AI时代沙龙精选 | 蒋舸:《什么市场?如何失灵?AI训练合理使用问题的“分而治之”之路》

本次分享围绕人工智能(AI)与版权交叉领域的核心焦点,即AI训练的合理使用判定问题展开,以传统版权合理使用的法经济学分析思路为切入点,探讨AI训练相关责任的合理认定路径。

一、版权合理使用的核心逻辑:法经济学视角下的市场失灵

探讨AI训练的合理使用判定,需首先回归版权合理使用制度的法经济学基础。尽管法律明确界定了多种合理使用场景,但其背后的核心逻辑始终是市场失灵理论。
具体而言,当使用方向权利方获取许可的交易成本,高于交易所能带来的收益(至少高于使用者自身可获得的收益)时,使用者将因交易摩擦过高,放弃该种对社会总福利具有提升作用的使用行为。此时,若法律未将其认定为可免责的合理使用,将陷入两种困境,要么使用者放弃使用,阻碍社会福利的提升;要么使用者违规使用,损害法律的权威性。
该理论可有效解释私人使用、图书馆使用等传统合理使用场景,即便存在“交易成本如何认定”“货币化福利能否涵盖所有社会需求”等细节争议,但总体而言,其仍是解释各类合理使用场景的通用框架。这一理论的核心内涵可概括为,若市场存在失灵,则认定为合理使用;若市场未出现失灵,则不认定为合理使用。
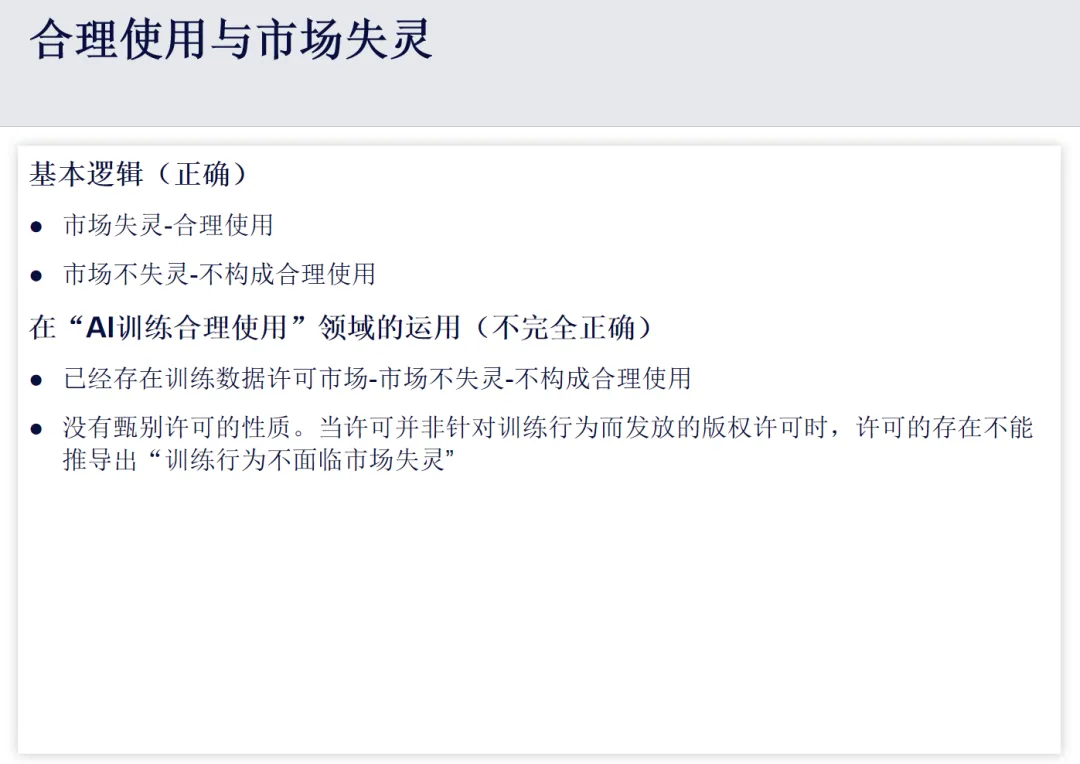

