

偏度离散度与股票市场收益预测
引言:为什么我们需要关注偏度的截面分布?
股票市场收益的可预测性一直是量化金融研究的核心问题。过去数十年间,学术界提出了大量宏观经济和金融变量来预测市场总体收益——从经典的股息率、期限利差,到近年来基于期权隐含信息和投资者情绪的指标。然而,Welch and Goyal (2008) 的开创性研究给这些预测变量泼了一盆冷水:绝大多数变量在样本外表现不佳,无法跑赢简单的历史均值基准。
这一发现引发了关于市场可预测性的持续争论。近年来,高阶矩——尤其是偏度(skewness)——在解释个股截面收益方面展现了显著能力。直觉上,投资者对资产收益分布的非对称性有强烈偏好:他们倾向于追逐正偏度资产(小概率大收益),同时规避负偏度资产(小概率大损失)。然而,一个有趣的谜题是:尽管偏度在截面定价中扮演重要角色,它在时间序列层面预测市场总体收益的能力却一直表现平平。
Jondeau, Zhang, and Zhu (2019) 在这个方向上取得了突破,他们发现公司层面的平均已实现偏度(average realized skewness)可以预测未来的市场收益。但这一研究关注的是偏度的均值——也就是截面分布的"中心位置"。一个自然的问题是:如果我们不仅关注偏度的均值,还关注偏度在截面上的离散程度,是否能够获得额外的预测信息?
这正是本文要探讨的核心思路。最新研究发现,公司层面已实现偏度的截面离散度(cross-sectional dispersion in realized skewness)是一个强有力的市场收益预测因子,其预测能力不仅在统计上显著,而且在经济上具有实质性价值。
一、什么是偏度离散度?
1.1 从高频数据到已实现偏度
要构建偏度离散度指标,首先需要理解其底层组件——已实现偏度(realized skewness)。
假设在交易日 ,股票 有 个日内高频收益观测值。在5分钟频率下,每个交易日(美东时间9:30-16:00,共6.5小时)有 个观测值。令 表示股票 在交易日 的第 个日内对数收益。
第一步,计算日已实现方差,即日内高频收益平方和:
第二步,计算经已实现方差标准化后的日已实现偏度:
这个已实现偏度衡量了日收益分布的非对称性:负值意味着收益分布的左尾更厚(股价大幅下跌的概率更高),正值则意味着右尾更厚(股价大幅上涨的概率更高)。
值得注意的是,基于高频数据的已实现偏度与基于日频数据或期权的偏度有本质区别。随着采样频率的提升,已实现偏度主要捕捉的是跳跃成分(jumps)而非连续路径成分。因此,高频已实现偏度反映的是价格跳跃的方向和幅度,而非经典的杠杆效应(leverage effect)。这意味着它包含了与低频偏度不同的信息。
选择5分钟频率是高频金融中的标准做法,这是因为它在估计精度和微观结构噪音之间取得了最佳平衡——更高频率会引入更多的买卖报价弹跳噪音,而更低频率则会损失信息。
1.2 偏度离散度的定义
有了每只股票每天的已实现偏度后,我们关注的核心量是这些偏度值在截面上的离散程度。
定义偏度离散度 为交易日 所有股票已实现偏度估计值的 百分位数和 百分位数之差:
其中 表示截面分布的第 百分位数。
研究中考虑了多种百分位数组合:
-
:四分位距(interquartile range),对异常值较为稳健 -
、、:逐步加宽的范围 -
:最宽的范围,包含更多尾部信息
由于实证分析在月度频率上进行,月度偏度离散度定义为每月最后五个交易日中日度 的均值(或中位数)。使用月末最后一周的数据而非整月数据,既能反映最新信息,又能提供足够的平滑。
1.3 偏度离散度在度量什么?
