宇宙在熵增,市场在筛选:从十种 OS 到两种 Agent 方法
物以稀为贵。
宇宙没在熵减——市场是一台 Maxwell’s demon,让低熵的赢家活下来。
一、周末下午
2026 年 5 月,周日下午。
我坐在队友旁边,看他用 Claude 写代码。
处理 log 的脚本——AI 写 Python,他点 accept。 Web 前端——React + TypeScript,accept。 高并发网关——Go,accept。 底层系统——Rust,accept。
四个完全不同的活儿,AI 一句”应该用什么语言”都没问。他也没问。他就这么接受了 AI 的默认。
这是个微小但精确的征兆——不是世界在变小,是市场替这位工程师做了选择。市场把那些 AI 写不顺手的语言,安静地从他的视野里移走了。
这件事的尺度比”AI 写代码”大得多。往前看四十年,市场已经做过两次同样的事。
二、宇宙在熵增,市场在筛选熵减
先把一件容易混的事说清楚——宇宙没在熵减。第二定律没退休。
但市场不是宇宙。市场是一台筛选器——它消耗外部能量(电力、资本、注意力、太阳能),把一波又一波产品扔进去,然后让符合某种”低熵纪律”的那些活下来。
你看到的”市场收敛”,是这台筛选器留下的痕迹。不是熵自己在减少,是高熵的玩家被淘汰了。
这件事在物理上有一个精确的对应——Maxwell 的 demon。
Maxwell 1867 年那个思想实验里,一只虚构的 demon 站在两仓气体中间,让快分子去左、慢分子去右——用信息分类降低气体熵。代价是 demon 自己消耗能量(Landauer 1961 年给的下限:每分类一个比特至少要 kT ln 2 焦耳)。
市场就是这只 demon 的市场版:用能量换信息分类,把高熵产品筛出去。
整个系统(市场 + 数据中心 + 大气 + 太阳)的熵仍在涨。
市场内部的低熵,是从外界借来的。
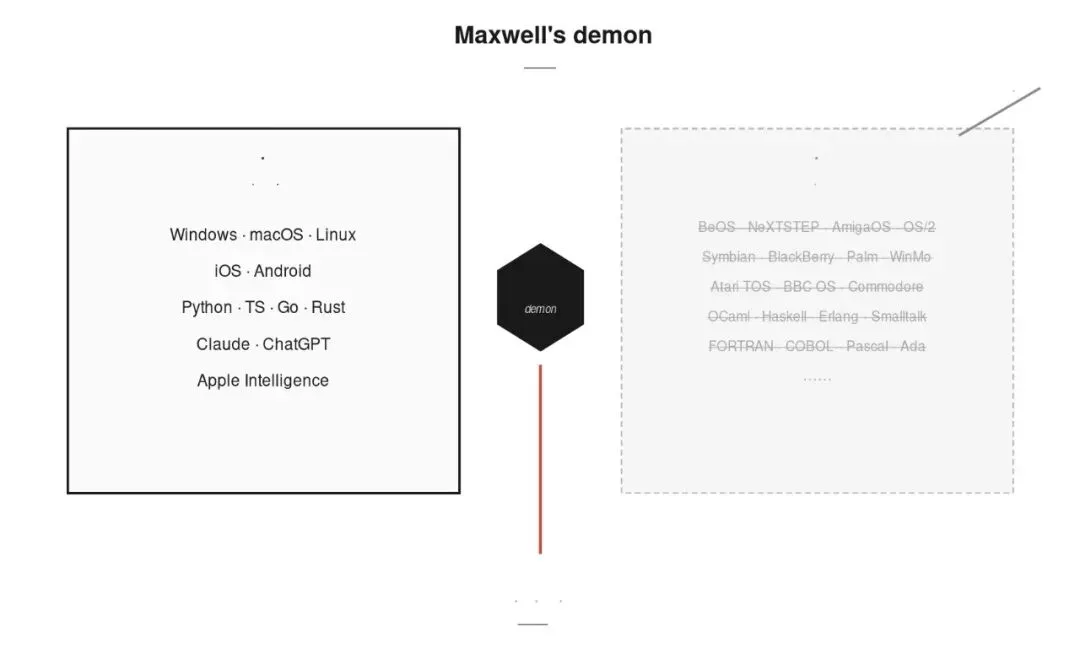
图 1 · 市场版 Maxwell’s demon · 左仓存活的是低熵产品(码本干净、可识别),右仓被筛掉的是高熵产品(码本混乱、不可预测)· demon 标着”市场”,能量从下方输入(电力 / 资本 / 注意力 / 太阳能)· 废热从右上排出(散热 / 死掉的产品 / 失败的创业)· 整个系统熵仍在涨——左仓的低熵是从右仓借来的
过去四十年里,这只 demon 至少跑过两次半——
- 第一次
:1980s–2000s,桌面 OS 从十几种 → 三种 - 第二次
:2007–2020,手机 OS 从十几种 → 两种 - 第三次(正在发生)
:编程语言、agent 方法、AI 应用层
下面三次一起拆。
三、第一次:OS 市场筛掉了高熵的玩家
1985 年的桌面 OS 市场是混乱的——MS-DOS、Mac System、Apple DOS、Atari TOS、AmigaOS、OS/2、BeOS、NeXTSTEP、SCO Unix、Xenix……
四十年后:Windows ~70%、macOS ~20%、Linux ~5%。剩下加起来不到 1%。
被筛掉的那些——BeOS、NeXTSTEP、AmigaOS——技术不差,反而更强。AmigaOS 1985 年就有抢占式多任务,比 Windows 早十年。它们死,是因为码本太混乱:API 不稳定、驱动碎片化、应用生态分裂。开发者要花更多力气,才能在它们身上写出一个能用的应用。
