浏览器市场与用户画像分析-数据加工(2)
引言
本实验基于约 1000 名用户、累计 800 万条以上的浏览器使用行为日志,构建从明细数据到聚合统计表的完整 ETL 加工链路。原始数据存储于底层行为表中,无法直接用于大屏可视化——明细表数据量大、查询延迟高,且大屏各图表需要的是聚合指标而非明细行。因此,需要在数据接入大屏之前,完成多张目标统计表的加工。
整体加工策略为:以明细表 daily_browser_detail 为核心数据源,通过排序、分组、聚合、字段映射与 JavaScript 计算等组件,按业务维度逐层汇总,最终产出 7 张目标表,覆盖市场格局、使用行为、时段偏好与用户画像四大分析主题。
实验环境为助睿数智(Uniplore)平台的数据集成模块(助睿 ETL),后端数据库采用 MySQL,全程以可视化转换流方式完成零代码数据加工。

一、明细数据基座构建
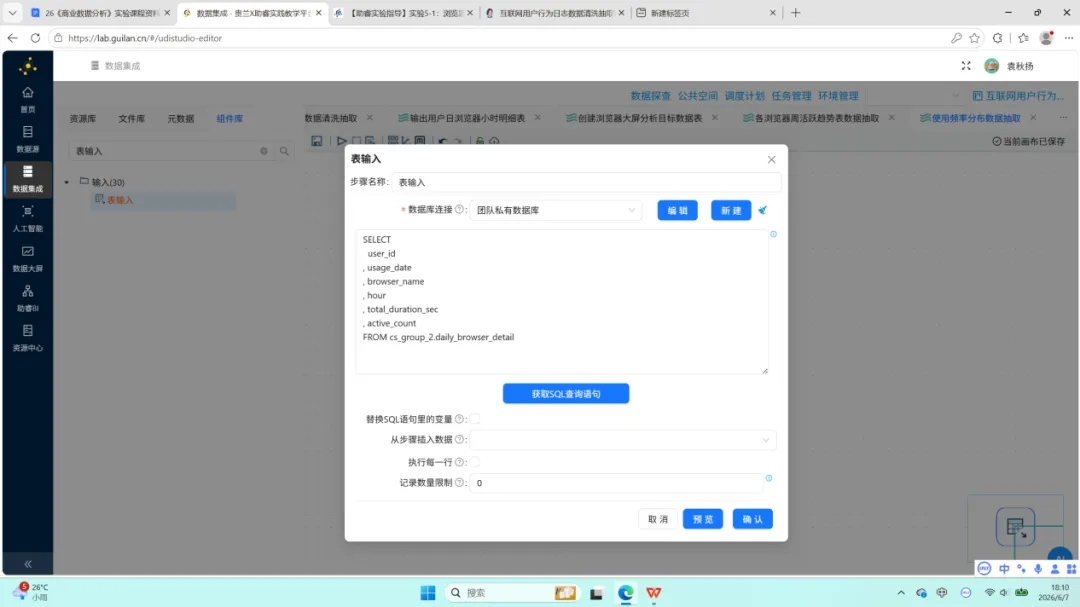
所有聚合运算均依赖明细表 daily_browser_detail,其字段结构为 user_id、usage_date、browser_name、hour、total_duration_sec、active_count。
1.1 创建明细表
在团队私有数据库中执行 DDL 语句,创建目标表。由于数据规模达到 800 万行以上,存储引擎选择 InnoDB,字符集设置为 utf8mb4 以避免中文字段乱码。
CREATETABLEIFNOTEXISTS `daily_browser_detail` (`user_id` VARCHAR(50) NOTNULLCOMMENT‘用户ID’, `usage_date` DATENOTNULLCOMMENT‘使用日期’, `browser_name` VARCHAR(50) NOTNULLCOMMENT‘浏览器名称’, `hour` TINYINT NOTNULLCOMMENT‘小时’, `total_duration_sec` INTNOTNULLCOMMENT‘总使用时长(秒)’, `active_count` INTNOTNULLCOMMENT‘活跃次数’) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;