这个指标的经济含义非常直观:
当偏度离散度较高时,意味着截面上同时存在高正偏度和高负偏度的股票——有些公司面临大幅上涨的跳跃风险,有些则面临大幅下跌的跳跃风险。这反映了公司层面收益非对称性的高度异质性。
当偏度离散度较低时,各公司的偏度值趋于收敛,截面分布更加均匀,反映了一个更加"同质化"的市场环境。
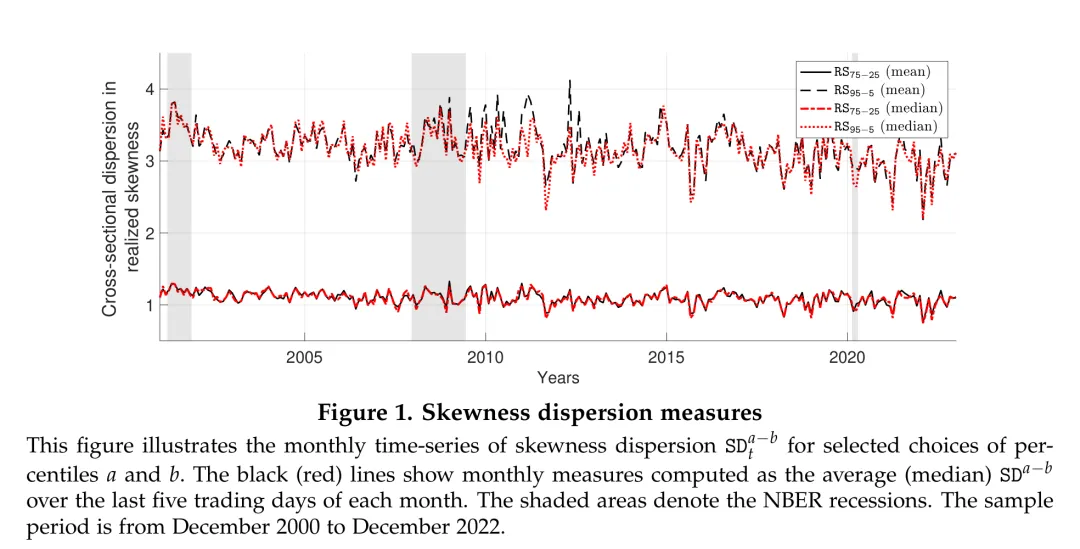 图:不同百分位数定义下偏度离散度的月度时间序列走势。
图:不同百分位数定义下偏度离散度的月度时间序列走势。
从上图可以观察到几个重要特征。首先, 的水平和波动性都高于 ,这是由其覆盖范围更广所决定的。其次,基于均值和中位数的两种月度指标走势高度一致。第三,偏度离散度随时间有明显变化, 约在3附近波动, 则约在1附近。
1.4 数据来源
研究使用的数据覆盖2000年12月至2022年12月,包含纽约证券交易所、美国证券交易所和纳斯达克上市的6,770只美国股票的5分钟高频价格数据。这一数据来源于Kibot,并经过与CRSP数据库的匹配验证。
二、预测能力的实证检验
2.1 单变量预测回归
预测能力的检验基于标准的单变量预测回归:
其中 是未来 个月的平均月度S&P 500对数超额收益, 取1、3、6和12个月。
在预测回归中,统计推断并非直接了当。存在两个经典的统计问题:第一,当预测变量具有持久性(高自相关)时,Stambaugh (1999) 偏误会导致OLS估计量有偏;第二,多期收益的重叠(overlapping observations)会引入序列相关性。
为了稳健地处理这些问题,研究采用了三种推断方法:
第一种方法使用 Newey-West (1986) 调整的标准误,滞后阶数为 ,以修正条件异方差和序列相关性。
第二种方法采用 Martin (2017) 的非重叠观测估计。具体而言,对于 个月的预测期限,分别取第1、、、…个月的非重叠平均超额收益和预测变量进行回归,保存斜率系数、t统计量和调整 。然后换起始点(第2、、、…),重复上述过程。最终对 种选择的结果取平均。
