1053-中国模型在全球开发者市场反超,拿下调用量第一

-日知录1053-
(全文2164字,阅读需要7分钟)
2026年2月,OpenRouter平台的排行榜中,榜单前三名同时被中国模型占据。
1. 什么是OpenRouter平台排行榜?
OpenRouter是目前全球最大的AI模型API聚合平台,接入了60多个供应商的400多个模型,注册开发者超过500万。其中美国用户占47%,中国用户只有6%。这个比例很重要——这里的数据反映的是全球开发者的真实选择,不是靠某一个地区的用户支撑。
2月9日至15日,中国模型在平台上的调用量首次超过美国,4.12万亿对2.94万亿Token。第二周差距继续拉大,5.16万亿对2.7万亿,两周内中国模型增幅达127%。
到2月下旬,平台单周Token总消耗量达到12.1万亿,比一年前增长了12.7倍,中国模型占前十总量的61%。
2月下旬的具体排名是
MiniMax M2.5第一,Kimi K2.5第二,智谱GLM-5第三,DeepSeek V3.2第五。
前三名同时被中国模型包揽,这在OpenRouter历史上是第一次。
2.为什么是这几家,为什么是现在?
MiniMax M2.5于2026年2月13日发布,定位是专为Agent工作流设计的生产级模型。发布不到一周,单周调用量冲到2.45万亿Token,环比增长197%。
价格是核心驱动力。输入成本每百万Token约0.3美元,输出约1.1美元,而Claude Opus 4.6分别是5美元和25美元,差距在10到20倍之间。
但便宜不是唯一的解释。在SWE-Bench Verified这个软件工程能力的标准测试上,MiniMax M2.5拿到80.2%,Claude Opus 4.6是80.8%,差0.6个百分点。工具调用准确率上,MiniMax M2.5以76.8%反超Claude的63.3%。
这其中,Kimi K2.5的逻辑不同。月之暗面押注超长上下文,百万Token的窗口,让它在Agent需要长时间追踪任务状态的场景里有天然优势。
对于GLM-5,它曾短暂冲到排行榜第一,但需求超出了算力承接能力服务中断,公司被迫公开道歉,股价单日暴跌22%,市值蒸发超过100亿美元。
在这波上涨中,结构性原因是用户AI的使用方式变了。过去用AI是对话模式,一问一答,一轮几百到几千个Token。在AI代理的这一轮推升下,Agent工作流完全不同,AI需要反复读取日志、高频调用工具、多轮自我纠错,在超长上下文里持续追踪任务。
单次消耗是对话模式的几十倍。编程类任务在OpenRouter上的占比,从2025年初的11%涨到了50%以上,这是调用量能在一年内增长12倍的根本原因。
3.调用量激增的深层原因
这波数据背后有一个实用的分层逻辑,对个人开发者或企业用户来说,聪明的用法是核心智能体用最好的模型,负责任务拆解和顶层判断;执行层的子智能体用高性价比模型,跑工具调用、代码生成和进行日志处理。
所以在选模型之前,先想清楚这个任务在哪一层。需要复杂推理和综合判断的,贵的模型节省的是时间和出错成本。而对于重复性的工具调用和代码生成,工具调用准确率和速度比聪明程度更关键。另外,如果发现AI在长对话里开始忘事,上下文的支持度要大于模型本身不够聪明。
4.在这波数据后还有哪些思考
第一件,是安全问题。Agent工作流让AI拿到了越来越高的系统权限,但AI读取日志的方式,是默认把里面的内容当成可信的系统信息。提示注入的攻击正是利用这一点——攻击者在普通网页里用隐形字体埋入恶意指令,AI访问页面后,这段内容混进了日志,下次读取时就会被当成系统管理员发来的命令照单执行。这不是哪个模型特有的问题,是当前Agent架构的结构性漏洞。权限越高,这个漏洞能造成的破坏就越大。
第二件,是模型在执行层任务拿到的越多,获得的真实反馈就越多。哪种工具调用方式效果更好,哪类代码任务容易出错,用户在哪个节点会放弃——这些信息是花钱买不到的,只有在真实任务里才能积累。现在国产模型大量承接执行层,虽然表面上是在帮别人打下手,但另一方面也积累了更多的高质量数据,在用规模换迭代速度。
另外,开发者一旦把整套工作流在某个模型上调试好了,提示词、工具调用逻辑都适配完了,再换模型的成本很高,这个摩擦力本身也是一种护城河。
第三件,调用量的领先和公司活得好不好是两件事。国产模型的定价低,需要尽快在商业市场上拿到回馈。OpenAI 2025年的年度经常性收入已经超过200亿美元,有足够的钱持续砸研发。国内厂商目前基本还是用规模换时间,从用得多到活得好这中间的路还很长。
第四件,顶层和执行层之间的能力差距不是固定的。当前应用场景中,核心用Claude、执行层用国产模型这个分工,前提是两者之间现在还有明显的能力差距。但SWE-Bench的数据已经说明差距在收窄,而且执行层拿到的真实任务越多,迭代越快,这个差距收窄的速度会更快。
碎片收集