1.2 复制并改造上游转换流
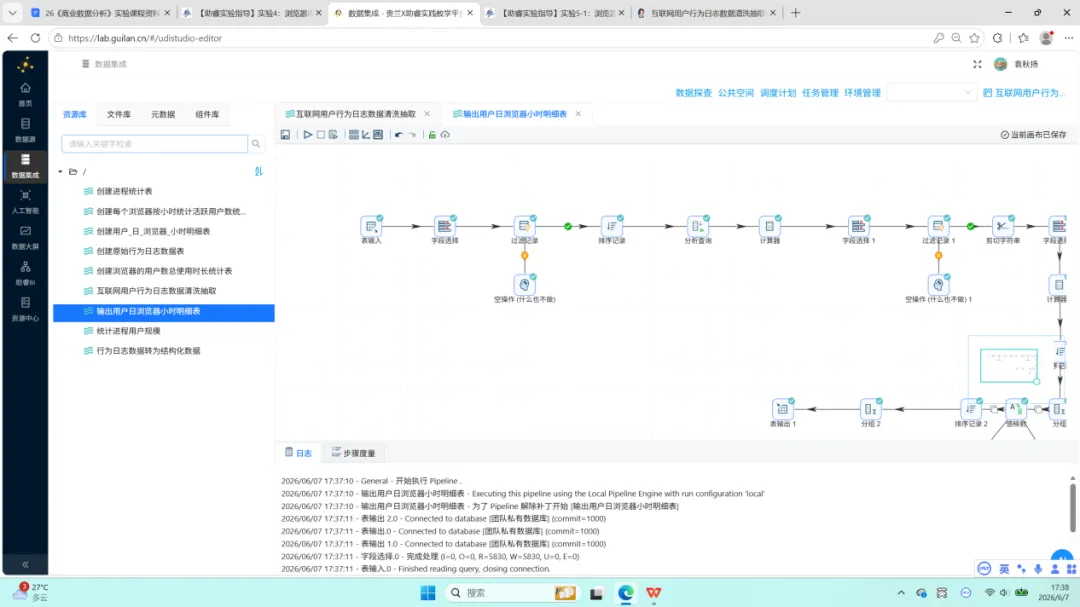
前序实验已构建”互联网用户行为日志数据清洗抽取”转换流,但其输出为两张中间聚合表。本次需要的是明细数据,因此复制该转换流并进行如下三项修改。
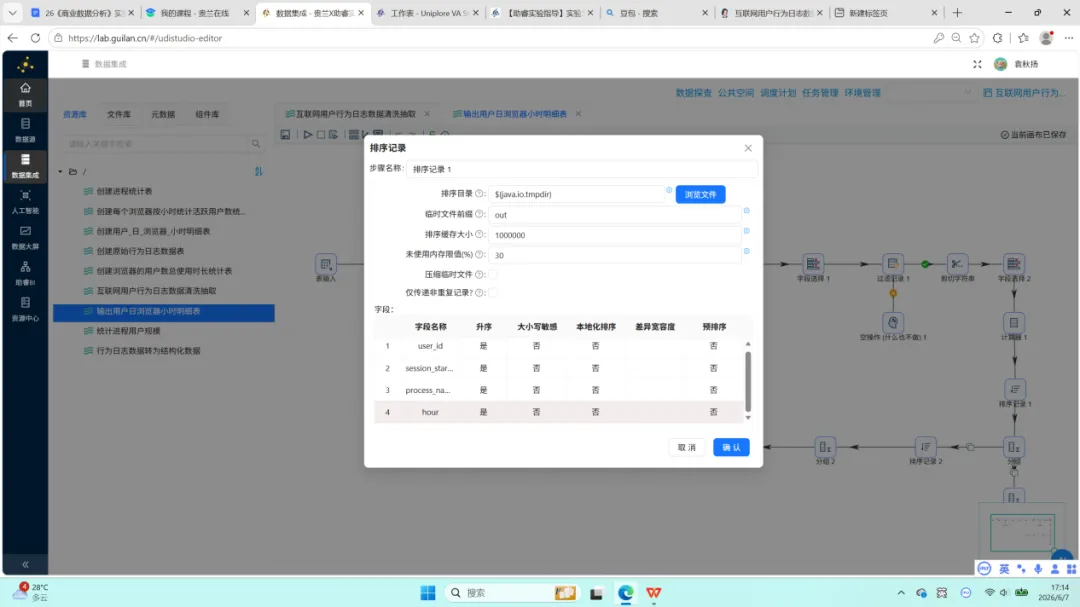
第一项:修正排序逻辑。 原流中的排序组件仅按 process_name 字段升序排列,而分组组件实际使用了 user_id、usage_date、process_name、hour 四个分组字段。排序字段与分组字段不一致会导致分组结果出现重复行,需将排序字段补全为与分组字段一致的四列。
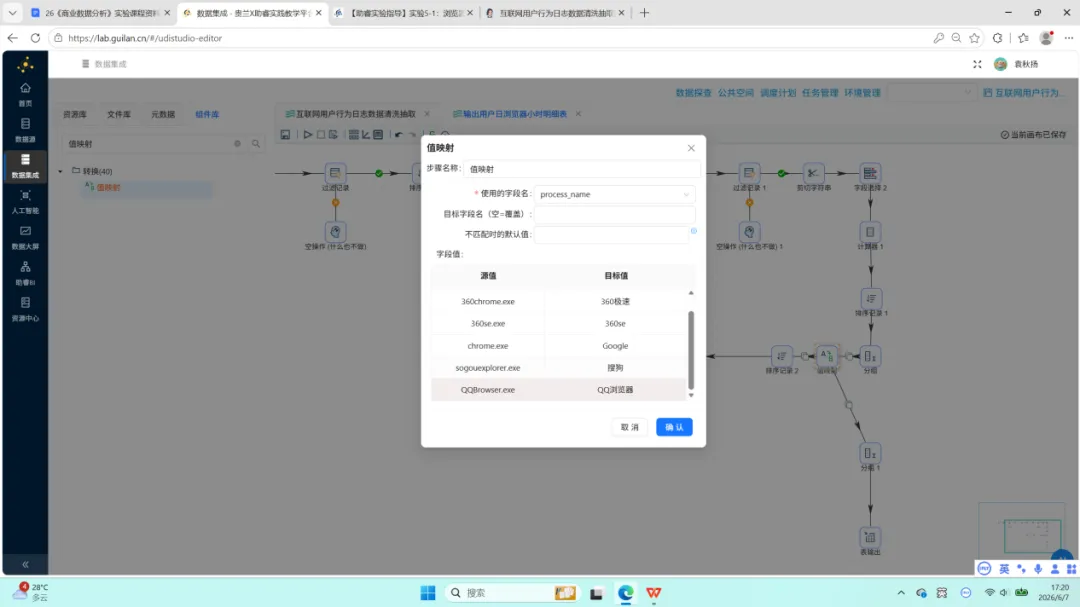
第二项:浏览器名称映射。 日志中记录的浏览器进程名为可执行文件名(如 chrome.exe、iexplore.exe),不具备可读性。在分组组件后新增”值映射”组件,将进程名映射为对应的中文浏览器名称。同时需检查上游过滤条件,确保 EXCEL.EXE、WINWORD.EXE、AlilM.exe 等非浏览器进程已被排除。
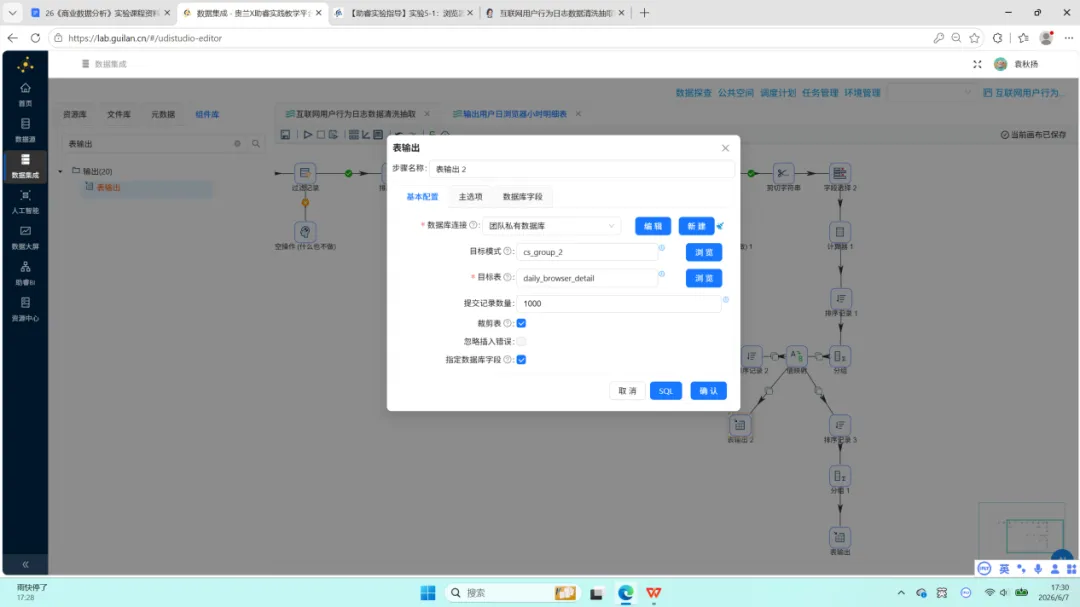
第三项:追加表输出。 在值映射组件下游添加”表输出”组件,目标表指定为刚创建的 daily_browser_detail,勾选”裁剪表”选项以覆盖模式写入。
1.3 执行转换流
点击运行按钮,转换流启动全量数据抽取。受数据规模影响,此步骤耗时较长。执行完成后,明细表基座搭建完毕。

二、目标表体系设计
在开始具体的聚合加工之前,首先批量创建全部 7 张目标表。新建一条转换流,使用”执行一个 SQL 脚本”组件,通过 DROP TABLE IF EXISTS + CREATE TABLE 语句一次性完成建表操作。
目标表清单及用途说明:
•browser_overview —— 核心指标概览,键值对结构,存储总使用时长、人均使用时长、活跃用户占比、重度用户占比
•browser_weekly_active —— 各浏览器周活跃趋势,按周维度统计活跃用户数