第三种方法使用 Kostakis, Magdalinos, and Stamatogiannis (2015) 提出的IVX估计,该方法通过构造一种工具变量(IVX instrument)来处理预测变量的持久性问题,报告IVX-Wald统计量。
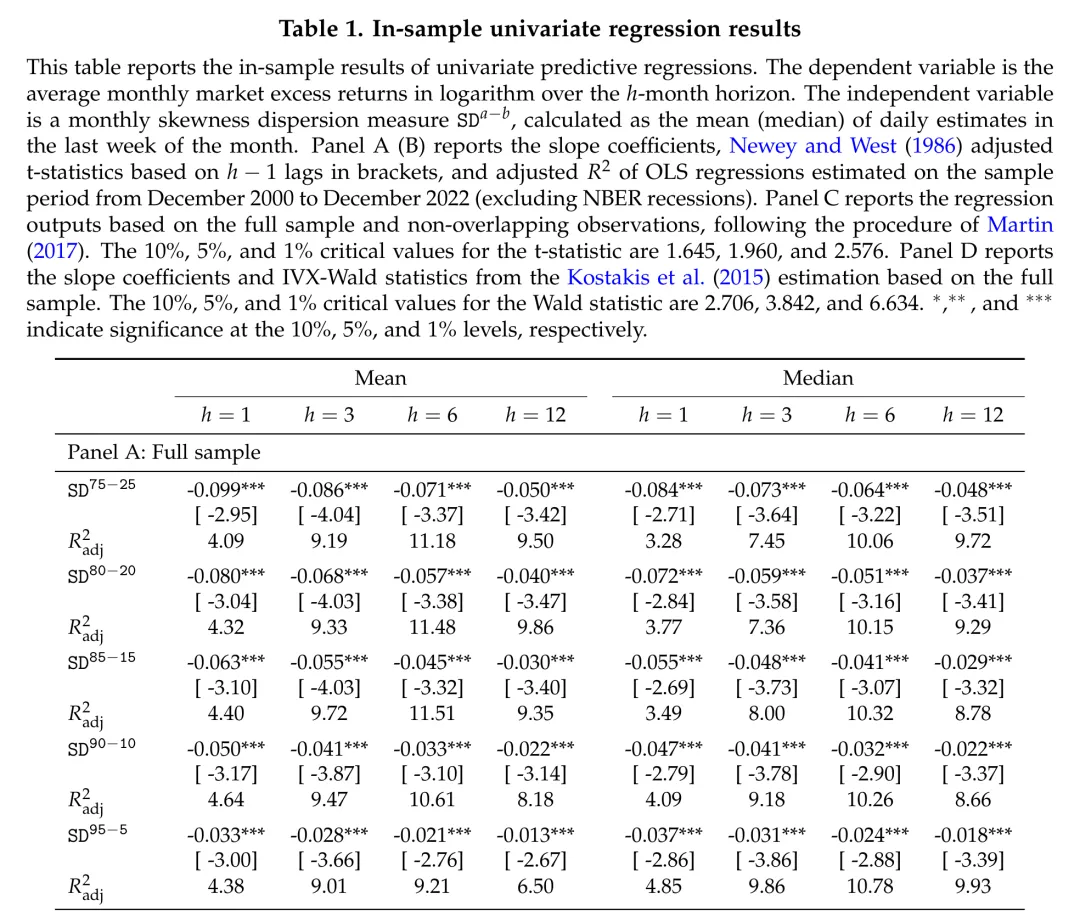
图:单变量预测回归的核心结果——所有偏度离散度指标在所有预测期限上都展现出显著的负向预测能力。
结果清晰而一致:所有 系数均为负值,且在1%置信水平上统计显著。这意味着偏度离散度越高,未来的市场收益越低。
以 (均值版本)为例,1个月预测期限的 (t统计量 = -2.95),调整 。3个月期限的调整 达到9.19%,6个月和12个月期限分别为11.18%和9.50%。对于月度频率的市场收益预测而言,这些 值已经相当可观——在该文献中,大多数已有预测变量的 不到2%。
几个关键发现值得强调:
首先,结果并非由经济衰退期驱动。剔除NBER定义的衰退期后,斜率系数仍然在5%水平上显著,表明偏度离散度的预测能力在正常经济时期同样存在。
其次,使用非重叠观测的估计结果在定性和定量上均高度一致,排除了重叠构造带来的虚假显著性。
第三,IVX估计(Panel D)表明所有百分位数定义和所有预测期限的斜率系数都在1%水平上显著。相比之下,许多已有预测变量在IVX估计下的显著性会随着预测期限的延长而大幅衰减甚至消失。偏度离散度之所以在IVX框架下表现稳健,是因为其自相关性远低于文献中大多数预测变量。
2.2 双变量预测回归:增量预测能力
一个预测变量要具有实际价值,不能只是简单地重复已有变量的信息。为此,研究进行了系统性的双变量预测回归,将偏度离散度与50个已有预测变量逐一配对:
其中 是其中一个控制变量。这些控制变量分为五大类:偏度类、股票截面类、情绪类、方差类、以及其他宏观经济和金融变量。
核心结论是:在控制任何一个已有预测变量后, 的系数仍然保持高度显著——几乎所有情形下都在1%水平上显著,且系数大小与单变量回归非常接近。
反过来,当加入 后,绝大多数已有预测变量变得不再显著。在所有50个控制变量中,只有以下6个在样本内和样本外检验中都保持独立的预测能力:
-
前瞻偏度因子(forward skewness factor, FSF) -
管理层情绪指数(MSI)和投资者注意力指数(AI) -
总隐含波动率价差(IVS) -
共同波动率风险溢价(cvp) -
账面市值比(bm)
一个特别值得注意的发现是:市场偏度和平均公司偏度在加入偏度离散度后变得完全不显著。这说明偏度离散度已经"包含"了来自偏度均值的预测信息,同时还提供了额外的截面维度信息。
2.3 样本外预测检验
样本内预测表现良好并不意味着样本外也能奏效——这是 Welch and Goyal (2008) 的核心批评。为此,研究基于2005年12月至2022年12月的递推窗口(expanding window)进行了严格的样本外检验。
对于每个月 ,使用截至该月的所有历史数据估计预测回归,然后生成 个月后的预测值 。与之对比的基准是历史均值预测 。
样本外 定义为:
其中 和 分别是预测回归和历史均值的均方预测误差。 意味着预测回归优于简单的历史均值。
统计显著性通过 Clark and West (2007) 检验来判定,该检验对嵌套模型比较进行了适当调整。
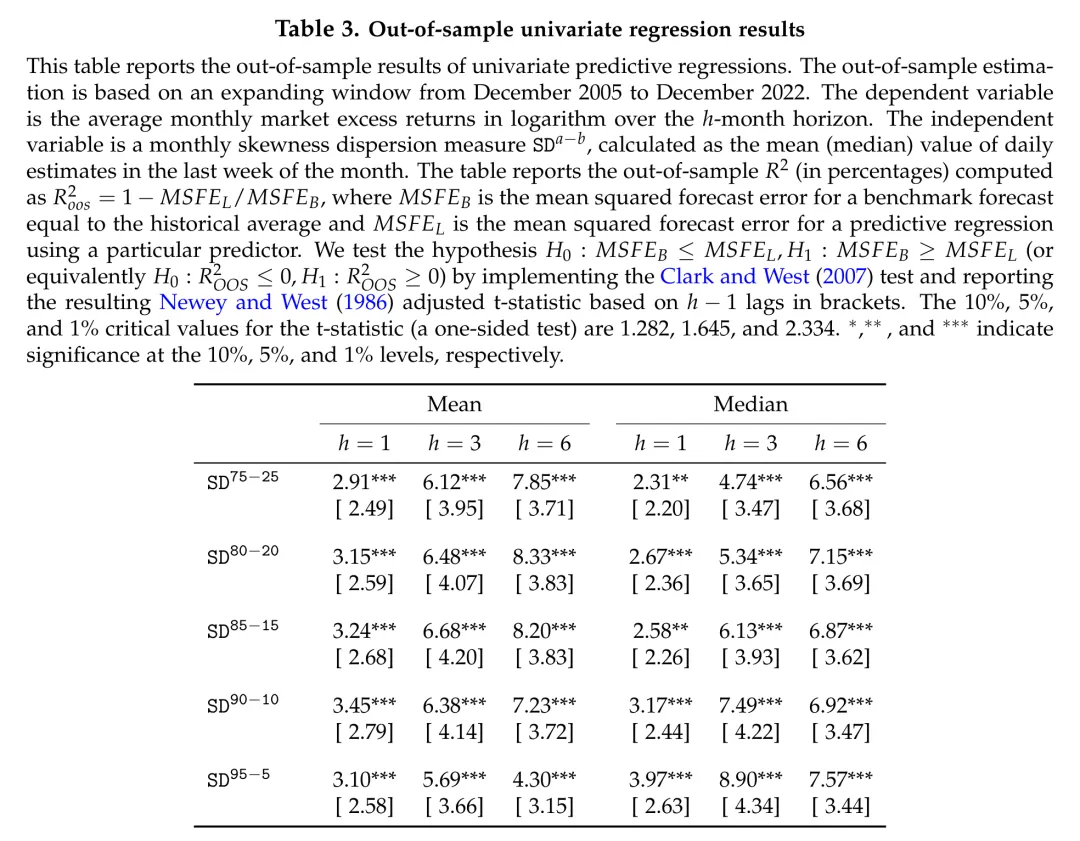 图:样本外单变量回归结果——偏度离散度在所有预测期限上都显著优于历史均值基准。
图:样本外单变量回归结果——偏度离散度在所有预测期限上都显著优于历史均值基准。
