从因子动物园到日内市场择时:高频横截面信号、跳跃—连续分解与机器学习
一、研究背景:有效市场假说、日内可预测性与“因子动物园”
整个讨论可以归结为两个老问题:大盘收益可预测吗?如果可预测,能不能靠预测赚到扣费后的超额收益?这两个问题正是有效市场假说的核心。
过去几十年的主流证据集中在低频(日度、月度、季度)层面,使用的预测变量也相对有限——估值比率、股息率、利率、各类波动率指标等等,结论一直摇摆不定:有人找到样本内的可预测性,样本外却往往失效。与之并行的另一支文献则关注日内收益的可预测性,通常把它归因于做市、买卖价差、信息逐步扩散等微观结构摩擦。
这里要走的是第三条路:把视角同时放在“高频”和“高维”上。一方面,采样频率提高到 15 分钟级别;另一方面,预测变量不再是寥寥几个宏观指标,而是来自横截面资产定价因子的一整个“动物园”——动量、价值、盈利、低风险、换手、流动性、尾部风险等等,数量达到两百多个。直觉很朴素:这些因子组合每天都在以高频被交易,它们的滞后收益里很可能残留着尚未被大盘价格吸收的信息;把这些信息聚合起来,就有机会预测大盘的下一段日内走势。
要理解为什么“日内”值得单独研究,先看一个基本事实:市场组合的日内平均收益并不是均匀分布的,开盘与收盘附近的收益、成交与波动往往更显著,中段相对平淡。这种“日内时段结构”本身就为日内择时提供了空间。
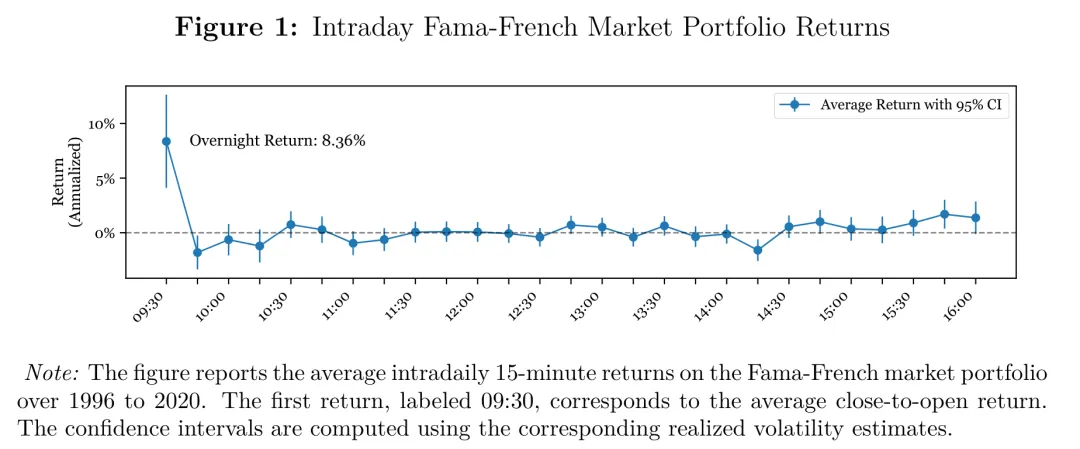
图:日内 15 分钟市场组合平均收益按时段的分布,用于说明开盘与收盘附近收益与波动更显著、中段相对平淡的“日内 U 型”结构,为日内择时提供动机。
二、核心直觉:把“跳跃”和“连续”分开
在动手做预测之前,有一个常被忽视、却对结果影响很大的建模选择:预测目标(被解释变量)到底该用什么收益?