•browser_frequency_stats —— 浏览器使用频率分布,按轻度/中度/重度三个等级划分
•browser_multi_usage —— 用户使用浏览器数量分布,统计 1 种/2 种/3 种及以上的用户分布
•browser_weekday_weekend —— 浏览器工作日与周末使用对比
•user_profile_stats —— 用户画像统计,按性别、年龄、学历、职业、收入、居住地类型、省份等维度交叉汇总

三、逐表加工流程
3.1 各浏览器周活跃趋势表
加工链路:表输入 → 字段选择 → 值映射 → 排序 → 分组 → 表输出
各步骤要点:
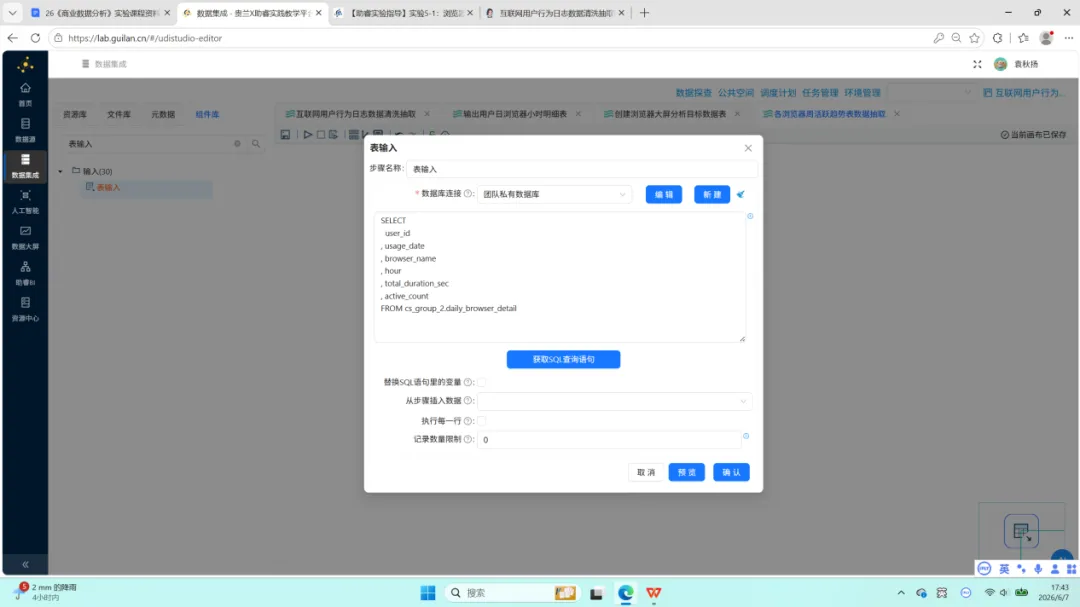
1.表输入:读取 daily_browser_detail 全部字段。
2.字段选择:将 usage_date 元数据类型设置为 Date,格式为 yyyy-MM-dd,为后续日期到周的映射做准备。
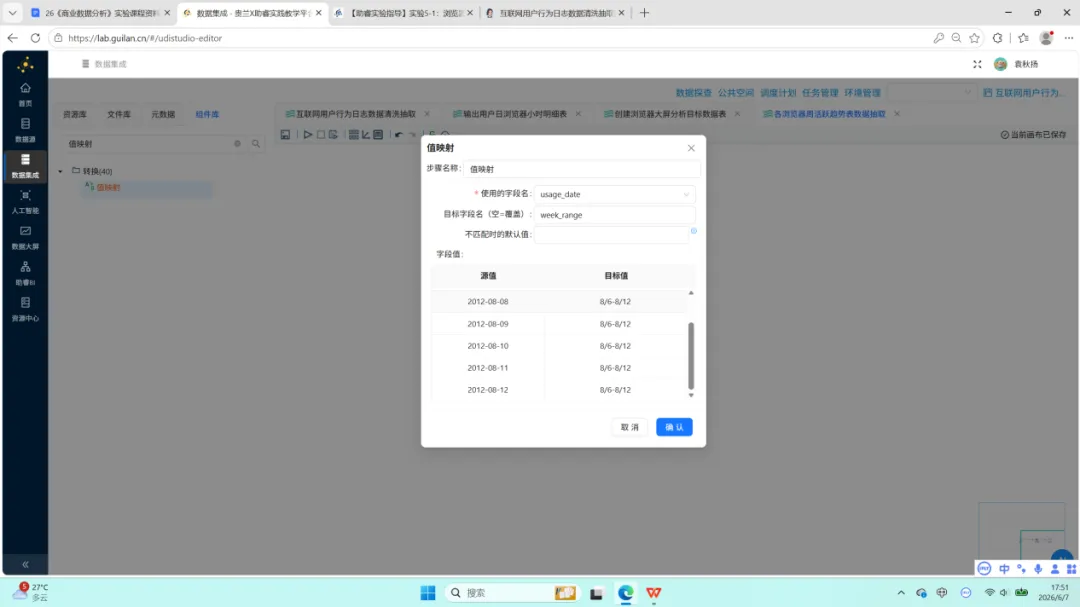
3.值映射:将每条记录的 usage_date 映射为对应的周区间标签(如 “5/7-5/13″)。目标字段命名需独立创建(week_range),不应覆盖原日期字段。
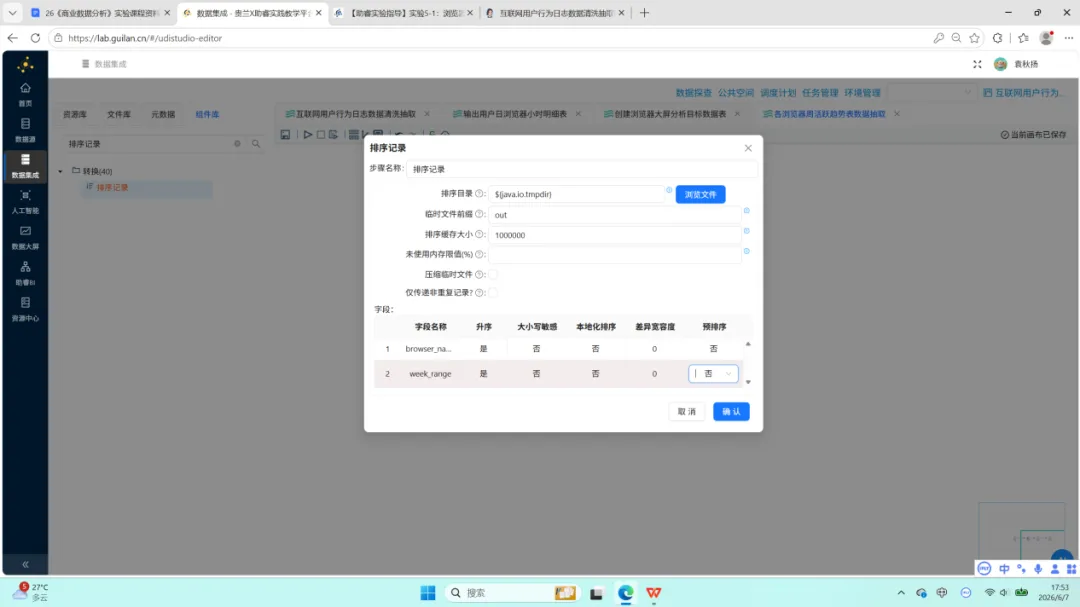
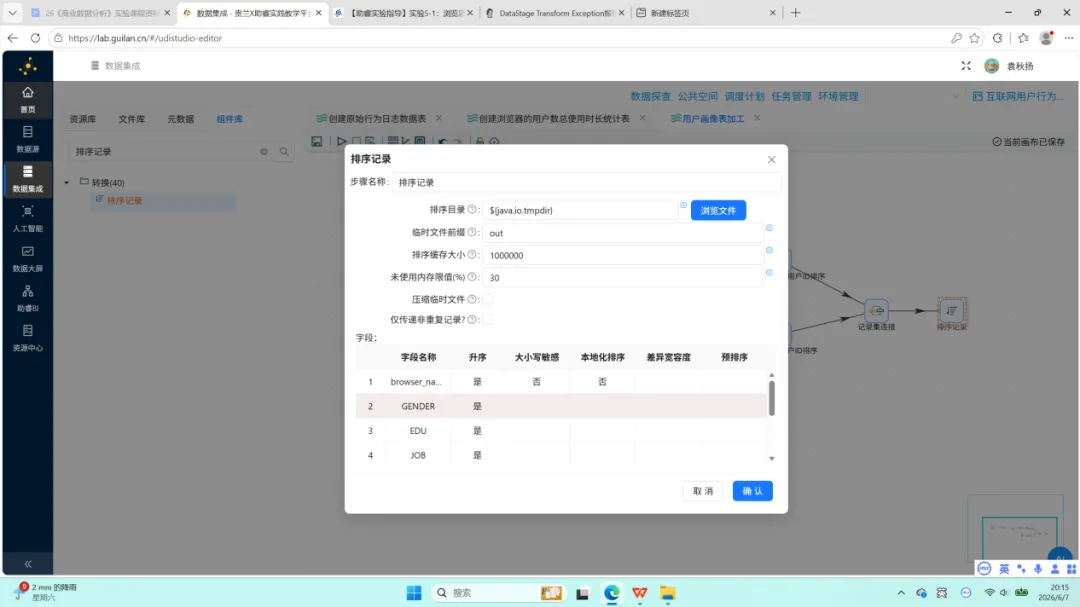
4.排序:按 browser_name 与 week_range 升序排列。分组操作前执行排序是保证去重计数正确性的必要条件。
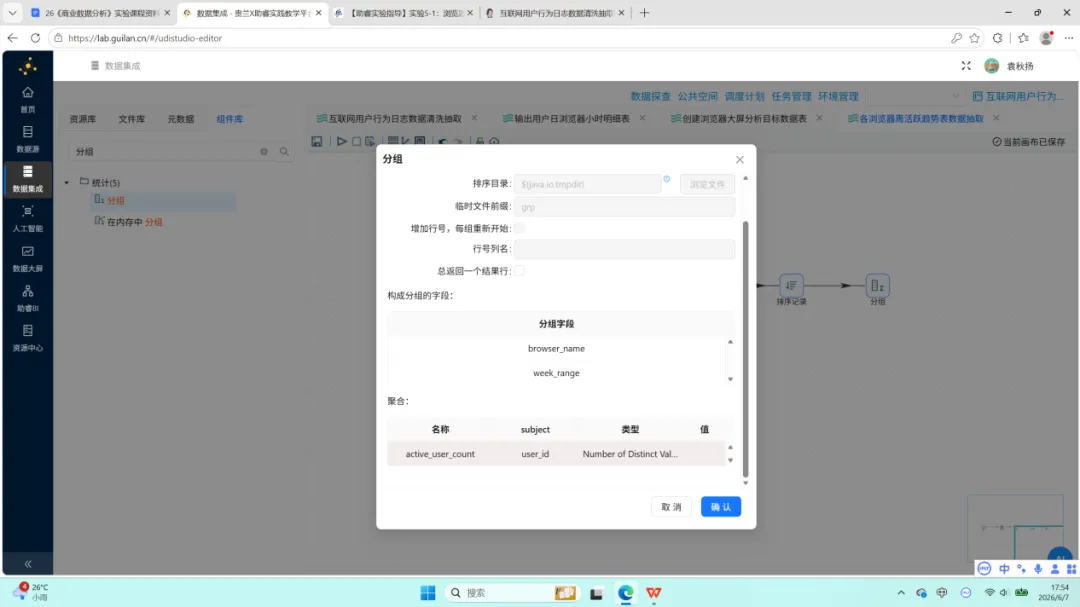
5.分组:分组键为 browser_name 与 week_range,对 user_id 执行去重计数,得到字段 active_user_count。
6.表输出:以裁剪表模式写入 browser_weekly_active。
3.2 各浏览器使用频率分布表
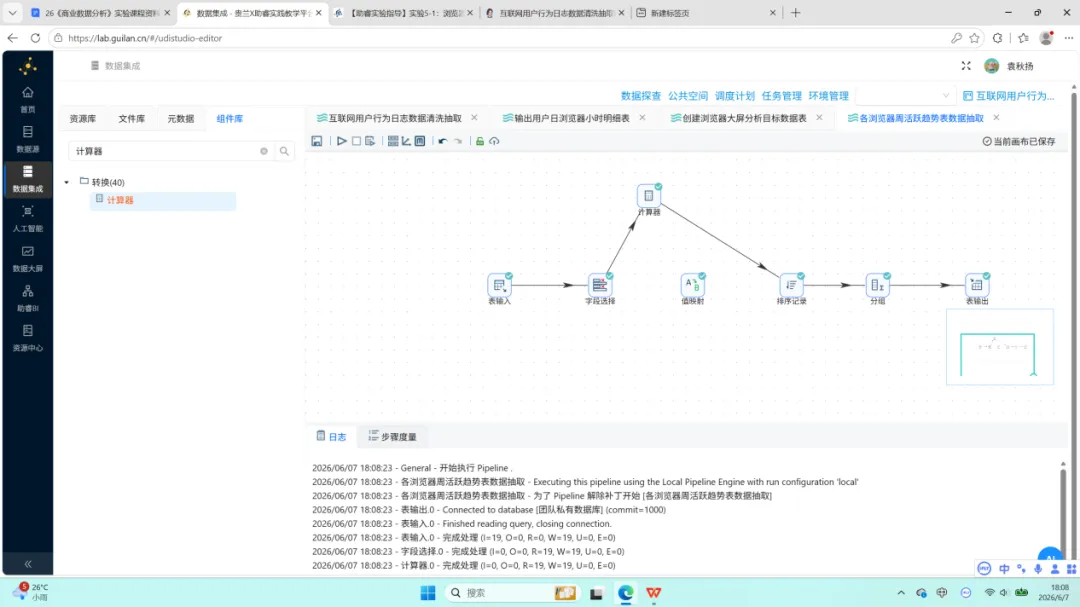
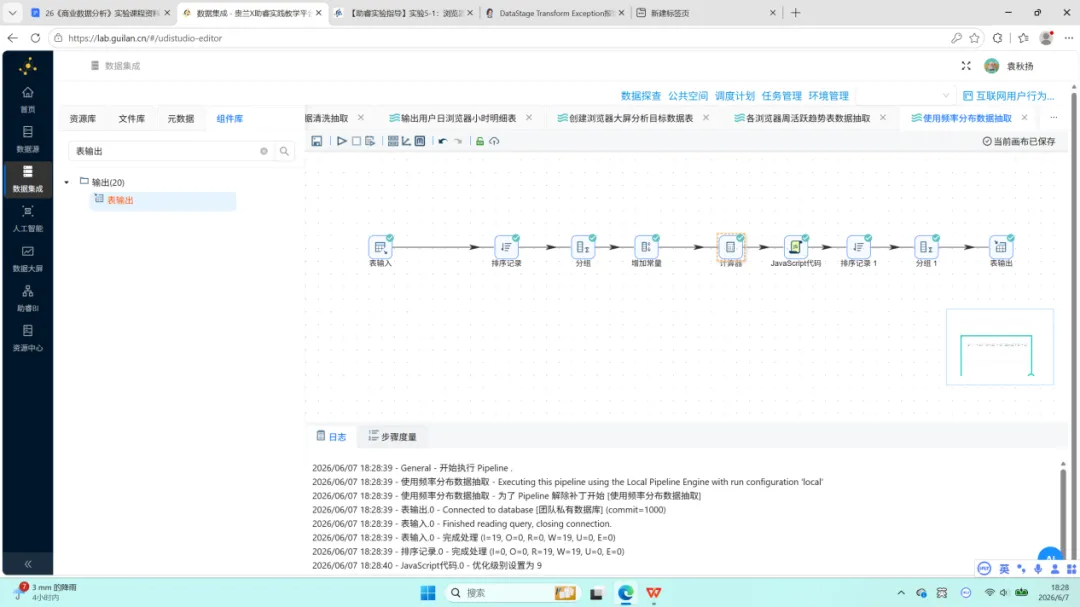