留下来的三家——Windows、macOS、Linux——各自占据一个接收端先验(办公、创意、服务器/开发者),在那个先验下都是码本最一致、最低熵的那一个。
第一次筛选的判据:谁的码本越干净,开发者写应用的协作成本越低,谁活下来。
四、第二次:App Store 把”低熵”做成了入场合约
2007 年的手机系统也是一团乱——Symbian、Windows Mobile、BlackBerry、Palm、Maemo、iPhone OS、日厂各种私有 OS。
到 2020 年:iOS ~25%、Android ~74%、其他 < 1%。比第一次更激烈。
发动机是同一台筛选器,加上一个新东西——App Store。
App Store 不只是分发渠道。它是一份强制低熵合约:必须用平台 SDK、必须遵守 HIG / Material 设计语言、必须用平台支付通道、必须过审。
码本一致性,从开发者自律变成了平台强制。
第二次筛选的特征:低熵从开发者纪律升级成平台合约——筛选门槛被显式化、合约化、机器可执行。
五、第三次进行时:编程语言被 AI 筛选
2026 年的编程语言市场早已是 Zipf 分布——Python / JS / TS / Java / C++ / C# / Go 占据前列,Rust / Swift / Kotlin / PHP / Ruby 是第二梯队,长尾里 Scala / Haskell / OCaml / Erlang 各占 < 1%。
AI 进来后,这台 demon 多了一个新的筛选维度:这门语言在训练语料里的占比。
LLM 写代码的能力和训练分布严格成比例。然后是一个干净的循环:
AI 在主流语言上写得好 → 用户用 AI 时默认主流 → 主流代码增多 → 下一代 AI 在主流上更强。
OCaml 不会消失。但它的下一代用户会越来越少——因为他们没有 AI 加成,相对成本被 AI 推得更高。
第三次筛选的发动机:AI 把”码本一致性”从平台合约升级成训练数据分布——筛选得更细、更快、更不可逆。
注意”账单”这一维度的变化——
-
OS 收敛:消费者付(重新学习应用的成本) -
手机收敛:开发者付(重写 app 的成本) -
AI 让语言收敛:Anthropic / OpenAI / Google 几家公司集中付(GPU 集群烧的电)
集中支付意味着:demon 跑得更快。
六、Codex 方法 vs Claude 方法
—— 同一台 demon 在 agent 层面再跑一遍
收缩不会塌成 1 个。还是按”接收端先验有几种”那条规则数。
|
|
|
|
|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
两份码本,两个先验子集。加上 Cursor 那种”轻量补全”的第三类——很可能塌成三家,再多就靠不住了。
放大一档看,整个 AI 应用层正在变成下一代 OS。同样的筛选剧本会再跑一遍:
|
|
|
|---|---|
|
|
|
|
|
|
|
|
|
桌面 OS 用了 20 年塌定,手机 OS 用了 13 年。这一次会更快——因为账单(GPU 烧的电)由少数几家公司集中付,demon 跑得快。

图 2 · 三次筛选的时间轴 · 桌面 OS(1985 → 2005,约 20 年塌定)· 手机 OS(2007 → 2020,约 13 年)· AI / 编程语言(2024 → 估计 2030 之前)· 关键变化在账单付费方——前两次是消费者和开发者各自付,这一次由几家公司集中支付(GPU 集群烧的电)· 集中支付意味着 demon 这次跑得最快
