算被对齐,需要任务切分的方法在每个任务上训练 步。actor 与 critic 各为 2 层 MLP、Tanh 激活、嵌入维度 64;输入状态形如 ,其中 为批大小、 为每资产特征数、 为资产数。特征用 z-score 归一化,统一使用 Adam、学习率 ,交易成本设为每笔 10 个基点(bps)。ReCAP 的关键超参为: 取 、阈值 取 ( 为标准差)、合并阈值 。遵循近期 CRL 的做法,策略向量的学习与复用只作用于 actor,critic 在每个状态重新初始化。
八、结果:它到底强在哪
先看与各类 PM 方法的对比。在三个美股数据集上,所有方法都在完整训练期上训练、在测试期上评估,而 ReCAP 在测试期上还会持续训练(其总训练预算与其他强化学习方法对齐,以保证公平)。
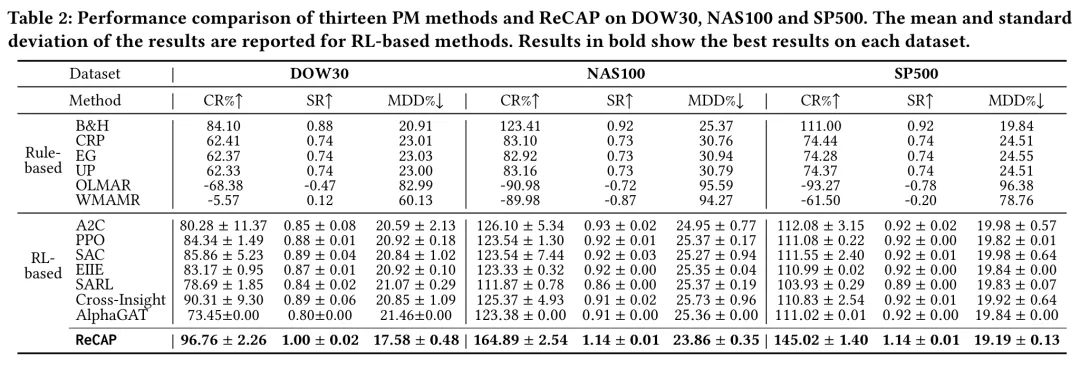
表:十三种 PM 方法与 ReCAP 在 DOW30、NAS100、SP500 上的 CR/SR/MDD 对比(强化学习方法报告均值与标准差,加粗为各数据集最优)。
几个值得拎出来的观察。规则类里,CRP、EG、UP 收益中规中矩,但受限于无法适应市场变化,回撤更高、风险调整后收益更低;均值回归类的 OLMAR 与 WMAMR 表现明显糟糕,长周期里常常巨亏,凸显了静态启发式在非平稳状态下的脆弱。强化学习类整体优于多数规则类,其中 PPO 与 SAC 颇具竞争力,PPO 在多数情形下是个标准差很低的强基线;AlphaGAT 反而较差,大概率是其两阶段 CATimeMixer 架构参数空间过大、与样本量不匹配导致严重过拟合;Cross-Insight 因为整合了多投资期限的洞见、能捕捉多尺度市场动态,在强化学习基线里表现较好。