本转换流为全部加工链路中组件数量最多的一条,完整链路为:
表输入 → 排序 → 分组 → 增加常量 → 计算器 → JavaScript → 排序 → 分组 → 表输出
加工步骤:
1.读取明细表并排序:按 user_id 与 browser_name 升序排列。
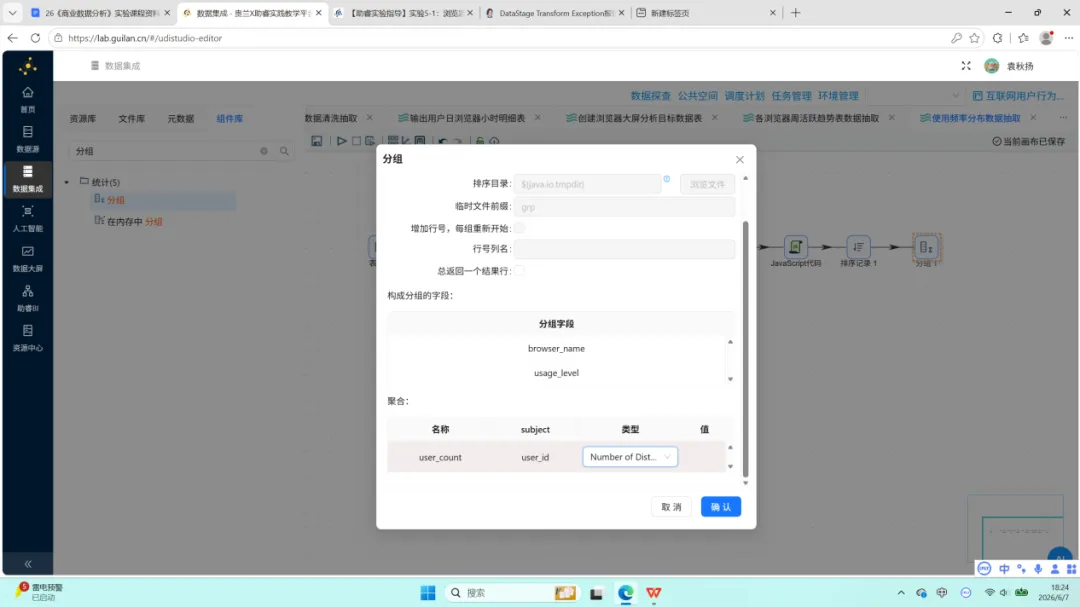
2.第一次分组:按 user_id 与 browser_name 聚合,对 total_duration_sec 求和,计算每位用户在每款浏览器上的累计使用秒数。
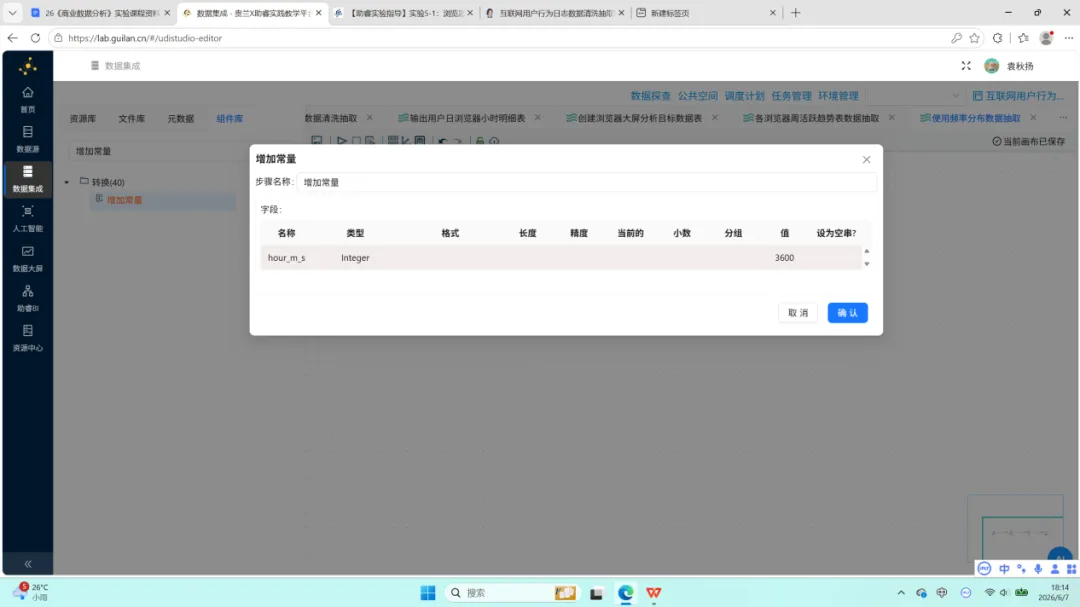
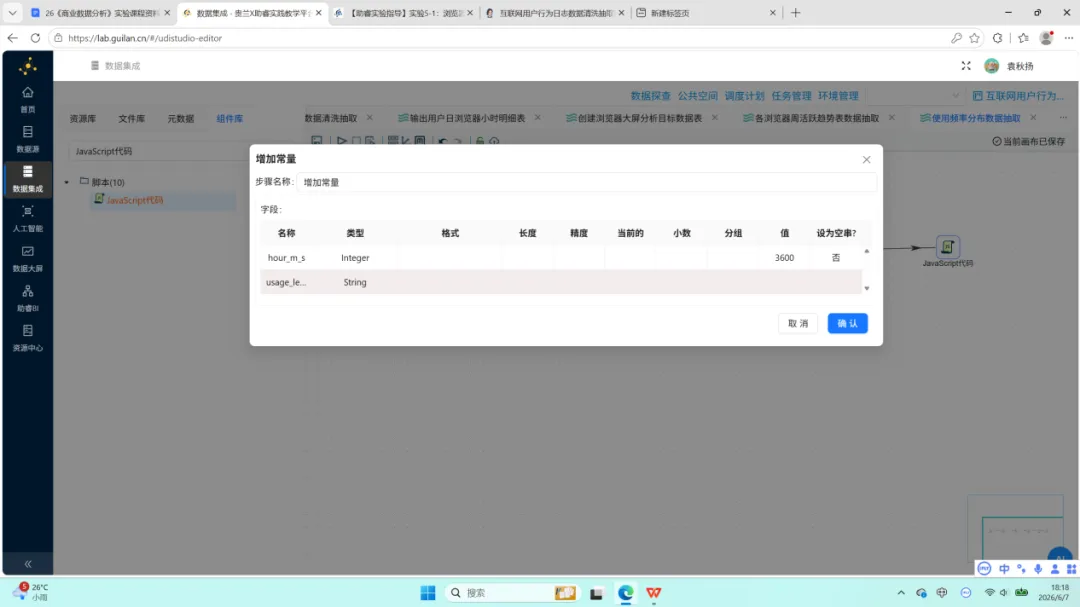
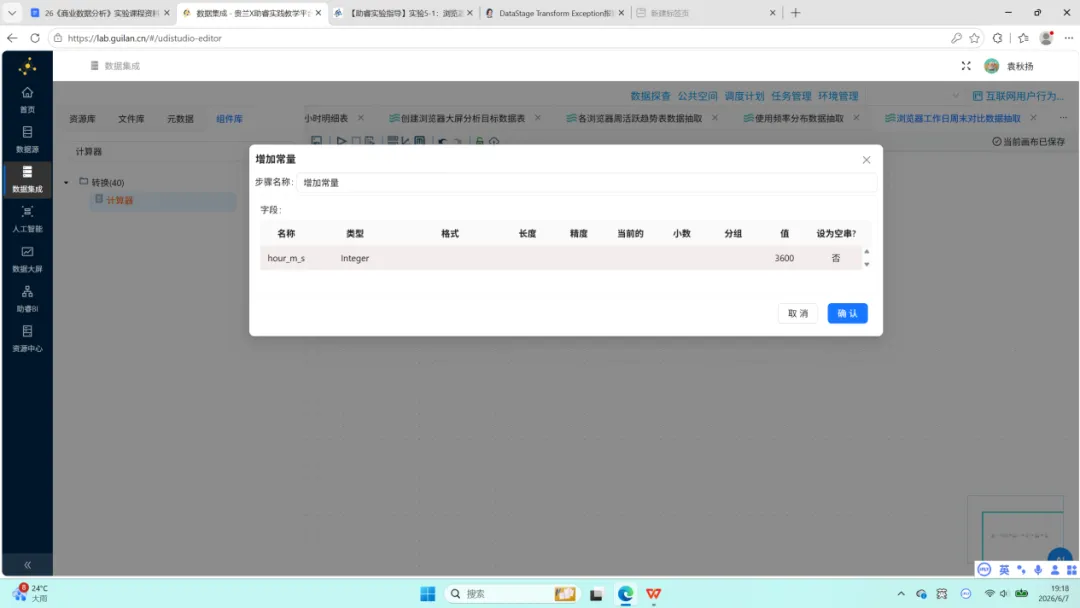
3.增加常量:插入字段 hour_m_s,类型为 Integer,固定值为 3600,用于后续秒到小时的转换。
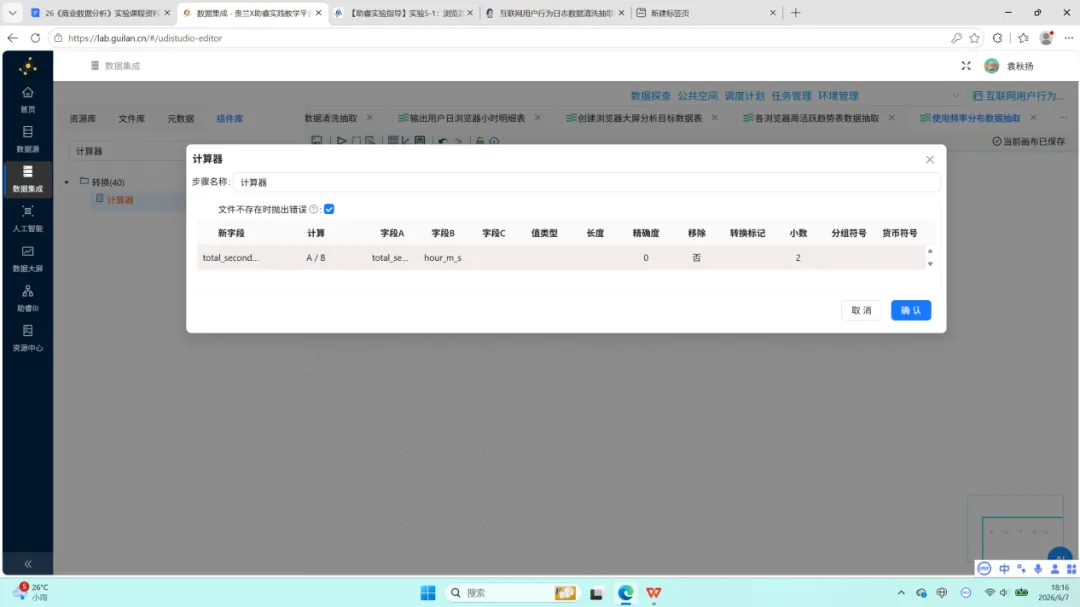
4.计算器:执行 A / B 运算,total_seconds 除以 hour_m_s,得到 total_hours 字段并保留 2 位小数。
5.JavaScript 分级:依据周使用时长将用户划分为三个等级——轻度(< 3 小时)、中度(3-10 小时)、重度(> 10 小时)。
var total_hours = total_hours;var usage_level =”;if (total_hours <3) {usage_level =‘轻度’;} elseif (total_hours >=3&& total_hours <10) {usage_level =‘中度’;} else {usage_level =‘重度’;}
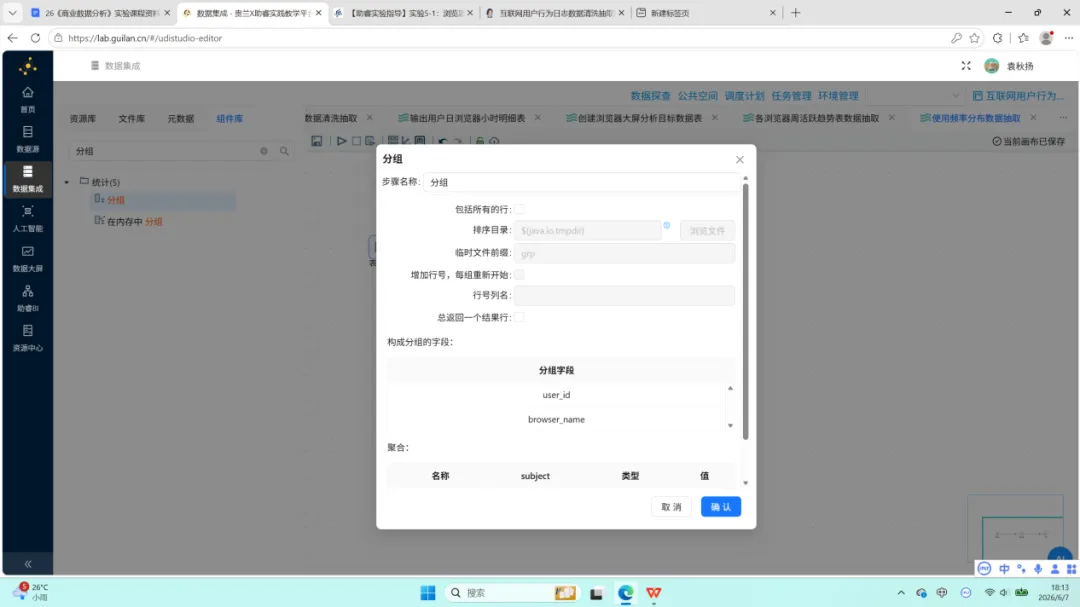
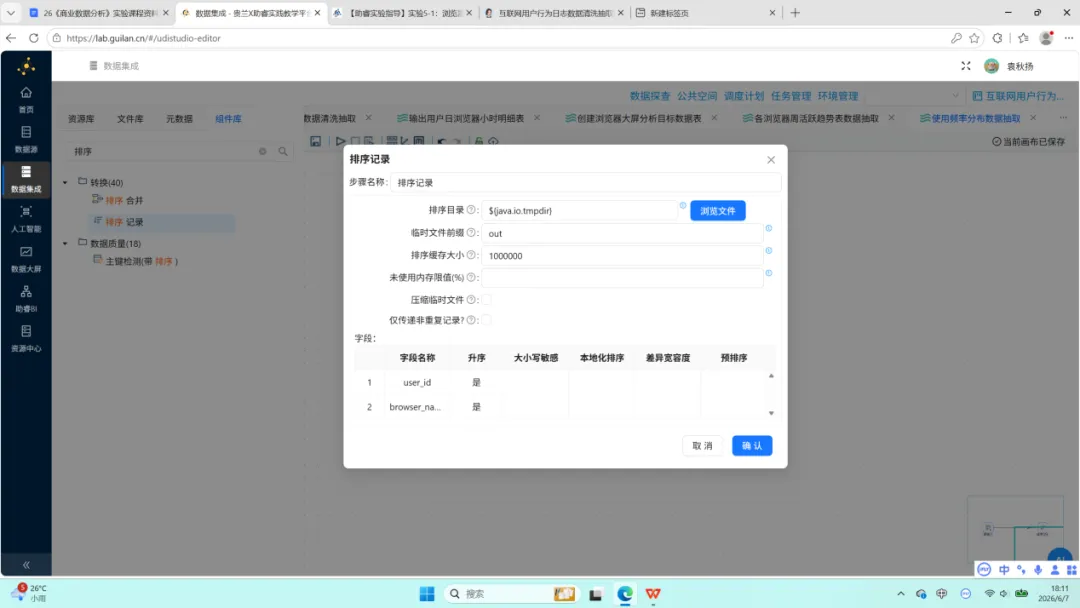
6.第二次排序与分组:按 browser_name 与 usage_level 升序排序后,以相同字段分组,对 user_id 执行去重计数。
7.表输出:写入 browser_frequency_stats。