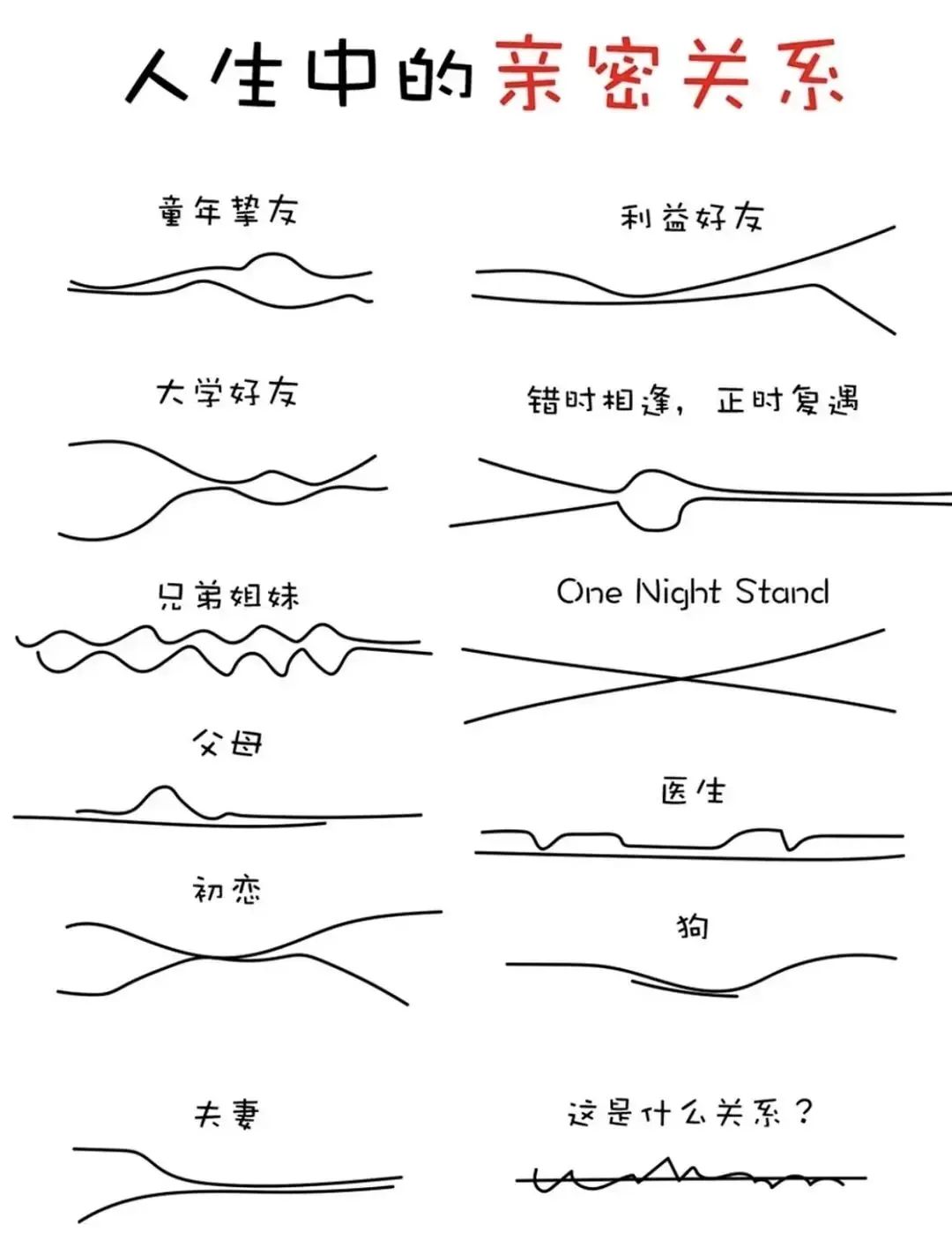
最后一个是什么呢,和自我的关系?






关 注 空 字 · 点 亮 在 看
公众号:空字
视频号:567个字
人生没有无用的经历,所以
我们一直走,天一定会亮