最深一层——“OS”这个词最终会消失。桌面时代你说”我用 Windows”,手机时代说”我用 iPhone”(”iOS”都不提了),AI 时代会说:
“我用 Claude。”“我用 Apple。”“我用 ChatGPT。”
OS、硬件、应用、品牌——全部塌成一个名字。这是熵减最深的一层:抽象层级被压扁。
七、反向的力 —— 筛选不会塌到一个点
物理上,筛选永远不会塌成 1。三件事一直在制造新的高熵——
- 新硬件 = 新先验
:GPU 让 CUDA 活着,端侧推理让 llama.cpp 活着。 - 新场景 = 新约束
:实时系统(VxWorks)、安全关键(Ada)、形式化验证(Coq、Lean)——它们的接收端先验和主流不重合,码本永远不塌。 - 新创业 = 新噪声
:每一波创业、每一个被冷落的角落里冒出来的 niche 工具——短期看是噪声,长期是下一次熵增的种子。
没有噪声的信道是死信道。没有长尾的市场是死市场。
筛选 + 变异,构成市场进化的全部动力。这一点和达尔文那条进化机制严格同构——遗传变异是噪声源,自然选择是 Maxwell demon。
八、回到”物以稀为贵”
回到开头那件事——
筛选之前:”会写 OCaml”、”会用 BeOS”、”会装 Symbian app”——这些稀缺。
筛选之后:剩下的选项被工具链优化到极致——会写 Python 不再稀缺。但是——
- 会判断”该不该做这件事”
—— 变得更稀缺 - 会判断”做出来的有没有审美”
—— 变得最稀缺
技术差异会被筛选抹平。审美判断不会。
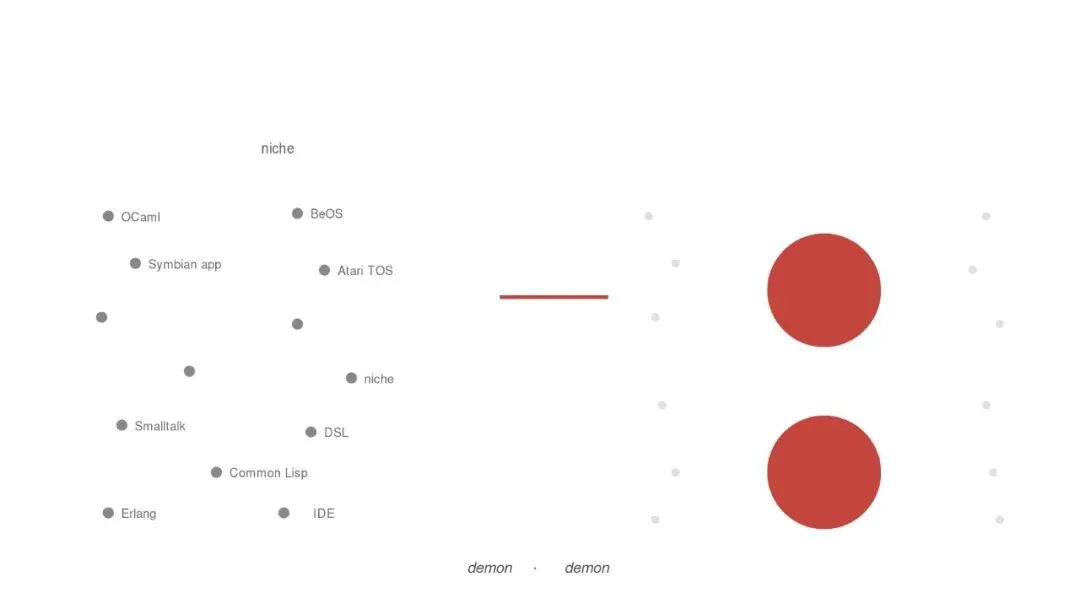
图 3 · 稀缺性的转移 · 筛选之前:稀缺散落在所有 niche 选择上(OCaml、BeOS、Symbian、独立工具链、自己写脚本……)· 筛选之后:技术能力被工具链优化到极致,稀缺塌进两个核心判断——”该不该做这件事” + “做出来的有没有审美” · 技术能力是 demon 的工作,审美判断是 demon 拿不走的那一部分
这就是 LE LABO 这种品牌在筛选越来越严的世界里反而更值钱(LIFE 03 讲过)——它本身就是一个低熵存活者,且它码本里写的”克制 / 不解释 / 留白”全是审美判断。
筛选器筛得越细,审美判断的相对溢价越高。
技术能力是 demon 的工作。
审美判断是 demon 拿不走的那一部分。
九、道与术
道——
宇宙在熵增。市场是一台筛选器,让低熵的存活下来。这台筛选器不可逆——它的发动机是物理性质的(preferential attachment + Zipf + Maxwell demon-style 信息分类)。
你的工作不是逆筛——逆不动。
你的工作是找到筛选之后哪里还有稀缺,把自己放到那个位置上。
术——
每一次扩张性决策(新工具、新语言、新方法),问自己同一个问题:
我是在选码本里的东西(享受筛选红利、便宜、可复用、AI 友好),还是在选码本外的东西(独特、贵、AI 帮不上、但稀缺)?
两个答案都对——前提是你知道自己在选哪个。
混着选的人最危险——既享受不到主流红利,又拿不到长尾稀缺溢价。
剩下的,全是品味的事。
宇宙在熵增。
市场把熵增的一部分能量花在”让低熵存活”这件事上。
这就是为什么二十年后,仍然会有人记得 LE LABO,仍然会有人记得 Claude vs ChatGPT 那两年的语气差,仍然会有人记得”还能自己写代码”是种独特的事。
关于作者
Sean · seanslab.org 一份用信息论看世界的尝试。