把对数价格 写成高频金融计量里标准的跳跃—扩散过程:
其中 是漂移项, 是随机波动率, 是布朗运动, 是发生在随机时点的跳跃幅度。这个分解的关键经济含义是:在无套利条件下,跳跃部分本质上不可预测;而漂移与扩散部分(承载着风险溢价和信息的缓慢吸收)是连续的、并且可能可预测。既然两者“可预测性”天然不同,把它们在建模时区别对待就是顺理成章的。
一个直观的例子最能说明问题。设想某个交易日午盘出现一次政策面意外冲击(例如一次超预期的政策利率调整),价格在那一刻被瞬间抬升——这就是一个典型的跳跃。
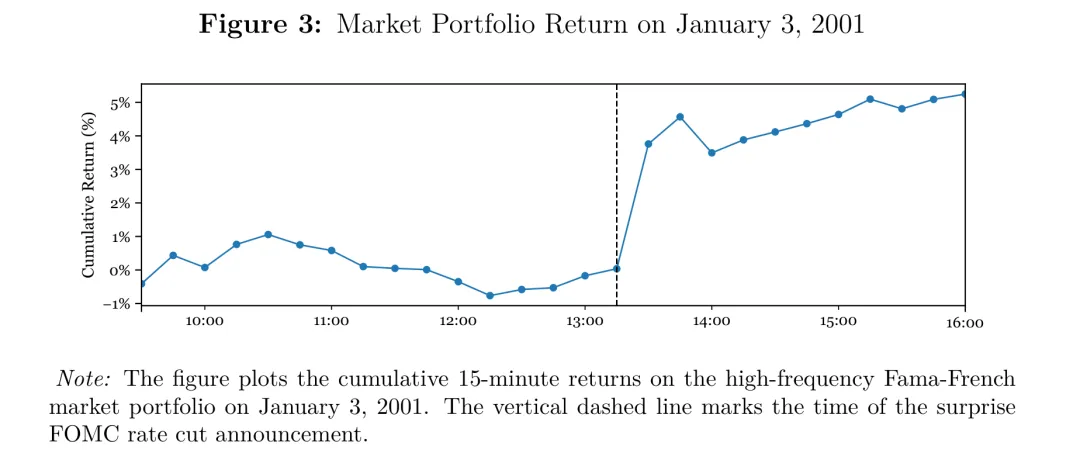
图:某交易日 15 分钟累计收益曲线,在政策意外公布的时点出现一次明显的向上跳跃(图中以竖虚线标注公布时刻),用于直观说明“跳跃不可预测、其后连续段才可能带有可预测性”。
用一个简单的日内 AR(1) 来量化这种直觉,会看到很有意思的现象:如果把包含跳跃的全天 15 分钟收益拿去回归,样本内 只有大约 ;但如果剔除掉那段跳跃收益再做 AR(1), 会跳升到约 ;而如果用“含跳跃”模型的系数去预测“非跳跃”收益, 甚至变成负的(约 )。
这背后的机制对做量化的人非常熟悉:跳跃是一两个数量级很大、又不可预测的极端值,一旦进入被解释变量,回归就会去过拟合这些大跳,反而把其余时段里那些“小但可能可预测”的变动彻底淹没。结论很实用——应该把市场跳跃从预测目标里剔除,只预测连续部分。
如何把跳跃识别出来(且不引入前视偏差)
首先,为了压制买卖价差、价格离散等微观结构噪声,采样频率被刻意放粗到 15 分钟,于是每个交易日有 个日内收益。记 为第 天、第 个时段的 15 分钟收益,。
跳跃识别采用经典的截断法:当某个高频收益“大到不像是来自局部方差下的正态分布”时,就判定为跳跃。形式上,若
则把 标记为跳跃,其中 与 是调参常数(取 、), 是该时点的瞬时波动率估计。
这里有一个对实盘很关键的细节:文献里常用事后全天数据(如双幂变差)来估 ,但那样会引入前视偏差。这里改用只依赖当前时点之前信息的指数加权移动平均(EWMA),对相邻绝对收益乘积做平滑,再叠加一个“日内时段调整因子”来吸收日内波动的周期性。它的灵感来自传统的双幂变差度量
区别仅在于把“用整天事后收益”换成了“只用历史已实现收益”,从而保证跳跃检测可以在实时滚动中落地。对量化研究员来说,这是把一个学术估计量“工程化、可回测化”的标准动作。