结果表明, 在1个月期限上为2.31%-3.97%,3个月期限上为4.74%-8.90%,6个月期限上为4.30%-8.33%。所有检验统计量(仅一个例外)都在1%水平上显著。
在文献中,这是非常优异的样本外表现。正如 Goyal, Welch, and Zafirov (2024) 对大量预测变量的最新评估所示,绝大多数已有变量的样本外 为负值,即无法跑赢历史均值。
一个有趣的细节是:使用中位数而非均值构建的月度偏度离散度,在样本外往往表现更好。这是因为中位数对极端异常值的敏感度更低,提供了更准确的离散度估计。
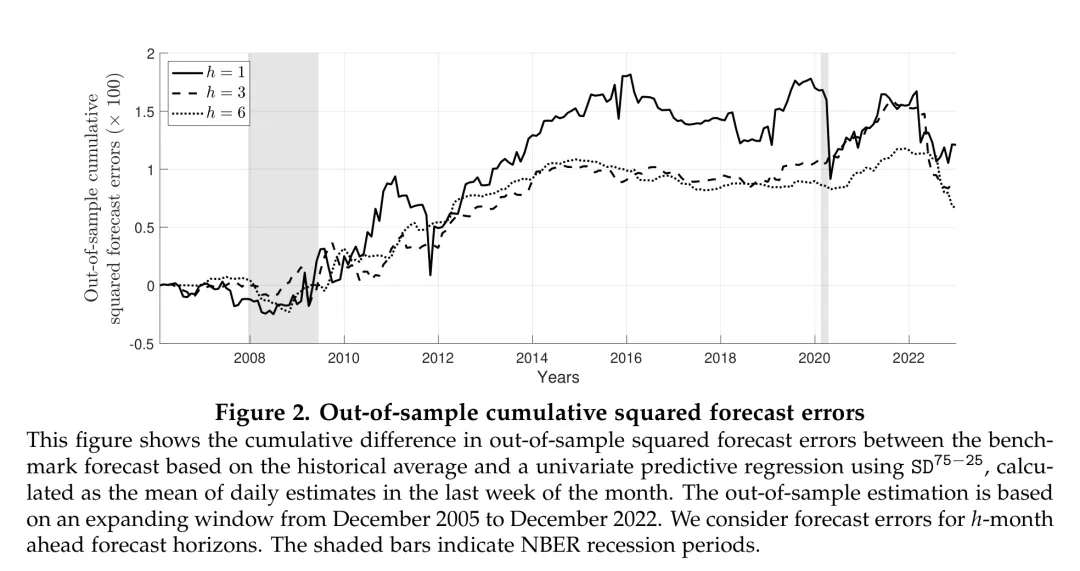 图:样本外预测中偏度离散度相对于历史均值基准的累积预测误差优势随时间持续增长。
图:样本外预测中偏度离散度相对于历史均值基准的累积预测误差优势随时间持续增长。
上图展示了历史均值预测和偏度离散度预测之间累积平方预测误差的差值。正值意味着偏度离散度模型表现更好。可以看到,除了2011年底、新冠疫情期间和2022年的短暂下降外,偏度离散度在整个样本外期间持续优于历史均值——其优势并非由个别极端事件驱动。
2.4 预测包含检验
为了更直接地比较偏度离散度与已有变量的信息含量,研究进行了预测包含检验(forecast encompassing test)。具体来说,构造两个单变量预测(分别基于 和控制变量 )的凸组合:
的值衡量了偏度离散度预测在最优组合中的贡献。如果 ,则偏度离散度不包含任何增量信息;如果 ,则偏度离散度完全包含了对照变量的信息。
检验结果表明:在几乎所有控制变量-期限组合中, 在10%水平上显著为正,且绝大多数情况下 。这意味着最优组合预测主要由偏度离散度的信息驱动。唯一的例外是注意力指数(AI),在该情况下 虽然显著但略低于0.5,说明注意力指数包含了一些偏度离散度所没有的独立信息。
三、经济价值:资产配置
统计显著性固然重要,但投资者更关心的是:这些预测能力能否转化为实际的投资收益?