二、AI训练合理使用判定的主流偏差:混淆“许可市场”的核心内涵

将市场失灵理论应用于AI训练的合理使用判定时,当前主流观点存在明显偏差。
当前一种主流观点认为,AI训练市场未出现失灵,其理由是训练数据许可市场已存在且处于发展阶段,许可市场的存在即证明市场未失灵,进而得出“AI训练不构成合理使用”的结论。但该观点过于笼统,忽略了关键前提,许可市场上的交易,与AI训练阶段的版权许可并非同一概念,需明确区分AI训练所涉及的具体市场,以及该市场是否真正存在失灵。
美国版权局2025年发布的《AI与版权报告三》便是该类笼统观点的典型代表。该报告指出,当前已存在活跃的自愿许可市场,且取得了早期成效,应持续推动许可市场发展,仅在许可市场无法覆盖的领域,考虑延伸性集体管理等替代方案。但结合实际案例分析可见,该观点混淆了“训练数据许可”与“AI训练的版权许可”的核心边界。

三、案例佐证:区分训练数据许可与AI训练版权许可

多个典型案例可清晰佐证上述观点,当前AI训练相关的付费行为及责任承担,大多与训练本身的版权无直接关联。
在英国法院审理的Getty诉OpenAI案中,OpenAI承担的是商标侵权及防假冒责任,而非因使用作品进行训练所产生的版权责任,其核心症结在于其输出内容未经许可使用了Getty的商标,与训练本身的版权问题无任何关联;美国版权局所提及的“成熟训练数据市场”中,AI公司支付的费用,更多用于支付数据搜集、整理、分类、打标、清洗等劳动成本,或是数据背后的商业秘密对价,而非针对作品本身用于训练的版权许可费用,即便数据中包含版权作品,其付费核心亦非版权许可。

再看慕尼黑法院审理的Gemini诉OpenAI案,OpenAI支付的费用,系因训练后输出内容与原作品构成实质性相似(如歌词),属于训练后的版权责任,而非训练过程本身的版权对价;巴斯弗斯诉Anthropic案的15亿美元和解,核心争议在于训练前使用盗版来源的合法性,且高额和解金源于美国高额赔偿金制度,并非针对训练本身的版权许可费用。
上述案例共同表明,当前学界及实务界讨论的AI训练相关付费与责任,大多不基于训练本身的版权;即便涉及版权问题,亦集中于训练前的数据来源合法性或训练后的输出内容侵权,与训练过程本身的版权许可无涉。因此,不能以“存在训练数据许可市场”为由,推定AI训练市场未出现失灵。

四、AI训练本身必然存在市场失灵

回归核心问题,AI训练本身所对应的市场究竟是否存在失灵?本人认为,训练本身必然存在市场失灵,但失灵原因并非“权利方或使用方数量过多”,亦非“许可费用过高”。
其核心症结在于,单个作品对AI模型的边际贡献极其有限,无法覆盖将该种边际贡献单独拆分、测度并支付对价的社会成本,这是典型的测度成本难题。该类测度成本无法通过集体管理组织予以解决:即便集体管理组织能够解决收费问题,亦难以破解费用分发的困境。单个作品的边际贡献过于细微,难以实现精准测度,进而无法将相关费用合理分配至每一位权利人手中。
从经济理性视角来看,针对训练本身以作品为基础收取版权许可费,缺乏现实可行性,目前尚无有效方式可明确单个作品的边际贡献具体数值,其测度成本远高于贡献本身的价值。

五、合理路径:回归本质,破解AI与版权的核心争议

当然,AI发展所带来的社会挑战不容忽视。若需AI公司为受技术替代影响的群体提供补贴,可通过福利保障、税收调节、产业补贴、支付转移等多种路径展开探讨,该类路径具有开放性与合理性。
但关键在于,AI公司的付费行为必须“名正言顺”,不得将非版权性质的付费(如商业秘密对价、劳动报酬)与训练本身的版权许可费混为一谈,更不能借助版权制度解决训练环节的付费问题,这一做法本质上是调用了错误的分析框架,版权许可费的核心考量逻辑,与福利、税收的考量逻辑存在本质差异。
综上,我们可针对AI训练前的数据整理、训练后的输出侵权等环节设定付费机制,但针对训练本身收取版权许可费,缺乏经济理性。相关讨论应回归问题本质,在对应的制度框架下有序展开,避免“挂羊头卖狗肉”的逻辑错位,方能真正破解AI与版权交叉领域的核心争议。

-END-