三、因子动物园与“维度诅咒”:为什么必须正则化
预测变量来自两百多个横截面因子(共 272 个)。借鉴用于波动率建模的 HAR(异质自回归)思想,这里给每个因子都构造一个多时间尺度的级联结构:每个因子拆成 15 分钟、过去 1 小时、过去 1 天三个滞后收益,即
这样一来,基准设定就有 个回归系数;如果再把每个因子进一步拆成连续和跳跃两部分,参数量翻倍到 个。
更棘手的是,这些因子彼此高度相关。很多因子在构造上本就重叠(例如不同口径的换手率因子、不同窗口的流动性因子),它们的高频已实现相关系数能高达九成以上。
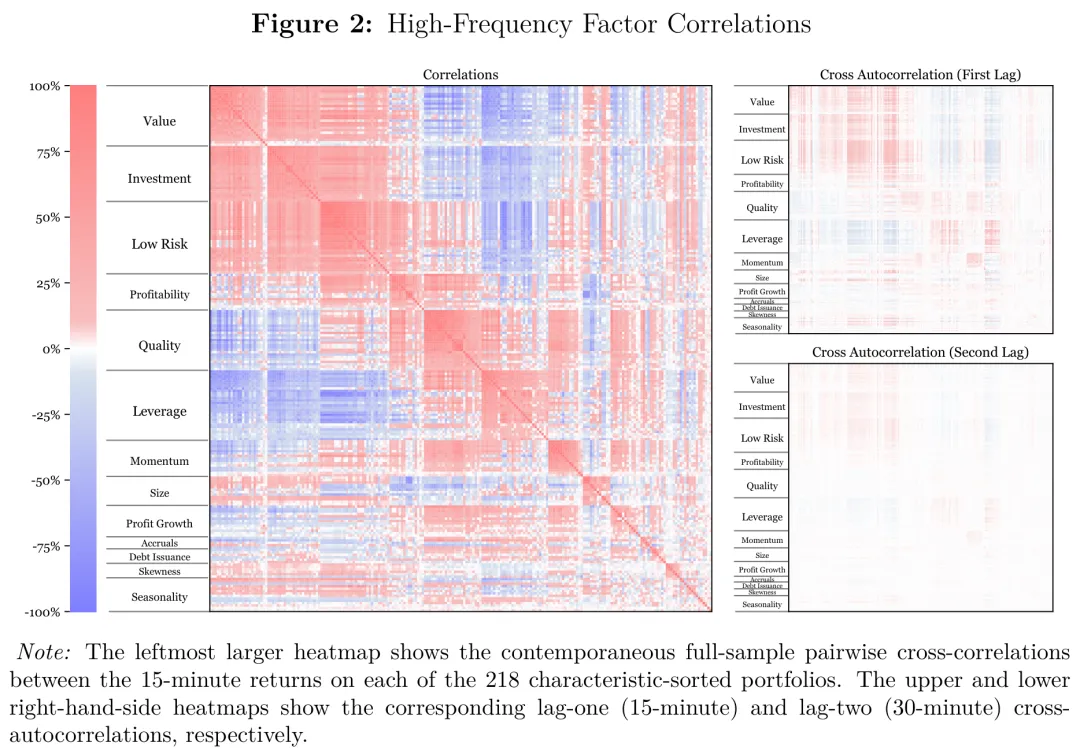
图:因子之间的高频已实现相关系数热力图,用于说明“动物园”里大量因子高度共线、信息严重冗余,因而普通最小二乘无法稳定估计这个高维系统。
高维 + 高共线性,意味着直接上 OLS 既不可行也不稳健——这正是机器学习里典型的“维度诅咒”。要驯服这个动物园,必须引入正则化与降维。
四、预测模型设定与机器学习工具箱
四种预测设定
把“被解释变量用什么、解释变量用什么”两两组合,得到四个层层递进的设定:
-
All, All:用 15 分钟市场总收益 作被解释变量,所有因子的滞后总收益作解释变量。 -
All, All+Jmp:在上面的基础上,把每个因子额外拆出跳跃分量也放进解释变量,允许“滞后跳跃信号”和“滞后连续信号”的预测含义不同。 -
Cts, All:被解释变量换成市场的连续收益(剔除大盘跳跃),解释变量仍为全部因子收益。 -
Cts, All+Jmp:连续目标 + 含跳跃的解释变量,是最一般的设定之一。
之所以强调 Cts 系列,正是第二节的逻辑落地:既然大盘跳跃不可预测,把它从预测目标里拿掉,既能提高拟合的有效性,又能避免被极端值带偏。
机器学习算法菜单
为了在高维下做出稳健预测,这里把现在金融机器学习里相当标准的一整套估计器都用上了:
-
线性/降维类:OLS、岭回归(Ridge)、Lasso、弹性网(ENet)、自适应 Lasso、主成分回归(PCR)、偏最小二乘(PLS); -
非线性类:前馈神经网络(FNN)、随机森林(RF)、梯度提升回归树(GBRT); -
集成(Ensemble):把上述模型(除 OLS 外)等权平均成一个综合预测——这往往是实务中最稳的一招。