3.1 投资框架
考虑一个均值-方差投资者,在股票市场和无风险资产之间进行配置。给定 个月的投资期限,投资者在每期末将其财富的 比例分配给股票市场:
其中 是相对风险厌恶系数(设为3), 是基于预测模型的收益预测, 是收益方差的预测(使用已实现波动率代理)。权重被限制在 区间以确保合理。
投资者的确定性等价收益(Certainty Equivalent Return, CER)为:
其中 和 分别是投资组合的均值和方差。CER增益定义为基于预测回归的投资者相对于使用历史均值的投资者的年化CER差异。这个增益可以理解为投资者为获得预测回归信号所愿意支付的最大费用。
3.2 经济收益
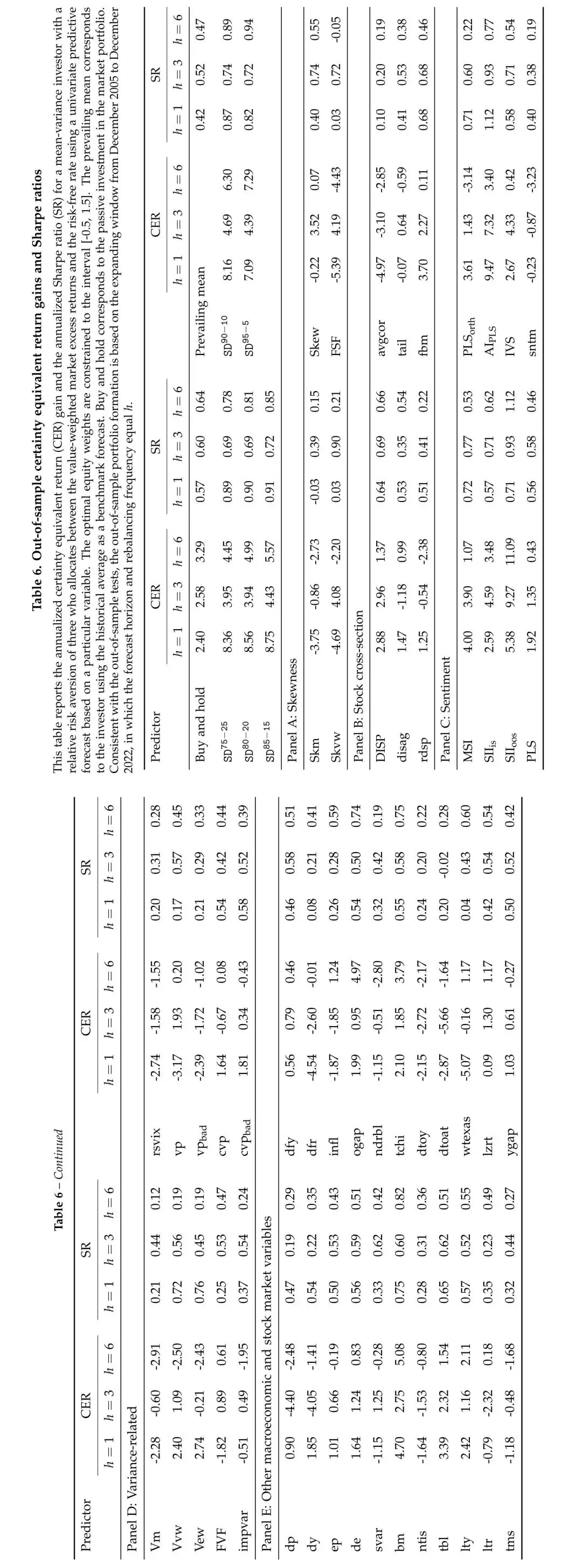 图:偏度离散度在CER增益和夏普比率方面的突出表现,以及与其他50个预测变量的对比。
图:偏度离散度在CER增益和夏普比率方面的突出表现,以及与其他50个预测变量的对比。