而 ReCAP 在所有数据集上都拿到了最佳结果,相比最强基线,平均累计收益提升约 6.45% 至 38.79%;同时它还有最低的最大回撤,说明风险管理与对市场动荡的稳健性也更好。一个细节很能说明问题:在 NAS100 上做匹配口径的滚动窗口适应对比(360 天窗口、90 天重训频率、180 天最小窗口、每阶段 更新步)时,最强的自适应基线 CR 为 124.24%、SR 为 0.92,而 ReCAP 达到 164.89% CR、1.14 SR。换句话说,即便允许其他方法在线滚动更新,差距依然显著。
为直观看出差距,可以看净值曲线。
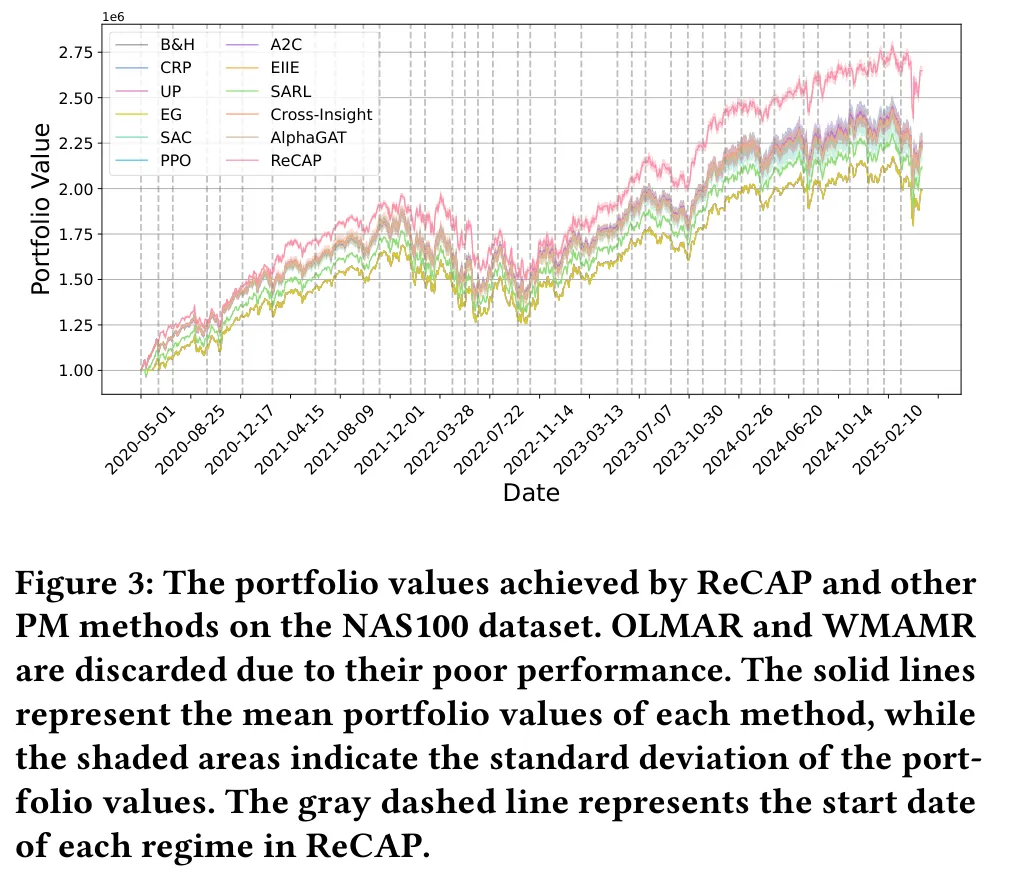
图: ReCAP 与其他 PM 方法在 NAS100 上的组合净值曲线(实线为均值、阴影为标准差,灰色虚线标出 ReCAP 中各状态的起点);OLMAR 与 WMAMR 因表现过差被略去。
从曲线能清楚看到,无论牛市还是熊市,ReCAP 都持续领先。更重要的是一个趋势:随着交易时间拉长,它通过策略库不断积累不同状态的知识,与其他方法的差距越拉越大,长周期里的超额收益优势愈发明显。这恰好印证了持续学习的核心价值——知识是会复利的。
把视角收窄到持续学习这一层,在 PPO 底座上与五种 CL 策略正面较量。
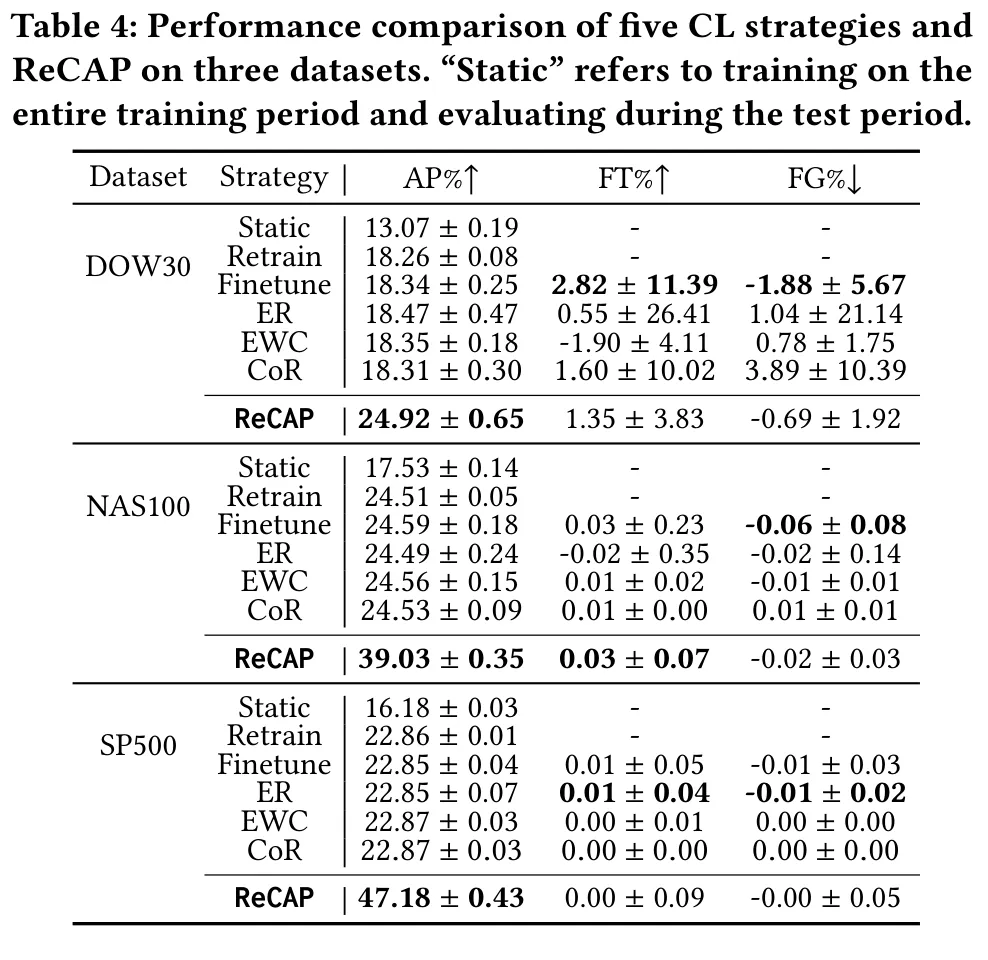
图:五种持续学习策略与 ReCAP 在三个数据集上的 AP/FT/FG 对比(“Static”指在完整训练期训练、在测试期评估)。
结论很鲜明:在三个美股数据集上,ReCAP 的平均性能(AP)都以可观的优势领先所有 CL 基线;而且随着资产数增多,差距还在扩大——在 SP500 上,ReCAP 的 AP 几乎是最佳基线的两倍,说明它在高维、复杂环境里尤其见长。在遗忘度与前向迁移上,ReCAP 也取得了相当或更优的结果。