对照基准则刻意设得“难打”一些:只用大盘自身历史信息的 AR(1)、AR(4)、AR(26)(分别对应过去 15 分钟、1 小时、1 天),以及一个用到事后均值、现实中不可实现的样本均值基准。能稳定打赢这些基准,才说明因子动物园里确实有大盘自身价格之外的增量信息。
实现细节:严格样本外
调参用机器学习里标准的训练/验证/测试三段式滚动:按时间顺序展开窗口,前 80% 训练参数、后 20% 验证超参数(按验证期 MSE 最小选超参),再到测试期生成预测;测试窗口固定为一个自然年,每年滚动重训一次。样本外评估从 2004 年一直做到 2020 年,跨越 17 年、约 11.1 万个 15 分钟观测。三段都按时间先后切分,保证不破坏时间序列结构、不引入前视偏差——这套流程本身就是一份可直接借鉴的高频回测模板。
五、预测结果: 虽小,但在高频下有意义
样本外 的量级看起来很“吓人地小”:最好的设定大约只有 出头(集成模型在 All, All 设定下约为 ),而把被解释变量换成连续收益、或把解释变量拆成连续+跳跃后, 还能进一步改善。
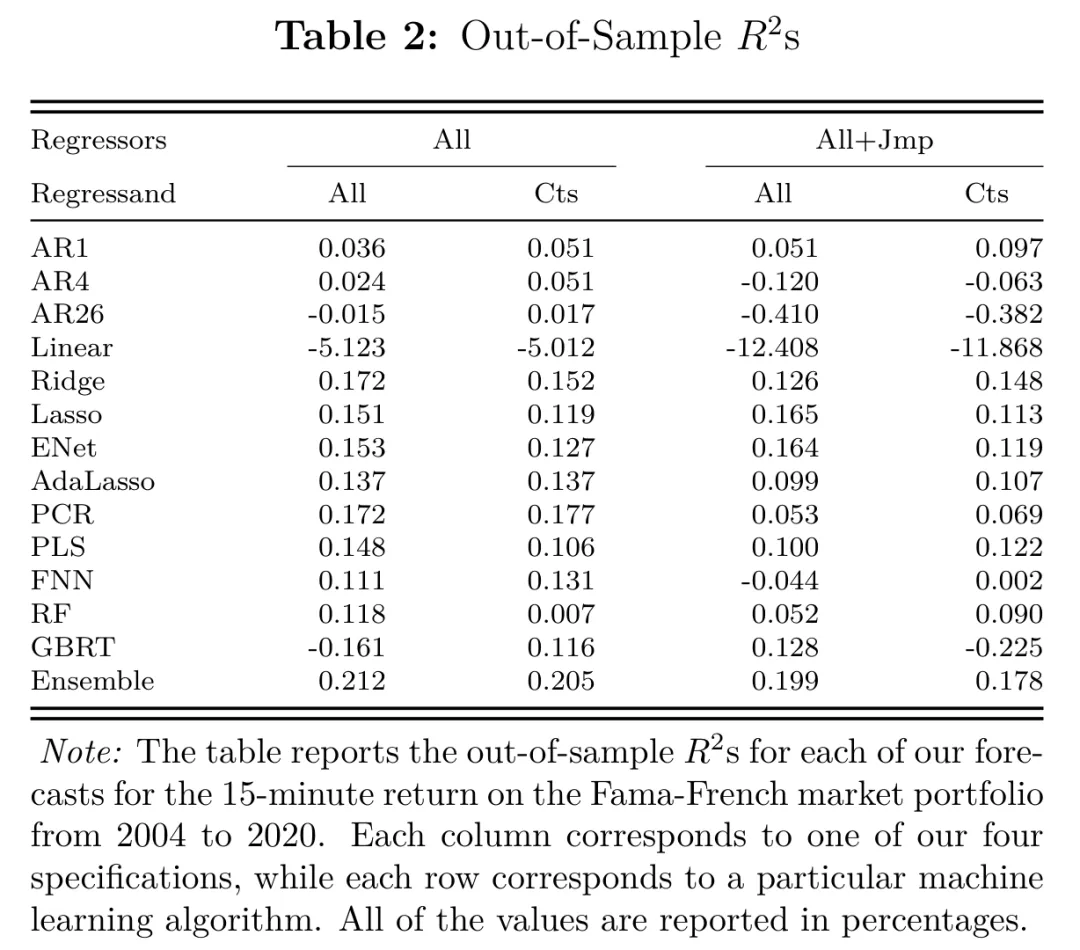
图:不同模型设定 × 不同机器学习算法的样本外 对比表,用于说明因子设定与算法选择对预测力的影响,以及“瞄准连续收益”相对“瞄准总收益”的提升。
这里要替不熟悉高频的读者说句公道话:**不要用低频的直觉去看这个 **。在 15 分钟尺度上,信噪比天然极低, 级别的样本外 已经相当可观;更重要的是,这个微弱但稳定的边际,会在每天 26 个时段、一年数千个时段上不断复利,最终能否转化为可观的夏普,要看交易层面的检验,而不是看单期 的绝对大小。统计显著性方面,用 Diebold-Mariano 检验对比预测 MSE,也能确认集成模型相对基准的改进并非偶然。
六、从预测到交易:四种策略与成本调整
有了预测,接下来要把信号翻译成仓位。记 为市场组合在第 天、第 时段的权重, 为模型对下一段收益的预测。四种策略由简到繁:
Sign(符号策略):只看预测方向,正则做多、负则做空:
Positive(只做多策略):考虑到做空成本更高、且很多机构受限不能做空,把负向信号下的暴露直接归零:
S-Sign(带无交易带的符号策略):Sign 和 Positive 都会随信号变号频繁换仓,在日内尺度上交易成本会非常吃重。借鉴“只向目标仓位部分调整”的思路,只有当信号强到足以覆盖滞后半价差(Spread/2)时才动手,否则维持原仓位:
可以证明,S-Sign 正是“在每次交易需支付半价差的成本下最大化期望收益”这一静态优化问题的最优解;它和 Positive 的只做多版本就构成第四个策略 S-Positive。和早期同类研究不同的是,这里在信号不够强时是保持原仓位而非清零,从而把无谓换手进一步压下去。
绩效与成本度量
样本外的平均日内收益与夏普分别为:
其中 为样本外年数, 为按日度国库券收益折算到日内的无风险利率, 表示具体的市场代理(ETF)。换手率与扣费后净收益定义为
即每单位换手要付一次半价差,做空时再额外计一笔融券费 。这套成本口径虽然简单,但方向是对的:把换手、价差、做空成本显式写进净值曲线,而不是只看毛收益。
一个值得强调的工程选择是:策略并不是去预测某只 ETF 自身的收益,而是先对“市场组合”做预测,再用这个信号去交易高流动性 ETF。原因在于,单只 ETF 的收益被合约层面的微观结构噪声和跟踪误差污染,直接对它建模,模型容易把精力浪费在经济上无关的波动上,反而拖累交易表现。实证中所用 ETF 的时间加权百分比价差也确实极低(例如标普 500 ETF 约 ),为日内高频策略提供了可行的成本环境。
七、交易绩效:扣费后夏普约 1.37
把上面这套流程跑下来,结果是相当亮眼的:在标普 500 ETF 上,连续目标 + 集成模型 + 带无交易带的 S-Sign 策略的样本外、扣交易成本后年化夏普约为 ;作为对照,单纯买入持有(含隔夜)的夏普只有约 。在用六因子模型调整后,策略仍保留显著为正的 alpha,说明这不是对已知风险溢价的简单复制。
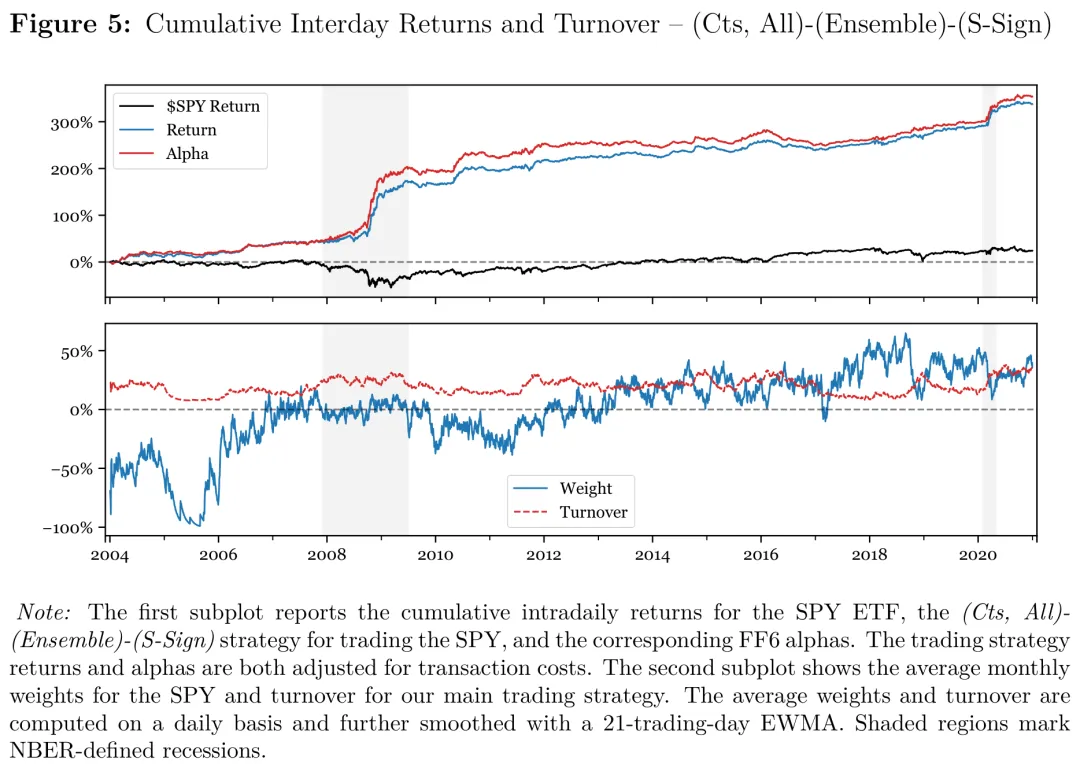
图:头部策略(连续目标—集成—S-Sign)的样本外累计净值曲线及换手,用于展示扣费后净值的稳定上行,以及无交易带对换手的抑制效果。
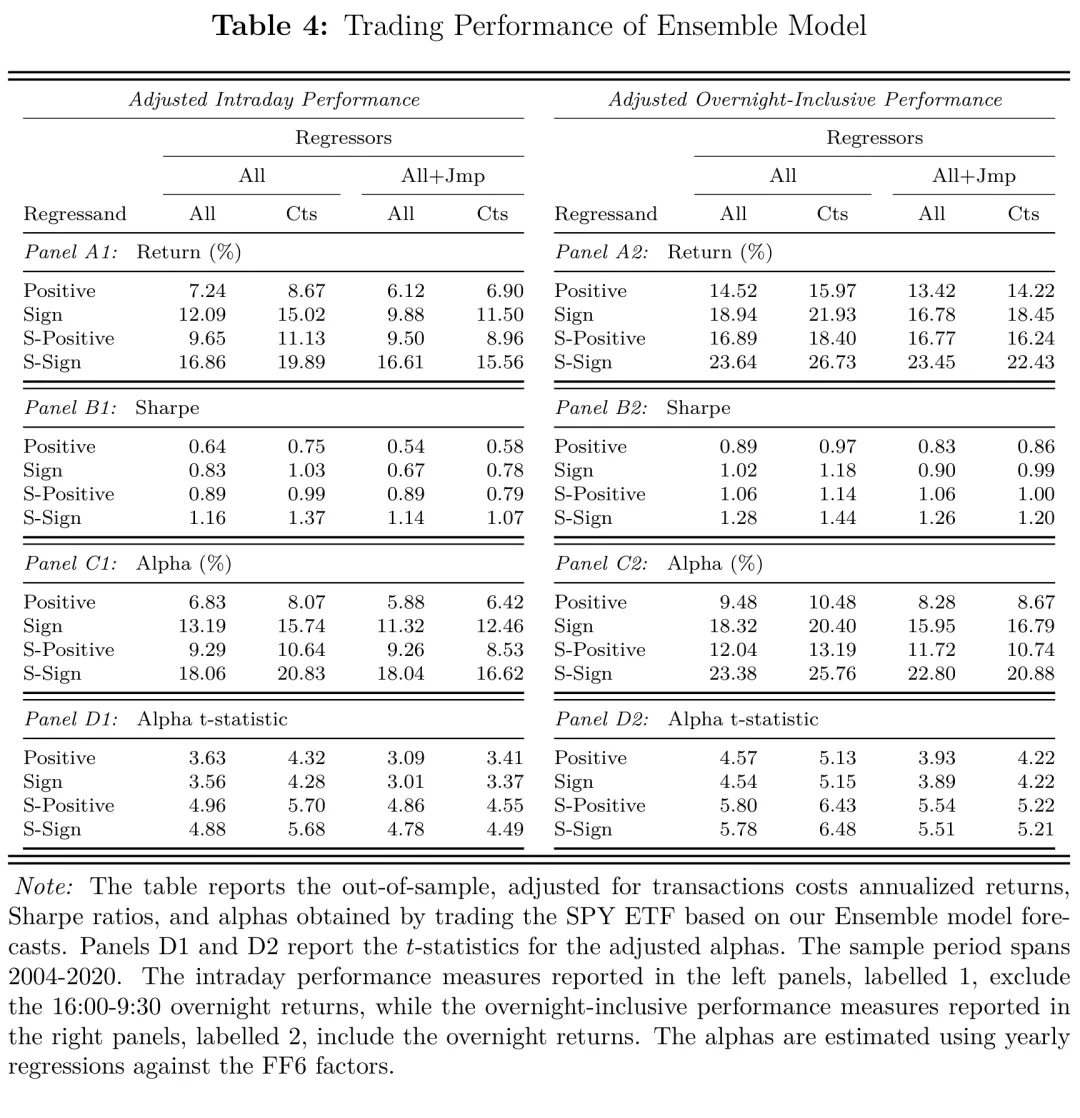
表:集成模型在不同设定 × 不同策略下的交易绩效汇总(扣费后夏普、alpha 等),用于说明“瞄准连续收益”与“带无交易带的成本控制”如何共同提升净表现。