3.3 用户使用浏览器数量分布表
目标:统计使用 1 种、2 种、3 种及以上浏览器的用户数量分布。
1.表输入与排序:读取明细表,按 user_id 升序排序。
2.第一次分组:按 user_id 分组,对 browser_name 执行去重计数,得到字段 browser_cnt,表示该用户使用的浏览器种类数量。
3.JavaScript 分级:将使用种类数量映射为分类标签。
var browser_cnt = browser_cnt;var browser_count =”;if (browser_cnt ==1) {browser_count =‘1种’;} elseif (browser_cnt ==2) {browser_count =‘2种’;} else {browser_count =‘3种及以上’;}
4.第二次排序与分组:按 browser_count 升序排序并分组,统计 user_count。
5.表输出:写入 browser_multi_usage。
本节的转换流结构与 3.2 节类似,此处不再重复展示全部截图。
3.4 各浏览器工作日与周末对比表
目标:按浏览器和日期类型(工作日/周末)两个维度,统计人均使用时长与总使用时长。
核心步骤为通过 JavaScript 根据日期获取星期值:0(周日)和 6(周六)判定为周末,1-5 判定为工作日。
var date = usage_date;var dayOfWeek = date.getDay();var day_type =“”;if (dayOfWeek >=1&& dayOfWeek <=5) {day_type =“工作日”;} else {day_type =“周末”;}
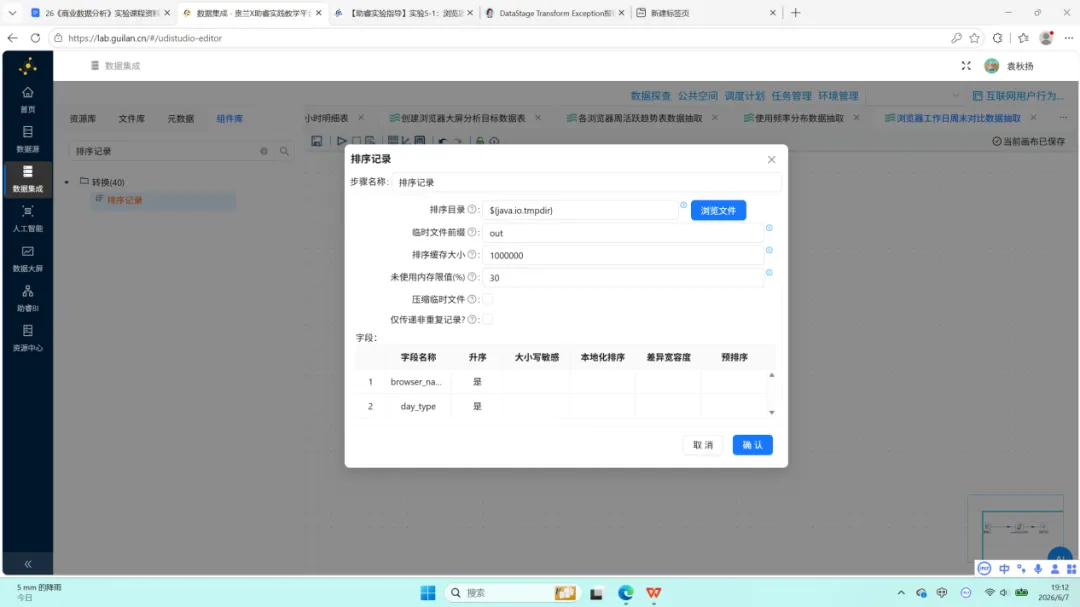
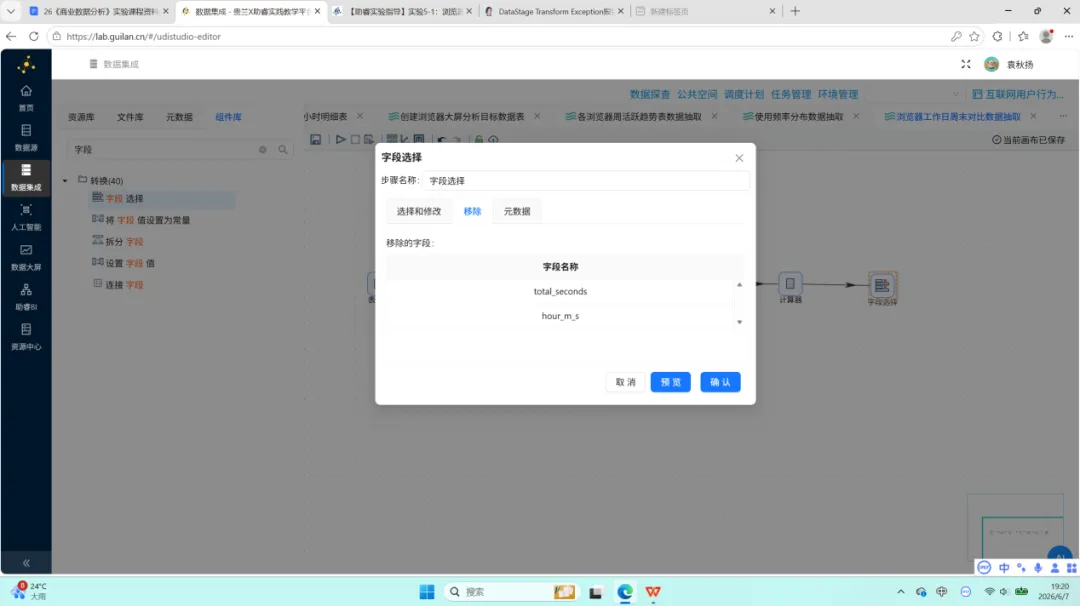
后续操作流程:按 browser_name 与 day_type 排序后执行分组聚合,计算 avg_seconds(平均使用时长)、total_seconds(总使用时长)、user_count(去重用户数)。通过增加常量组件与计算器组件将总使用秒数转换为小时单位,最后以字段选择组件移除中间计算字段,输出至 browser_weekday_weekend。