一个有意思的现象是:随着资产数增加,所有方法的 FG 与 FT 都趋近于零——这可能是因为资产一多,任务之间的独立性增强了。相比之下,Finetune、ER、EWC 相对 Retrain 并没有明显改进;ER(回放类)与 EWC(正则化类)的整体表现甚至不优于朴素 Finetune;CoR 试图通过约束优化平衡可塑性与稳定性,但它在金融领域的效果仍有待验证。这背后透露出一个判断:在线交易里的任务切分,与那些 CL 方法所假设的静态数据分布并不契合,这也正是持续投资组合管理的独特难点所在。
为弄清每个模块的贡献,在 NAS100 上和三个削弱版本对比:w/o-ARD(用固定长度窗口代替 ARD 切分)、w/o-PL(只保留并复用最近一个策略向量,丢掉积累的库)、w/o-RGM(去掉门控、改用随机权重组合策略向量)。
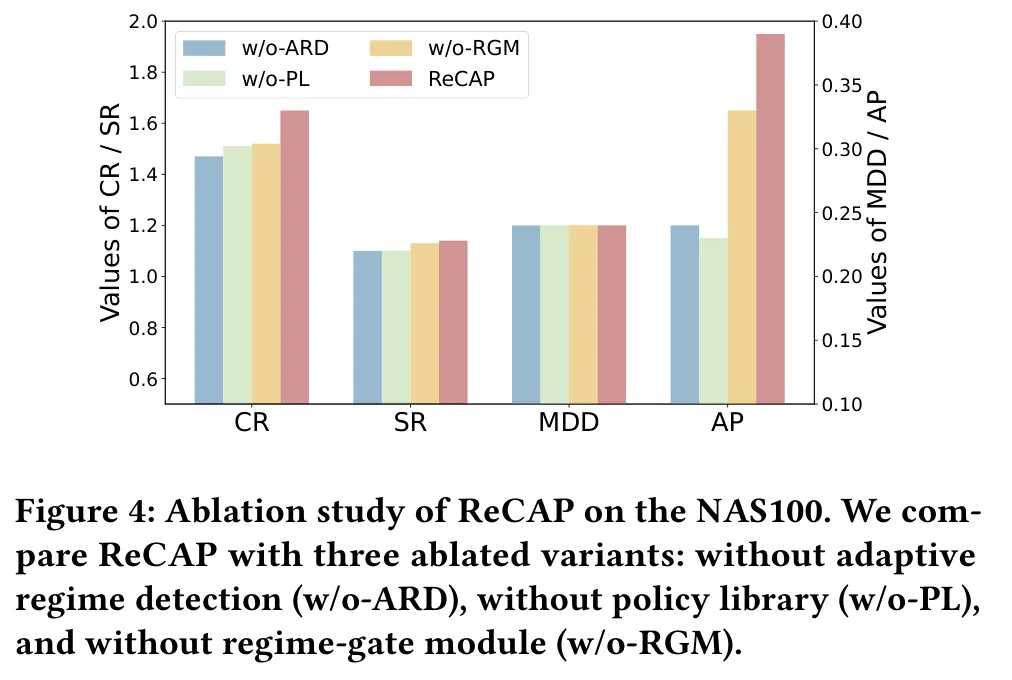
图: ReCAP 与三个消融变体(w/o-ARD、w/o-PL、w/o-RGM)在 NAS100 上四个指标的对比。
结果很有说服力:w/o-ARD 在所有指标上的下滑最大,说明准确而自适应的状态切分对持续投资组合管理至关重要——切不准,适应就对不齐真实的市场动态。w/o-PL 排在第二差,印证了策略库对”积累并复用历史知识”的关键作用,它也对应着最差的 AP。完整框架在所有指标上都最优,说明三个模块缺一不可,它们之间的协同,才让框架既能沉淀知识、又能在市场变化时把知识有效部署出去。
进一步考察 ARD 里漂移参数 与状态变化阈值 的影响( 都以标准差 的倍数给出)。
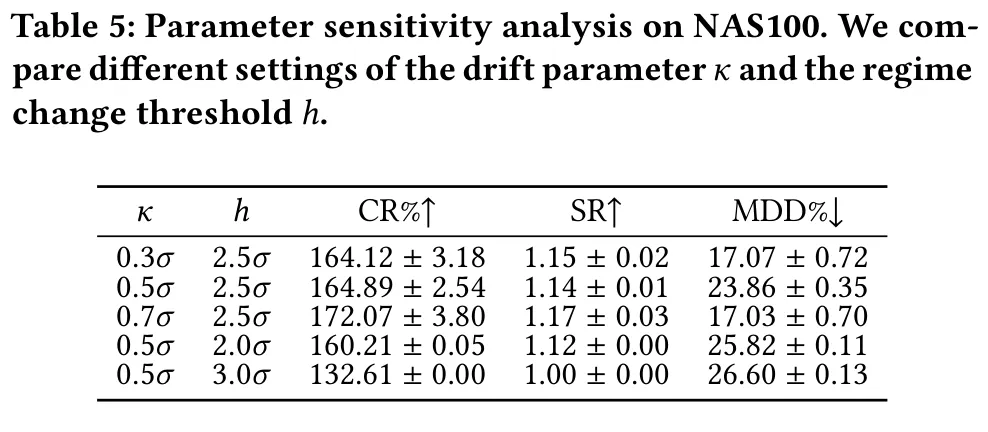
表: NAS100 上不同 与 设置下的 CR/SR/MDD,展现框架对超参的稳健性。
