算力限制将重塑市场份额分配
-
大模型前沿之争重回“双头垄断”局面: OpenAI 凭借 GPT-5.5 的发布重新回到了技术前沿,缩小了此前与 Anthropic(Claude 模型)的差距,目前智能体编码市场实质上是这两家公司的“双马竞赛”。
-
公开基准测试(Benchmarks)已严重失真: 厂商公布的基准测试分数往往无法真实反映模型在现实世界中的业务能力。测试框架的差异、测试题目的缺陷以及“刷榜(污染)”行为,导致这些数据具有极大的误导性。
-
“模型 + 框架(Harness)”才是完整的商业产品: 仅有底层模型是不够的,如何将模型与开发环境、工具链结合(如 Claude Code, Codex)决定了最终的用户体验和单次任务成本。纯粹依赖 API 的“套壳(Wrappers)”初创公司正在迅速失去竞争力。
-
算力限制将重塑市场份额分配: Anthropic 虽然在企业级/API 收入上处于领先,但由于算力分配策略和对 AGI 的过度关注,正在走“高端(依云水)”路线;这给了 OpenAI 抢回被挤出客户的巨大机会。
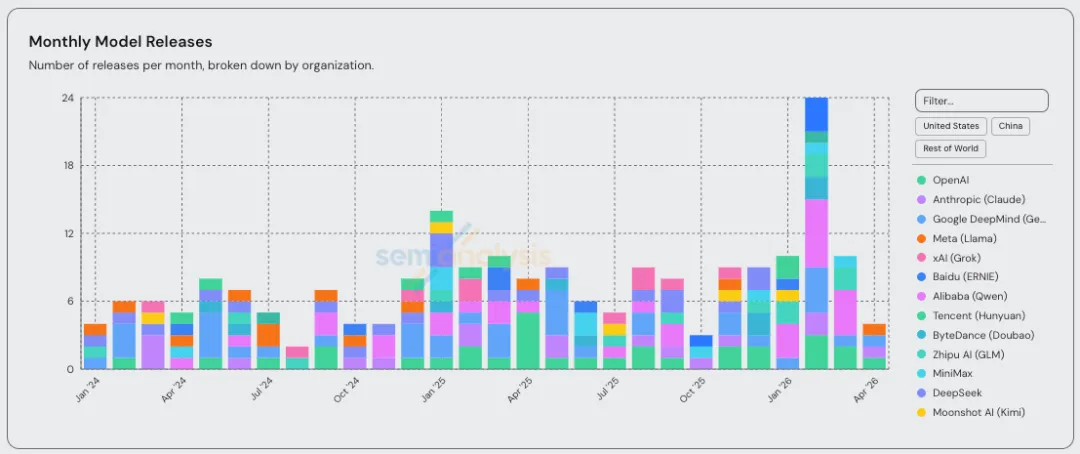
过去三个月,几乎每周都有一家大型实验室发布专为编码而设计的新版本。GLM-5.1、Qwen3.6-Plus、Kimi K2.6、Composer 2 和 Gemini 3.1 Pro 都在其产品宣传中强调了“智能体编码”、“长期任务”或类似功能。
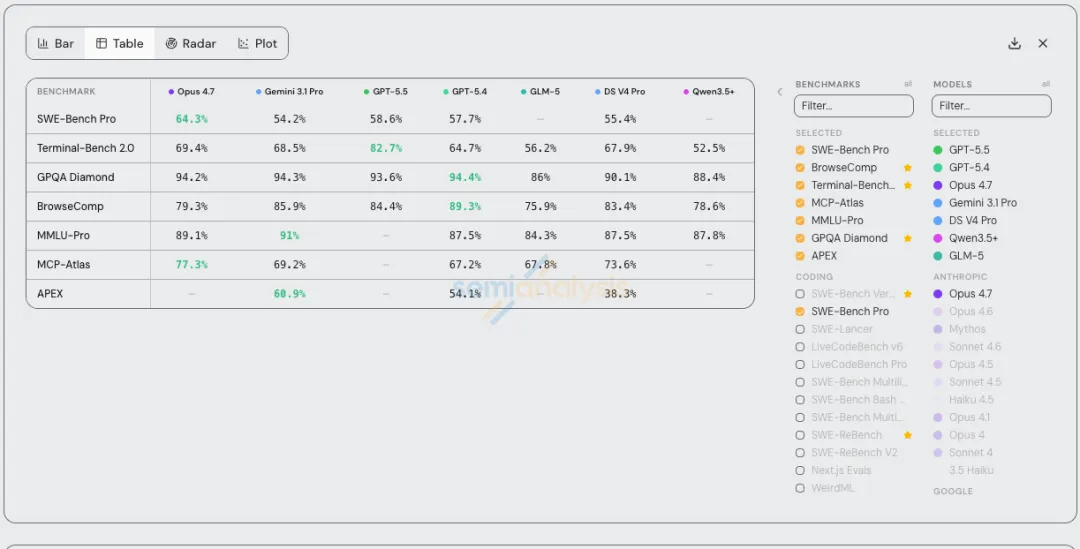
1. 头部模型的实测表现对比:
-
GPT-5.5 (OpenAI): 相比前代实现了显著提升。在 Codex 环境下,它能更好地收集上下文并进行深度推理,但在代码修改上偏向保守(有时牺牲了正确性以换取代币效率)。目前其能力已足以与 Opus 4.7 媲美,让许多工程师将其作为解决复杂逻辑的日常工具。
-
Opus 4.7 (Anthropic): 虽然依然是许多开发者的主力,但本次更新被认为是“挤牙膏”,更多是功能上的调整(支持高分辨率图像、调整默认推理层级等),且采用了新的代币计费方式,变相涨价了约 35%。同时,Anthropic 近期还暴露出持续数周未被发现的严重产品漏洞。