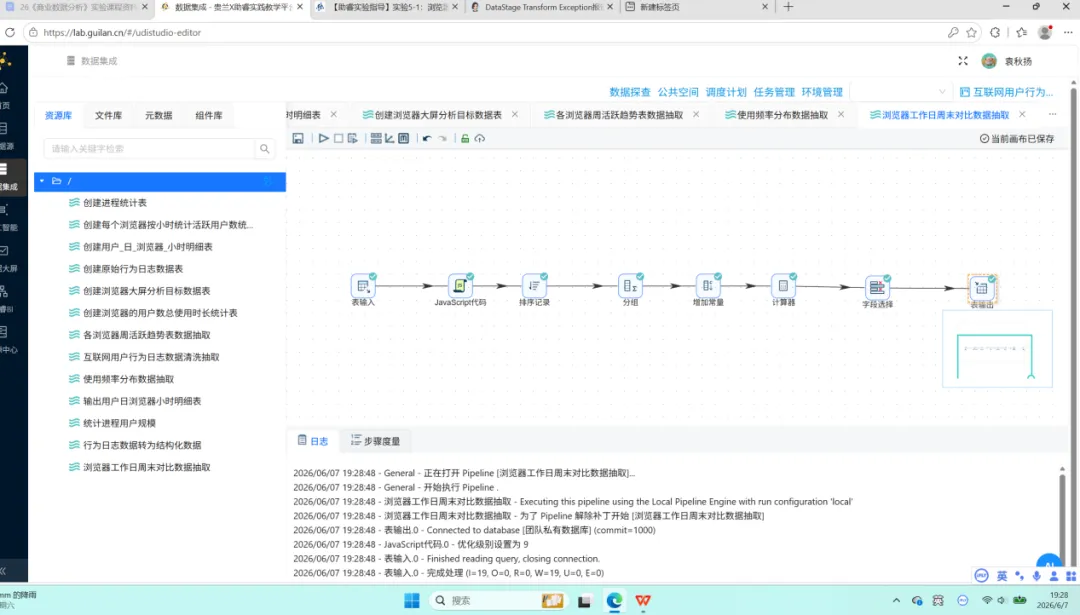
3.5 核心指标数据抽取
目标:一次性计算四个全局核心指标——总使用时长、人均使用时长、活跃用户占比、重度用户占比。
此处采用一条 SQL 语句直接完成所有指标的计算,相较于分多条转换流分别计算,显著简化了编排复杂度。
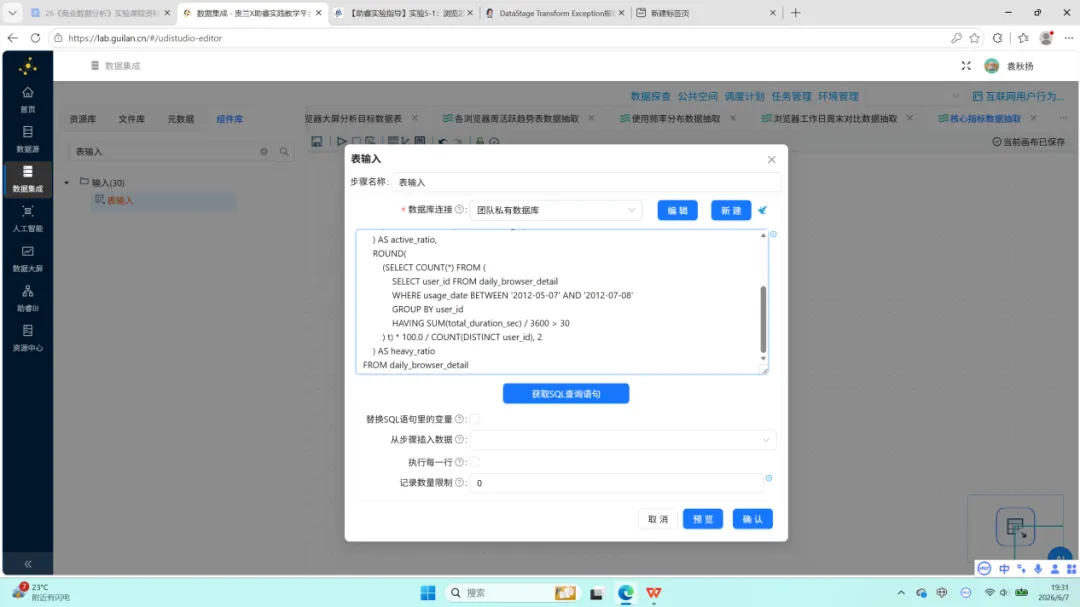
SELECTROUND(SUM(total_duration_sec) /3600, 2) AS total_hours,ROUND(SUM(total_duration_sec) /3600/COUNT(DISTINCT user_id), 2) AS avg_hours,ROUND((SELECTCOUNT(DISTINCT user_id) FROM daily_browser_detail WHERE usage_date BETWEEN‘2012-08-06’AND‘2012-08-12’) *100.0/COUNT(DISTINCT user_id), 2) AS active_ratio,ROUND((SELECTCOUNT(*) FROM (SELECT user_id FROM daily_browser_detail WHERE usage_date BETWEEN‘2012-05-07’AND‘2012-07-08’GROUPBY user_idHAVINGSUM(total_duration_sec) /3600>30) t) *100.0/COUNT(DISTINCT user_id), 2) AS heavy_ratioFROM daily_browser_detail
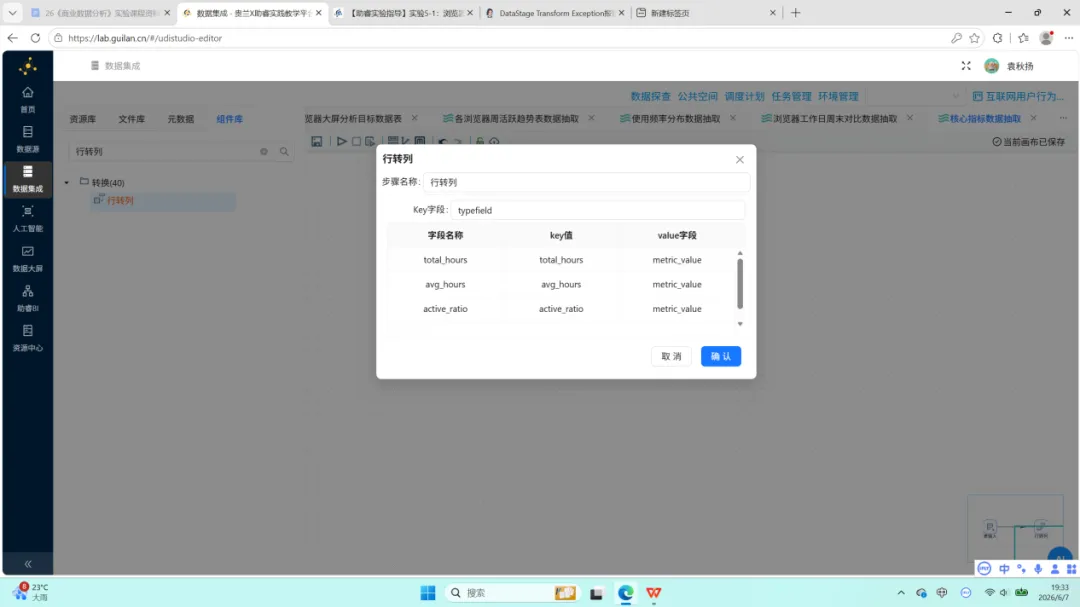
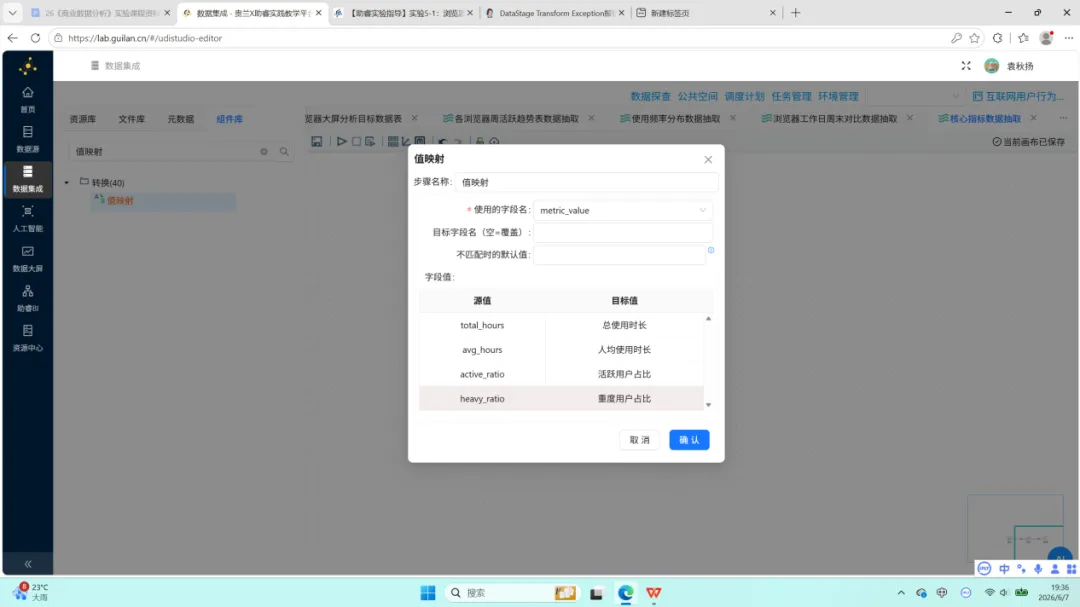
SQL 查询返回单行四列结果。后续通过”行转列”组件将字段名称转换为 metric_name、字段值转换为 metric_value;再以”值映射”组件将英文 key 映射为对应的中文指标名称。最终写入 browser_overview。
