自动检测你的电脑硬件配置,筛选出最适合你机器运行的大模型,并给出详细的性能评分和运行建议.
llmfit
“ 一款终端工具,能够自动检测你的电脑硬件配置(RAM、CPU、GPU),从 497 个大语言模型中智能筛选出最适合你机器运行的模型,并给出详细的性能评分和运行建议。
Github地址
https://github.com/AlexsJones/llmfit
功能特性
智能硬件感知
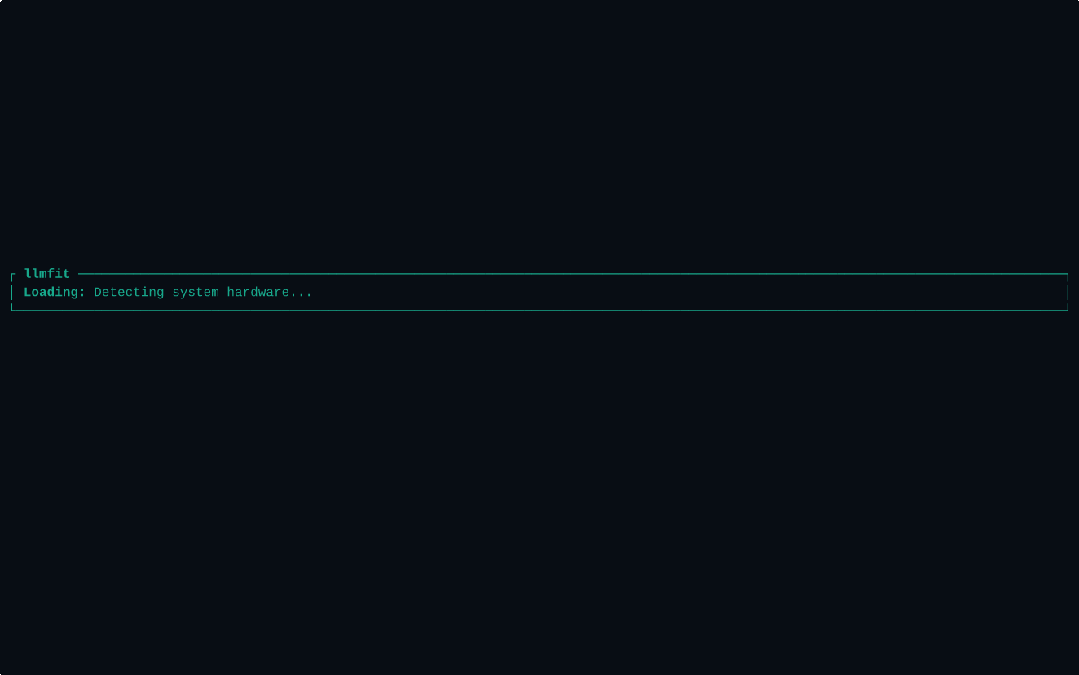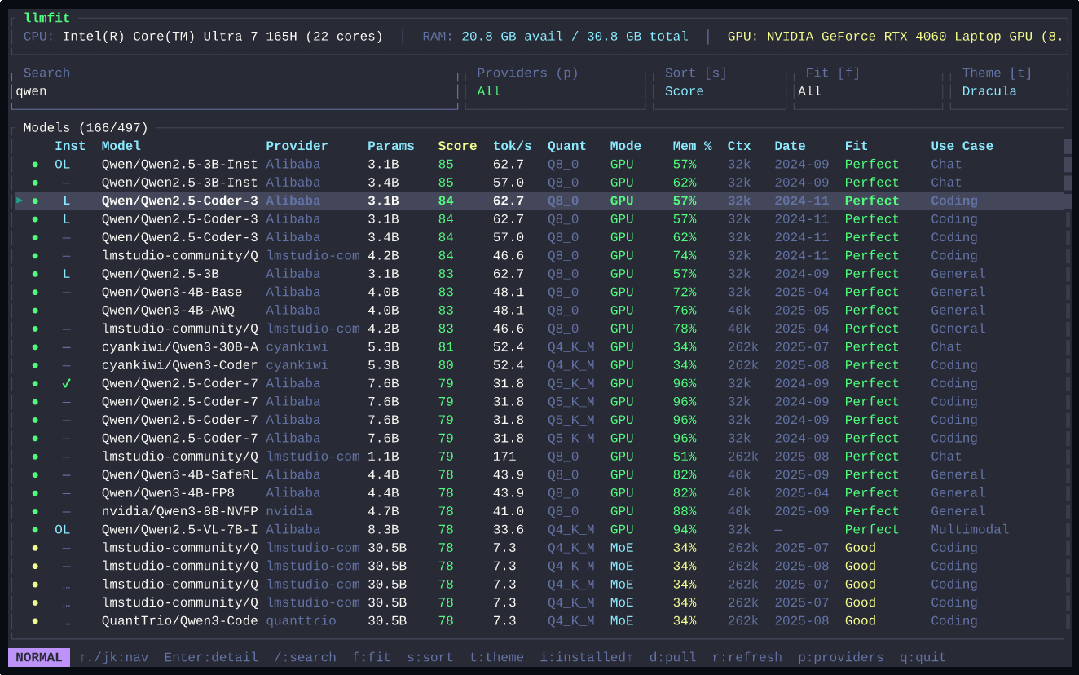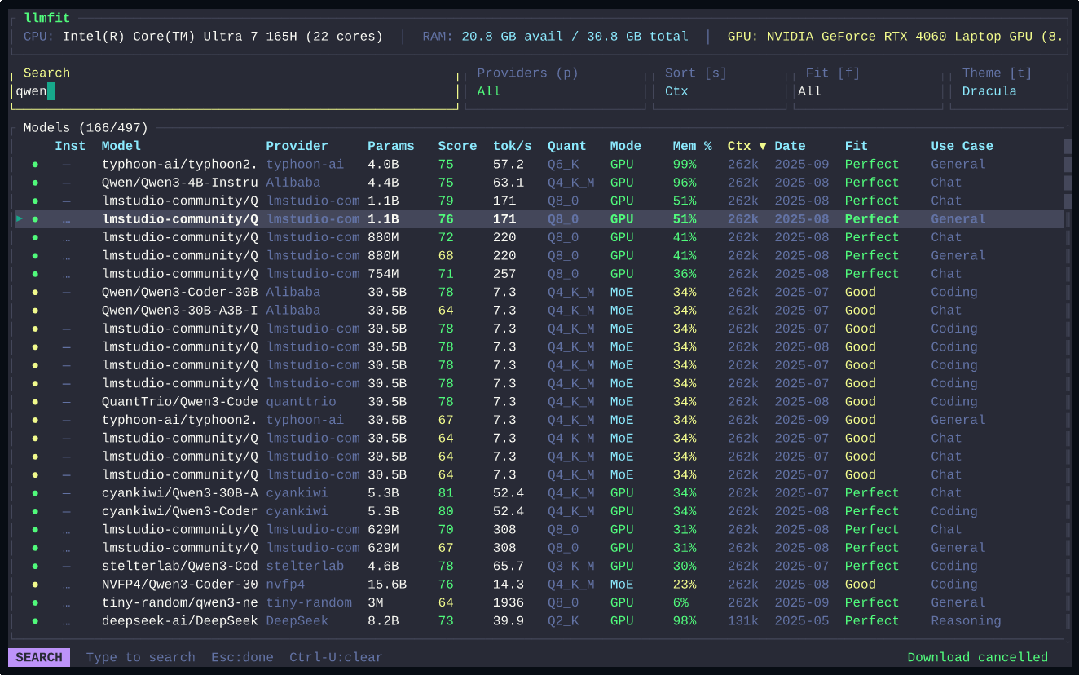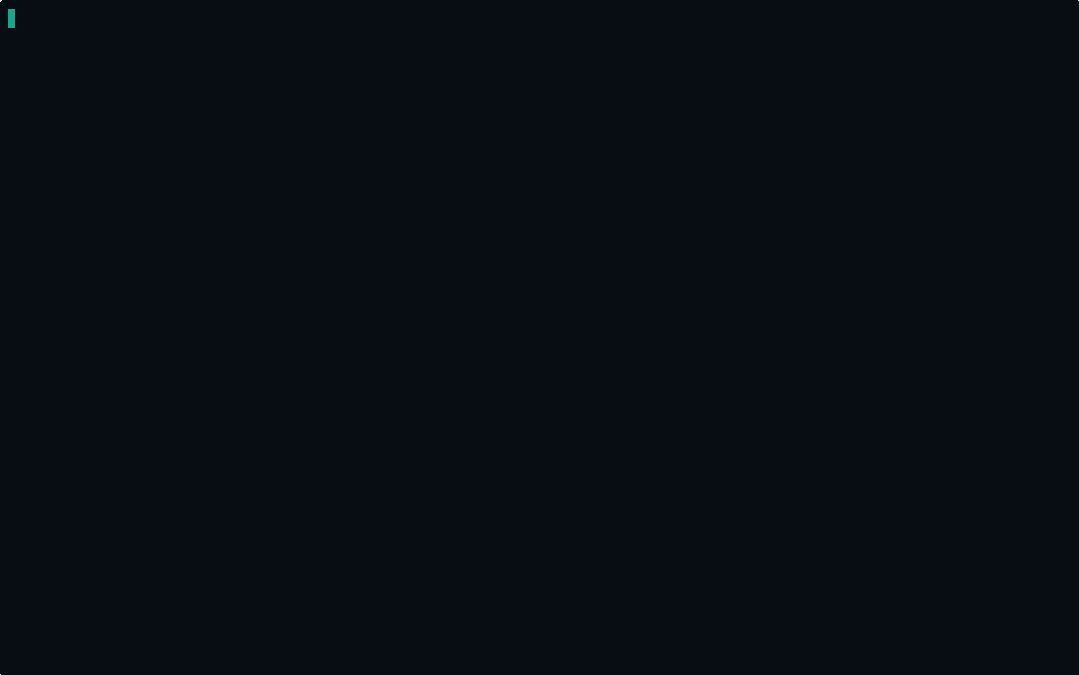
llmfit 启动时会全面扫描你的系统:通过 sysinfo 读取内存和处理器信息,识别多显卡配置——NVIDIA 显卡调用 nvidia-smi 精确获取显存,AMD 显卡通过 rocm-smi 检测,Apple Silicon Mac 则利用 system_profiler 获取统一内存。即使自动检测失败,你也可以用 --memory 参数手动指定显存大小,工具会据此重新计算模型适配性。
海量模型数据库
内置 497 个模型,涵盖 133 个提供商,从主流的 Meta Llama、Mistral、Qwen、Google Gemma,到专业的编程模型如 CodeLlama、StarCoder2、Qwen2.5-Coder,再到推理专用模型如 DeepSeek-R1、Orca-2,以及多模态视觉模型如 Llama 3.2 Vision、Llama 4 Scout/Maverick 等,几乎覆盖了当前开源生态的全部重要模型。