结论是:在相当宽的取值范围内,ReCAP 都维持着高 CR 与高 SR,对精细调参并不敏感。稳健性还体现在另外两处:把 ARD 里的 CUSUM 换成带 BIC 模型选择的隐马尔可夫模型,在 NAS100 上仍有 146.38% CR、1.10 SR、24.22% MDD,说明收益并不依赖某个特定的检测器实现;在额外 +5 bps、+10 bps 的交易成本下,ReCAP 也保持明显优势(尽管它的换手率略高于 A2C)。
还有个有意思的可解释性侧写:在 NAS100、种子 0 上追踪策略库的演化——预训练后初始库含 12 个策略向量;随后 37 个被检测出的状态里,框架共做了 10 次插入、12 次合并、15 次丢弃,最终库稳定在 22 个向量。而且最终的门控权重高度集中,前五个向量分别占总权重的 34.3%、26.1%、10.5%、10.2%、4.3%。这说明库在保持紧凑的同时,沉淀出了一小撮占主导地位、可反复复用的策略——这与我们对”市场状态会复现”的直觉高度吻合。
九、价值、边界与启示
把这套方法放回量化研究的语境里看,它最大的价值,是给”非平稳加阿尔法衰减”这个老大难问题,提供了一个结构化、模块化的工程答案:用在线变化点检测识别市场换挡,用增量式的策略向量低成本地沉淀每个状态的专长,再用门控网络按当前市场把历史专长动态调配出来。冻结底座、只动外围的设计,让它绕开了灾难性遗忘,也比”动辄推倒重来”的滚动重训练省得多。
当然,它也有清晰的边界,这些恰恰是后续可以发力的方向。其一,状态检测基于统计变化点,对细微或渐进的过渡可能不够敏感,尤其在噪声更重的高频场景;其二,当前库维护用的是余弦相似度,简单高效,但可能把参数相近、实则不同的策略错并,或把罕见却有用的状态误删;其三,门控权重虽提供了一定可解释性,但面向真实部署,还需要更强的可解释性与金融透明度;其四,实验聚焦于日频交易,推广到更高频数据仍待验证;其五,它在长周期上很能打,但在需要极快适应的短周期场景里,优势可能没那么大。