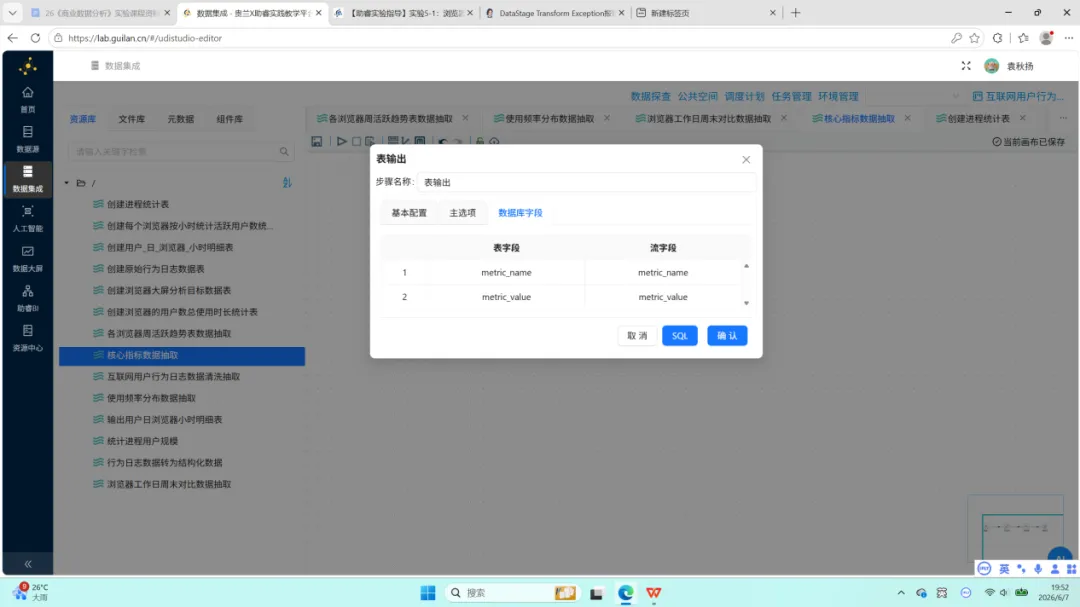
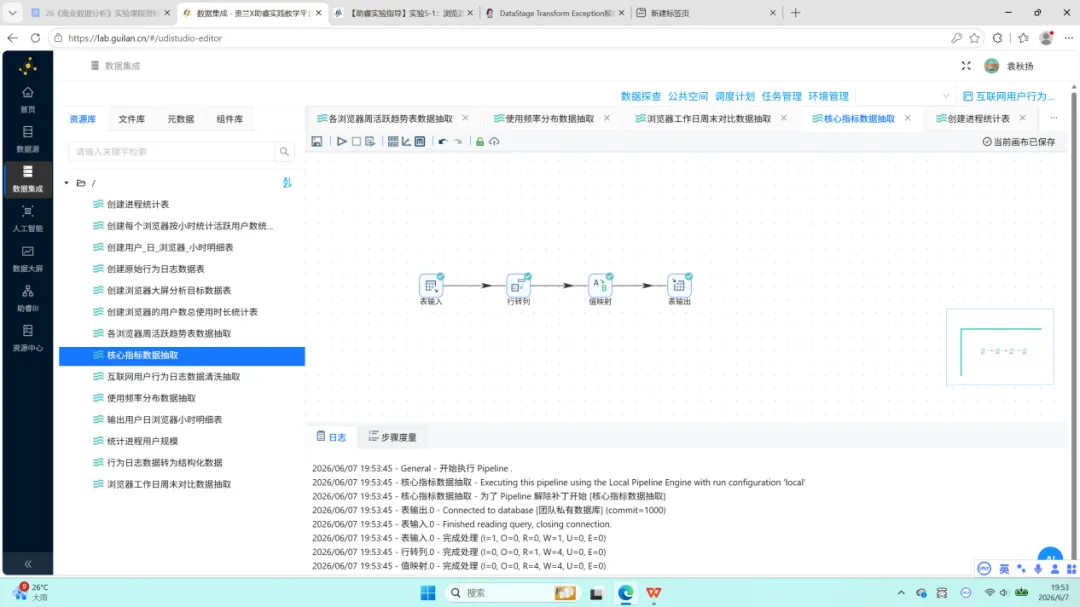
3.6 用户画像统计表加工
目标:为每款浏览器统计用户群体的画像分布,涵盖性别、年龄、学历、职业、收入、居住地类型、省份七个维度。
此步骤需引入外部人口属性数据 demographic.csv(从平台公共空间导出至项目文件库),通过用户 ID 与明细表进行关联。
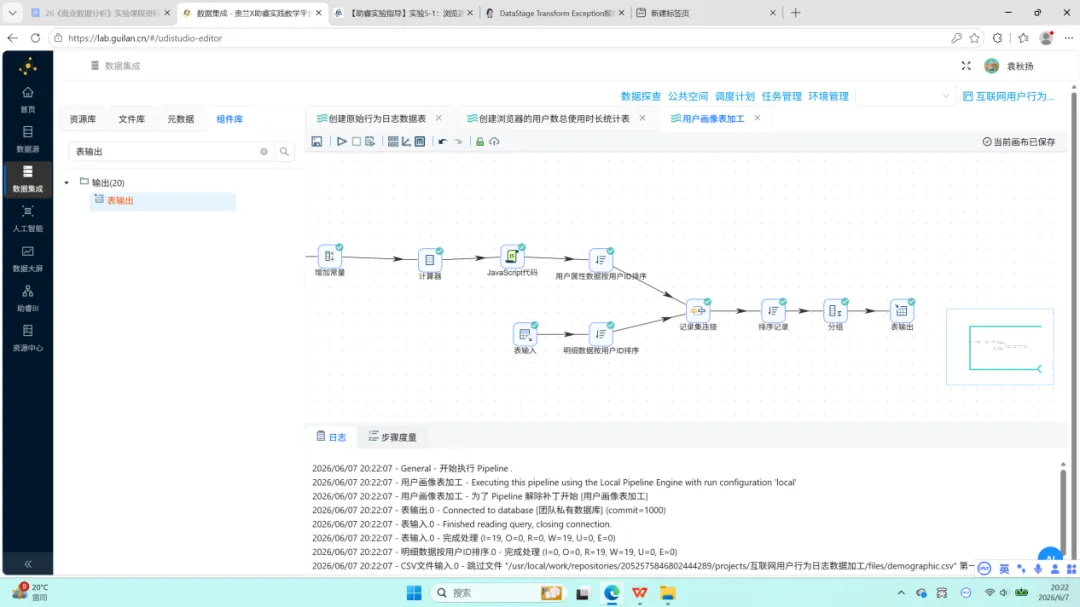
加工链路为两条支线并行后合并:CSV文件输入 → 增加常量 → 计算器(年龄) → JavaScript(年龄分段) → 排序 与 表输入(明细表) → 排序,两支线汇入 记录集连接(LEFT OUTER JOIN) 后,再经由 排序 → 分组 → 表输出 完成入库。
读取人口属性数据。 使用”CSV 文件输入”组件加载 demographic.csv,编码选择 UTF-8,通过”获取字段”按钮自动解析字段结构。
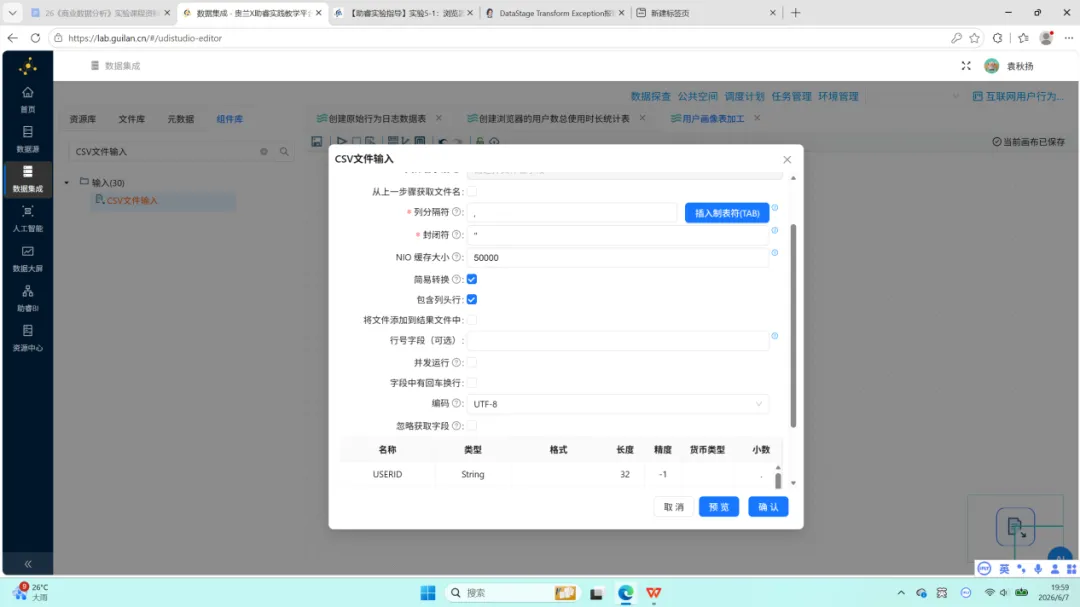
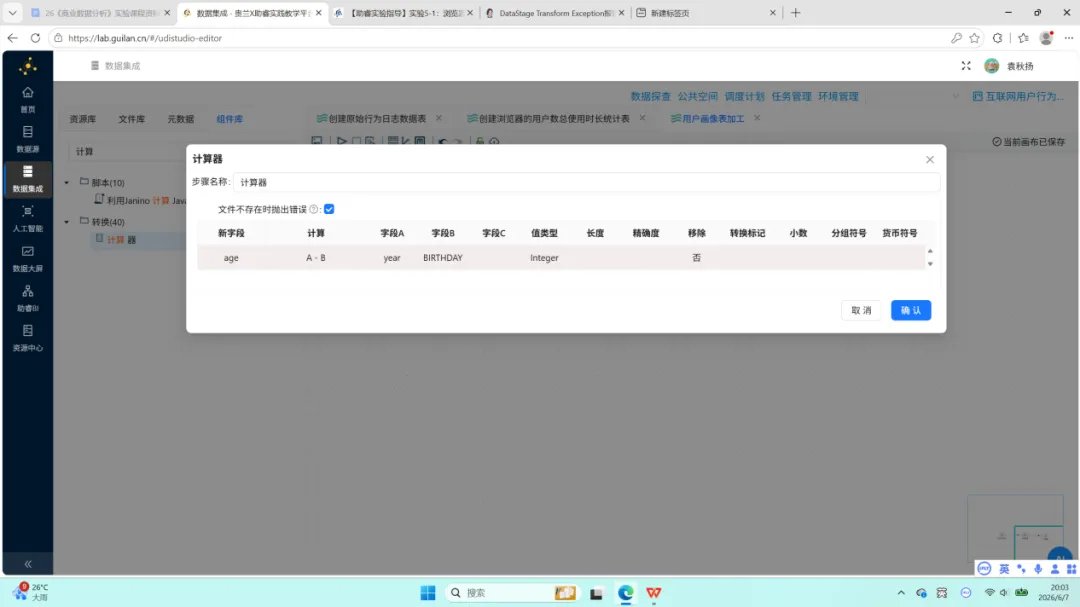
年龄计算与分段。 原数据中包含出生年份字段(BIRTHDAY)而无直接年龄字段,数据采集年份为 2012 年,因此 age = 2012 – BIRTHDAY。随后通过 JavaScript 将年龄划分为四段:18 岁以下、18-25 岁、26-35 岁、35 岁以上。
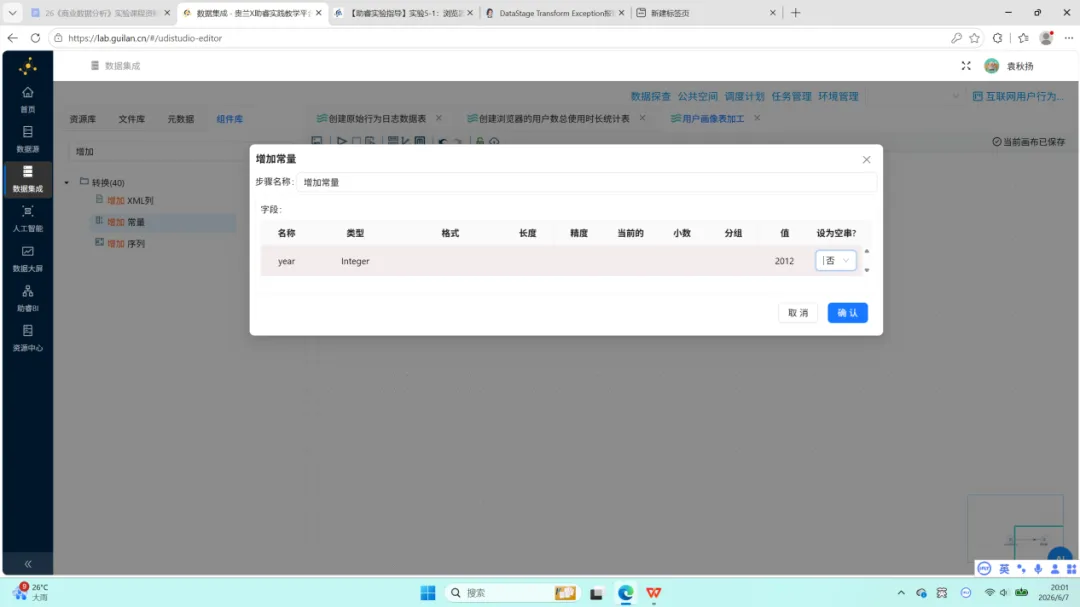
var age_group =”;if (age <18) {age_group =‘<18’;} elseif (age <=25) {age_group =’18-25′;} elseif (age <=35) {age_group =’26-35′;} else {age_group =‘>35’;}
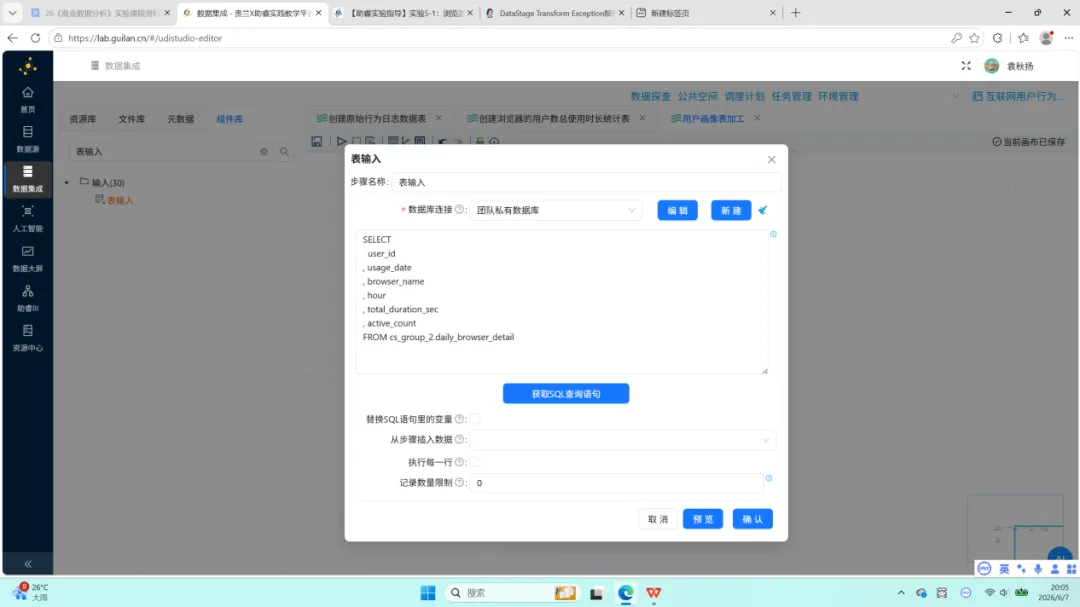