几个对实务有用的规律:其一,瞄准连续收益(Cts)的设定普遍优于瞄准总收益,印证了“把不可预测的跳跃从目标里剔除”的价值;其二,带无交易带的 S-Sign / S-Positive 明显优于会频繁换仓的 Sign / Positive——在日内尺度,交易成本控制几乎和信号本身一样重要;其三,集成预测比单一模型更稳。
八、收益从何而来:SHAP 归因与“慢速资本”
只知道“能赚钱”还不够,量化研究员更关心钱是从哪个因子、在什么环境下赚到的。这里用机器学习里常用的 SHAP 值(基于博弈论中的 Shapley 值)来做归因。SHAP 的好处是可加性:它把每一笔预测(进而是每一份夏普和 alpha)按各个解释变量的边际贡献拆开,所有变量的贡献加总恰好等于总表现,非常适合在高维、非线性模型里量化“谁更重要”。
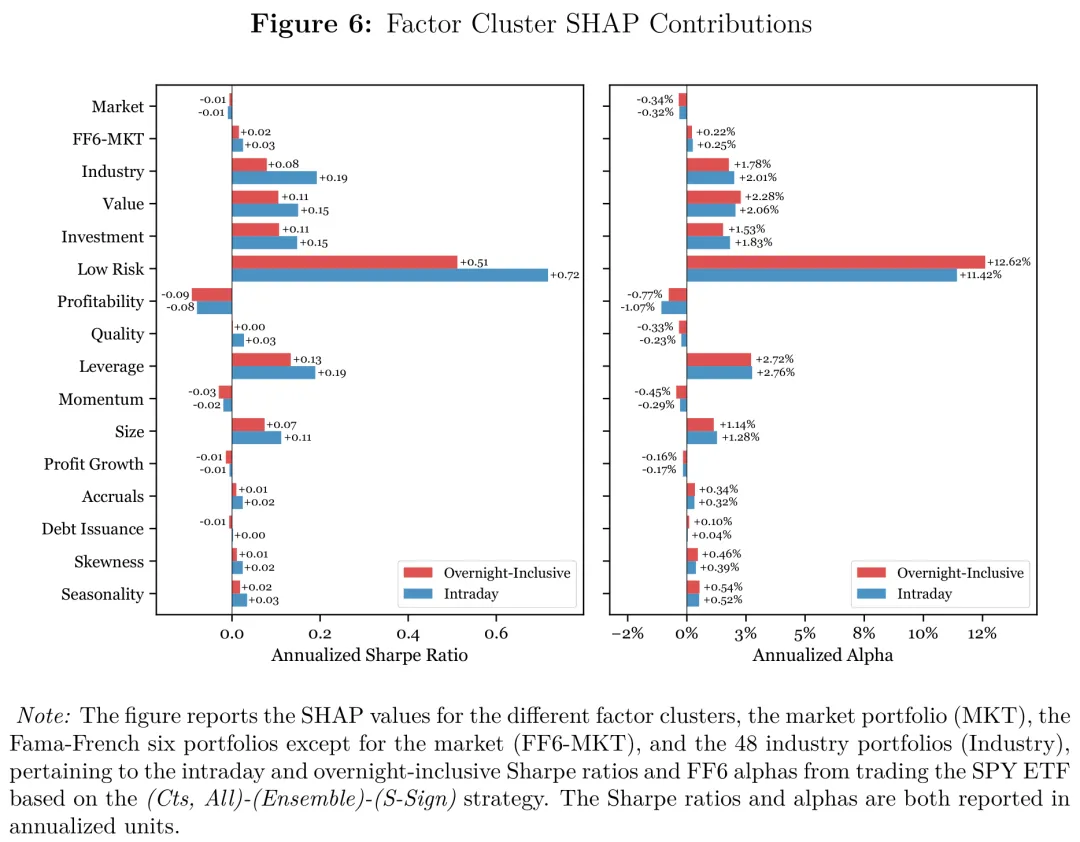
图:按因子簇(换手/流动性、低风险、尾部风险、动量、价值、规模等)给出的 SHAP 贡献条形图,用于说明超额表现主要由哪几类因子驱动,而大盘自身的贡献几乎可以忽略甚至为负。
归因结论相当干净:绝大部分超额表现可以追溯到换手率与流动性类因子,以及尾部风险/低风险类因子;相比之下,大盘组合自身(以及多数主流横截面因子簇)的贡献微乎其微。把视角落到单个因子,排名靠前的也大多是不同口径的换手率与“零成交天数”等流动性代理。作为佐证,按换手率高低对股票分组构造的多空组合,其日内累计收益也呈现出明显的可交易模式。
更重要的是环境依赖性:策略的优异表现高度集中在高不确定性时期。用隐含波动率(VIX,可理解为“投资者恐惧”)做条件,会发现 VIX 高企时策略的收益与 alpha 显著更好,而用已实现波动率做条件的解释力要弱得多——也就是说,起作用的更像是“前瞻的恐惧情绪”而非“事后的实现波动”。
把这些线索拼起来,背后的经济机制指向慢速资本与信息的渐进吸收:当市场承压、流动性变差、套利资本一时无法快速到位时,信息只能被逐步定价进去,从而在短时间窗口里留下可被横截面信号捕捉的可预测性。这与“套利受限”这一经典叙事一脉相承——摩擦越大的时候,可预测性反而越强。
九、给量化研究员的启示与现实约束
可以带走的几点方法论启示:
-
横截面因子的高频滞后收益,确实携带了关于大盘下一步走势的增量信息。把“解释横截面”的因子动物园反过来当成“择时”的预测器,是一个值得认真对待的方向。 -
预测目标的设计和预测变量同样重要。先把不可预测、又是极端值的跳跃从被解释变量里剔除,能显著改善拟合与净表现;跳跃—连续分解不只是计量上的洁癖,而是实打实地影响收益。 -