-
DeepSeek V4: 作为开源之光,实现了百万上下文和极高的缓存效率(KV Cache 减少 90%),在成本上极具优势,但其核心能力在处理极端复杂任务(如极难的中文写作)时,依然落后于闭源的顶级前沿模型。
2. 基准测试的“致命缺陷”拆解:
-
题目质量堪忧: 例如 SWE-bench(编码基准)中许多任务描述含糊,甚至测试用例本身就存在错误,导致 AI 即便给出正确答案也会被判错。
-
数据污染与过度定制: 很多测试题源于公共代码库,模型在预训练时可能已经“背下”了答案(如 GPT-5.2 和 Opus 4.5 都被发现有此现象)。此外,各家实验室在测试时使用不公开的自定义框架(Harness),导致横向对比(Apple-to-Apple)毫无意义。
-
脱离现实工作流: 像 GDPval 这种模拟人类工作的测试,其提示词过于明确、不自然,且缺乏现实工作中基于人类反馈的“多轮迭代”过程。
3. 财务与市场数据指标:
-
Anthropic 的经常性收入(ARR)实现了从 90 亿到 400 亿美元的惊人跨越,且约 70% 来源于 API 调用(高质量的B端部署收入),在这一点上曾一度反超 OpenAI。
-
第三方代码辅助初创公司(如 Cognition, Replit 等)即便营收增长,但毛利率往往为负,且其核心 ARR 加起来仅为几十亿美元,远低于底层模型厂商从该领域获取的价值。
-
Anthropic 是当前高价值市场的领跑者: 凭借 Claude Code 在智能体编码领域的统治力,Anthropic 获得了高质量的商业变现,并在企业级开发市场占据了主导地位。
-
OpenAI 将迎来绝地反击的窗口期: 尽管前几个月表现乏力,但随着 GPT-5.5 证明其达到了前沿水平,且 Anthropic 因算力紧张开始采取限流、涨价等“赶客”策略,OpenAI 将顺势接盘这些溢出的市场需求。
-