读取明细表。 以”表输入”组件读取 daily_browser_detail 的全部字段数据。
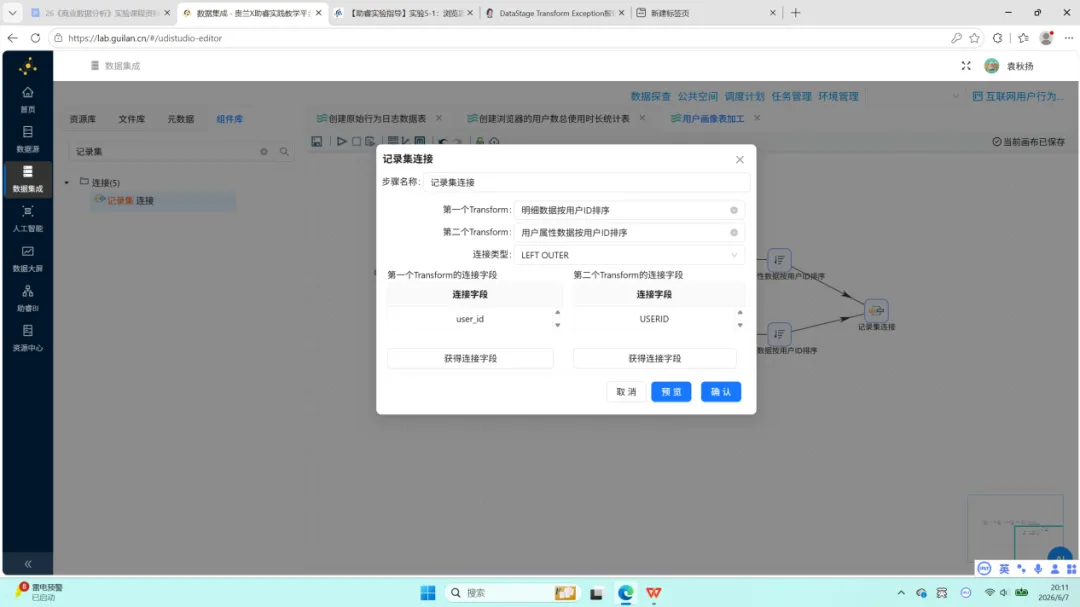
双线排序与记录集连接。 两支线数据分别按 user_id 升序排序后,通过”记录集连接”组件执行 LEFT OUTER JOIN。左侧为明细数据(连接字段 user_id),右侧为用户属性数据(连接字段 USERID)。
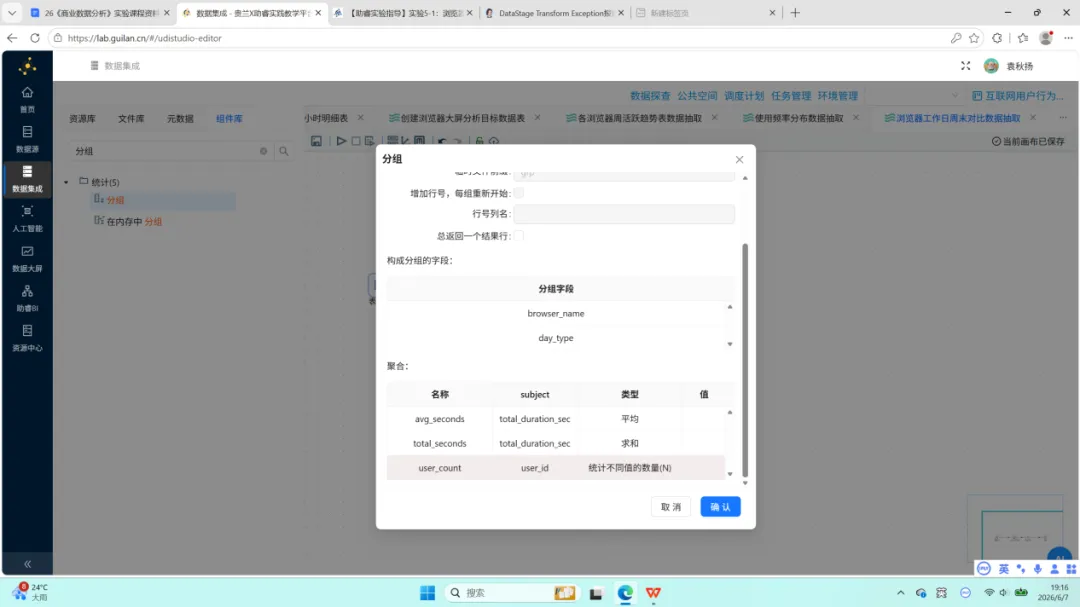
多维度分组聚合。 按 browser_name、GENDER、EDU、JOB、INCOME、PROVINCE、ISCITY、age_group 共 8 个字段分组,对 user_id 执行去重计数。
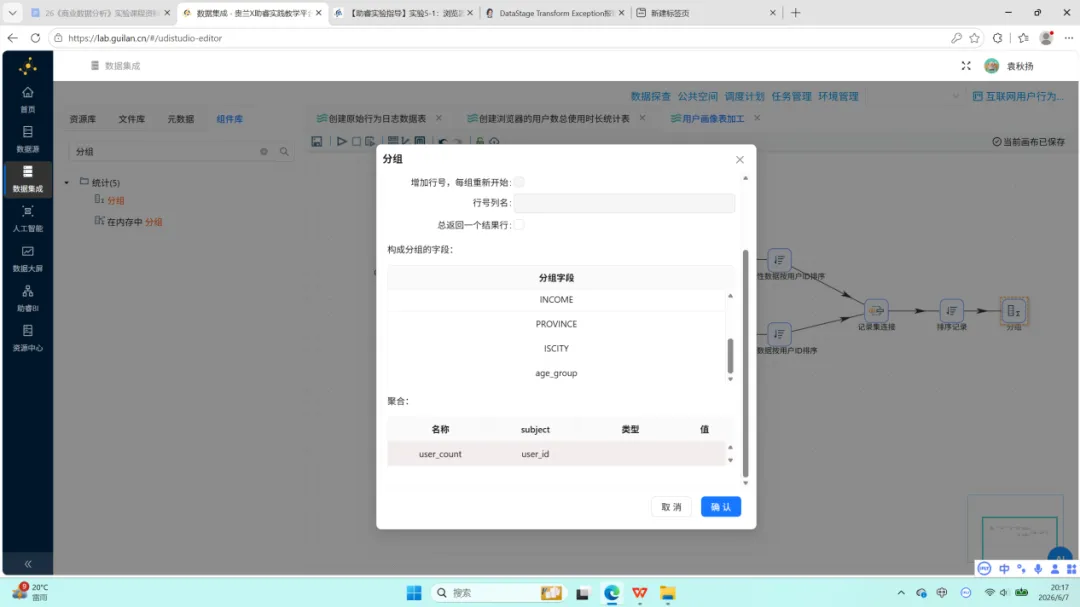
表输出。 将分组聚合结果写入 user_profile_stats。
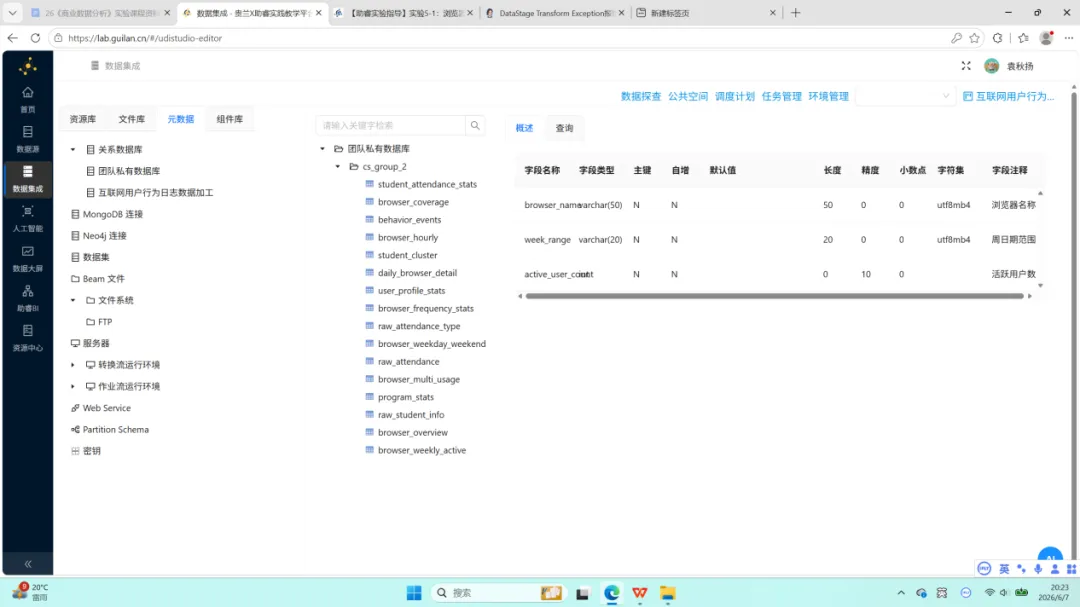
结果验证。 在平台元数据模块中加载团队私有数据库,对 user_profile_stats 表执行数据探查,检查各维度分组计数是否符合预期。

四、实践总结
本次 ETL 加工实践形成以下几点认识:
1.明细表是聚合体系的根基。 全部 7 张目标表均源自 daily_browser_detail,该表的数据质量直接决定下游聚合结果的准确性。排序字段与分组字段不一致、过滤条件遗漏非浏览器进程等问题,均可能导致计数翻倍或数据偏差,应在早期环节严格检查。
2.JavaScript 组件提供关键的灵活性。 日期转星期、使用时长分级、年龄分段等业务逻辑,均可通过少量 JavaScript 代码简洁实现,有效降低了多组件串联的维护负担。
3.先建表再开发有利于流程衔接。 在加工开始前批量完成全部目标表的创建,避免各转换流执行时因目标表缺失而反复中断。
4.SQL 集中计算可替代多条转换流。 核心指标抽取案例中,一条 SQL 语句配合行转列与值映射组件,即可完成原本需要多条独立转换流才能实现的指标计算,显著提升编排效率。
完成本阶段 ETL 加工后,下一步工作是将 7 张目标表接入数据大屏可视化工具,进入数据呈现环节。