正则化是驯服动物园的前提。面对上千个高度共线的回归元,岭/Lasso/弹性网/树模型 + 等权集成,远比单一 OLS 稳健。 -
可解释性可以、也应该被工程化。SHAP 这类可加归因能把“黑箱”策略的收益来源拆给风控和投资经理看,本身就是研究流程的一部分。 -
成本与执行不是事后补丁。无交易带(只在信号超过半价差时才动手)直接决定净夏普;把换手、价差、做空成本写进目标函数,才是日内策略的正确打开方式。
同时,务必谨慎看待这些结果,几条现实约束需要量化团队自行评估:
-
数据门槛极高。整套方法的前提是先有一个覆盖两百多个因子、且做到 15 分钟级别的高频因子库。复现它的数据工程量极大,绝非拿现成日频因子就能套用。 -
明显的体制依赖。超额收益集中在高不确定性、高 VIX 的时段,平静市道里边际可能很薄;能否在长期里稳定收割,要打个问号。 -
学术口径成本 vs 真实执行。文中用的是极窄的平均价差和相对简化的成本模型;落到实盘,容量、冲击成本、日内撮合与滑点都会进一步侵蚀边际。这类“扣费后夏普 1.37”应理解为方法论上限,而非可直接照搬的实盘业绩。 -
样本区间有限(约 2004–2020),且方法本身较重。建议把它当作“思路与框架”去吸收和改造,而不是开箱即用的成品策略。
总的来说,对做日内/高频、市场择时与战术资产配置、因子 + 机器学习结合方向的研究员,这套“高频横截面信号 → 跳跃-连续分解 → 正则化预测 → 成本敏感交易 → SHAP 归因”的范式很有借鉴价值;其中的多个组件(尤其是跳跃剔除、无交易带、可加归因)即便脱离原始场景也高度可迁移。
参考文献
-
Aleti, S., Bollerslev, T., & Siggaard, M. (2024). Intraday Market Return Predictability Culled from the Factor Zoo. Working Paper, SSRN. https://ssrn.com/abstract=4388560
-
Corsi, F. (2009). A Simple Approximate Long-Memory Model of Realized Volatility. Journal of Financial Econometrics, 7(2), 174–196.
-
Mancini, C. (2001). Disentangling the Jumps of the Diffusion in a Geometric Jumping Brownian Motion. Giornale dell’Istituto Italiano degli Attuari, 64, 19–47.
-
Barndorff-Nielsen, O. E., & Shephard, N. (2004). Power and Bipower Variation with Stochastic Volatility and Jumps. Journal of Financial Econometrics, 2(1), 1–37.
-
Bollerslev, T., & Todorov, V. (2011). Tails, Fears, and Risk Premia. Journal of Finance, 66(6), 2165–2211.
-
Gârleanu, N., & Pedersen, L. H. (2013). Dynamic Trading with Predictable Returns and Transaction Costs. Journal of Finance, 68(6), 2309–2340.
-
Gu, S., Kelly, B., & Xiu, D. (2020). Empirical Asset Pricing via Machine Learning. Review of Financial Studies, 33(5), 2223–2273.
-
Lundberg, S. M., & Lee, S.-I. (2017). A Unified Approach to Interpreting Model Predictions. Advances in Neural Information Processing Systems (NeurIPS).
-
Chinco, A., Clark-Joseph, A. D., & Ye, M. (2019). Sparse Signals in the Cross-Section of Returns. Journal of Finance, 74(1), 449–492.