对一线研究员来说,这套思路还有几个可直接借鉴的”零件”:把任务向量与模型编辑的想法迁移到强化学习策略上,本身就是个值得复用的范式;把市场级特征单独抽出来喂给门控、与资产级特征喂给策略网络分开,是个干净的工程切分;而”检测—适应—并库—复用”的闭环,完全可以套用到其他非平稳的序列决策问题上。
十、结语
非平稳,是金融市场刻在骨子里的属性;阿尔法衰减,则是每个策略迟早要面对的宿命。与其追求一个”一劳永逸”的最优策略,不如换个思路:让交易智能体像一个经验老到的交易员那样,在市场一次次换挡中持续学习、把每一段行情的心得攒进自己的”武器库”,并在似曾相识的局面里迅速调出当年的打法。ReCAP 把这个朴素的直觉,落成了一套可检测、可积累、可复用、且经得起多市场检验的框架。对正在和非平稳市场缠斗的量化人来说,这至少提供了一个值得认真琢磨的范式。
参考文献
[1] Chaofan Pan, Lingfei Ren, Linbo Xiong, Yonghao Li, Wei Wei, and Xin Yang. Regime-Adaptive Continual Learning for Portfolio Management. In Proceedings of the 32nd ACM SIGKDD Conference on Knowledge Discovery and Data Mining V.2 (KDD 2026), August 9–13, 2026, Jeju Island, Republic of Korea. ACM, New York, NY, USA. https://doi.org/10.1145/3770855.3817620 (arXiv:2606.00143)