开源模型定位明确但无法颠覆头部: DeepSeek 等开源模型将继续作为低成本替代方案存在,但无法蚕食要求最高技术前沿的专业工作流(如高级智能体编码)市场。
-
“套壳”编码应用将面临生死存亡: 随着 OpenAI 和 Anthropic 将模型与官方测试框架/客户端深度绑定并不断完善,中间层的初创公司将失去生存空间,真正的护城河依然在底层模型的推理能力与官方工具生态的结合上。
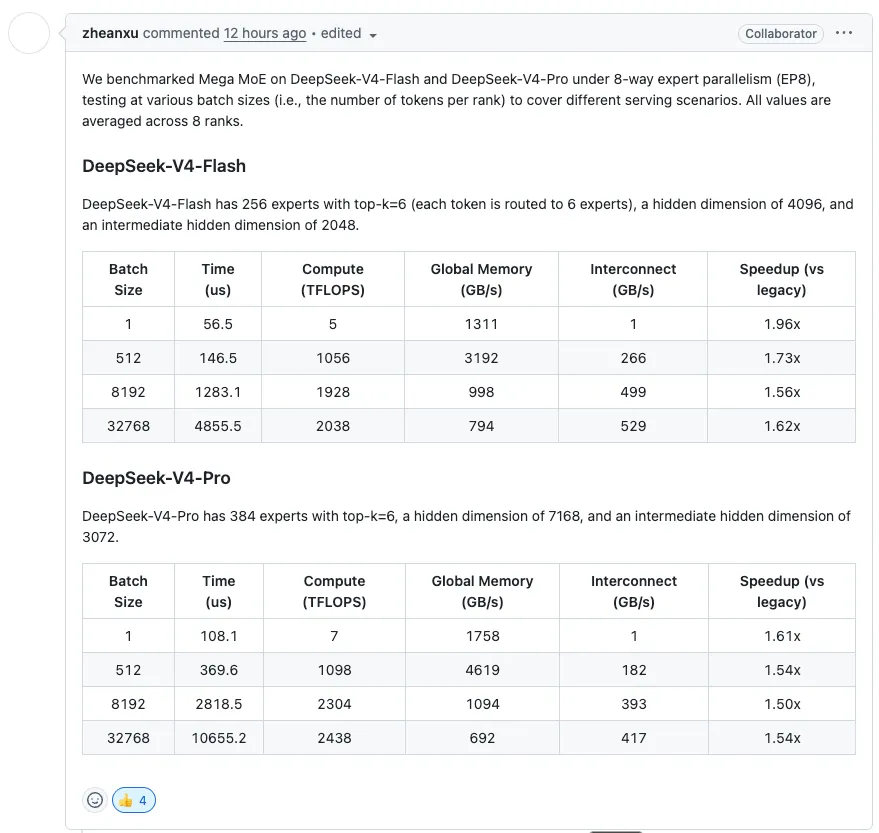
DeepseekV4 相较于 V3 的核心改进在于将上下文窗口从 128k 提升至 1M。因此,所有主要技术改进都集中在提升长上下文性能上:压缩稀疏注意力(CSA)、高度压缩注意力(HCA)、流形约束超连接(mHC)
“在百万令牌场景下,DeepSeek-V4-Pro 仅需 DeepSeek-V3.2 的 27% 单令牌推理浮点运算次数和 10% 的键值缓存。” 这意味着键值缓存减少了 90%,远超谷歌上个月发布的 TurboQuant 论文!NAND 闪存投资者们,请注意了。
在基准测试方面,DeepSeek 认为标准基准测试无法很好地反映实际任务能力,因此他们引入了一套自主开发的智能体基准测试,以衡量 V4 与其他最先进模型(SOTA)的差距:包括中文写作、检索增强搜索、一系列具有长期影响的白领任务以及编程。V4 Pro 在所有这些任务上都能与顶级模型相媲美,但在一些关键领域仍落后。例如,在难度极高的中文写作任务上,Claude Opus 4.7 仍然优于 DeepSeek V4 Pro。Claude 在其母语中文方面遥遥领先于其他中文模型。
DeepSeek 还开源了 DeepGEMM 内部的一个 Mega-Kernel,该内核同时支持 NVIDIA GPU 和华为 Ascend NPU 。虽然声称支持 NPU,但目前仅公开了 SM90 (Hopper) 和 SM100 (Blackwell) GPU 的代码。DeepSeek 的目标很可能是让未来相当一部分推理流量运行在 Ascend 上。值得注意的是,参数大小刚好能容纳 8 倍 H20 HGX 在 FP4 下的内存空间。