动态量化与 MoE 优化
工具不会死板地套用固定量化方案,而是从 Q8_0(最高质量)到 Q2_K(最高压缩)逐级尝试,自动为你的硬件选择能容纳的最高质量量化版本。对于 Mixtral、DeepSeek-V2/V3 等混合专家(MoE)架构,llmfit 能识别其稀疏激活特性——例如 Mixtral 8x7B 总参数量 46.7B,但每 token 仅激活约 12.9B,显存需求从 23.9GB 骤降至约 6.6GB,避免用户因误解而错过可运行的优质模型。
多维度智能评分
每个模型从四个维度获得 0-100 的评分:质量(参数量、模型家族声誉、量化损失、任务匹配度)、速度(基于后端和量化估算的 token/秒)、适配度(内存利用效率,50-80% 为最佳区间)、上下文(上下文窗口与目标场景的匹配)。系统根据使用场景(通用、编程、推理、聊天、多模态、嵌入)动态调整权重——聊天场景更看重速度,推理场景则优先质量。
双模式交互体验
默认启动交互式 TUI(终端用户界面),顶部实时显示硬件规格,下方是可滚动排序的模型列表,支持搜索过滤、主题切换、一键下载。按 p 键进入”规划模式”,可以反向推算运行特定模型配置所需的硬件;按 d 键直接下载选中的模型。偏好传统命令行的用户加上 --cli 参数即可获得简洁的表格输出。
本地运行生态整合
深度集成 Ollama、llama.cpp、MLX 三大本地运行框架,自动检测已安装的模型并标记,支持从 TUI 内直接拉取新模型。Ollama 用户还可通过 OLLAMA_HOST 环境变量连接远程实例,实现笔记本客户端 + GPU 服务器的灵活架构。
部署与使用方式
快速安装(推荐)
macOS 与 Linux 用户一行命令完成安装:
curl -fsSL https://llmfit.axjns.dev/install.sh | sh无需 sudo 权限时,安装到用户目录:
curl -fsSL https://llmfit.axjns.dev/install.sh | sh -s -- --localHomebrew 用户:
brew tap AlexsJones/llmfitbrew install llmfit从源码构建
git clone https://github.com/AlexsJones/llmfit.gitcd llmfitcargo build --release# 二进制文件位于 target/release/llmfit日常使用
启动交互式界面:
llmfit纯命令行模式,查看前 5 个完美适配的模型:
llmfit fit --perfect -n 5查看系统硬件信息:
llmfit system搜索特定模型:
llmfit search "llama 8b"规划运行配置所需的硬件:
llmfit plan "Qwen/Qwen3-4B-MLX-4bit" --context 8192手动指定 24GB 显存进行计算:
llmfit --memory=24G --cli限制上下文长度为 4096 进行估算:
llmfit --max-context 4096 --cliJSON 格式输出(便于脚本调用):
llmfit recommend --json --limit 5