在1个月的投资期限上,基于偏度离散度的投资策略带来了709至875个基点的CER增益。相比之下,买入持有策略的CER仅为240个基点,而历史均值策略仅为0.42个百分点。这是一个巨大的经济差异。
在夏普比率方面,偏度离散度策略在1个月期限上达到0.82至0.91,显著优于买入持有的0.57和历史均值的约0.42-0.52。
与其他50个预测变量相比,只有注意力指数(AI,CER增益947个基点)在1个月期限上表现更好。在更长的3个月和6个月期限上,偏度离散度仍然保持在最优预测变量的前列。
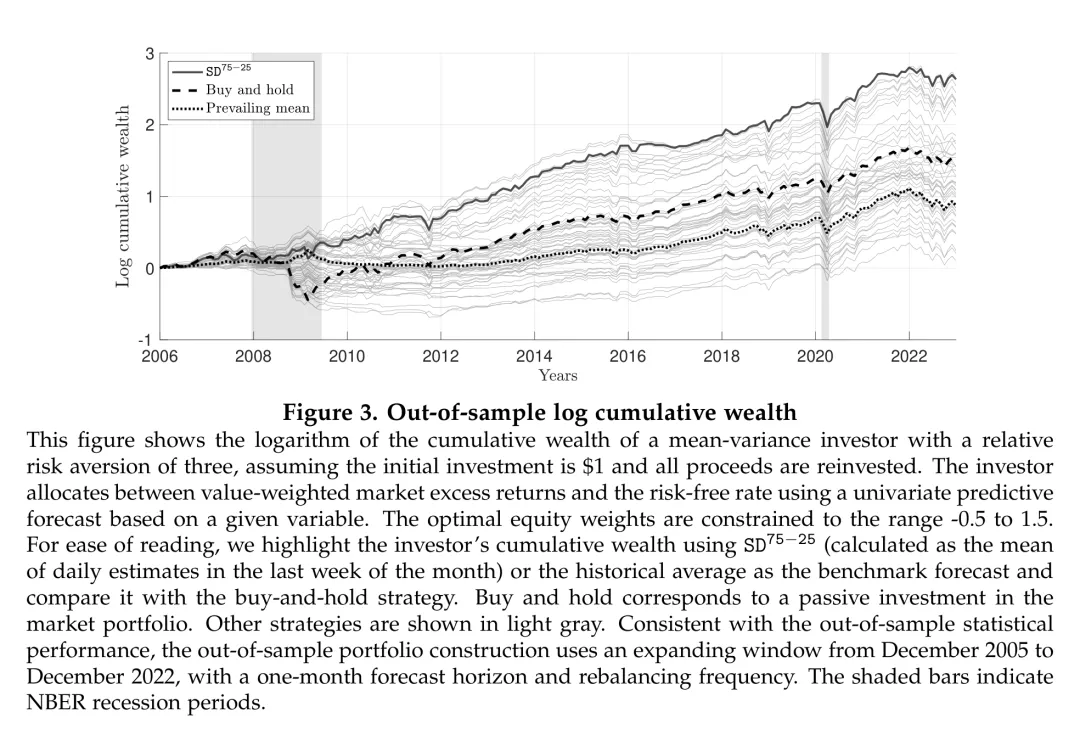 图:基于偏度离散度的投资组合在整个样本外期间的累积对数财富显著优于买入持有和其他大多数策略。
图:基于偏度离散度的投资组合在整个样本外期间的累积对数财富显著优于买入持有和其他大多数策略。
上图展示了各种策略的对数累积财富。可以看到, 策略在全球金融危机后便开始持续超越大多数基准策略,到样本末期积累了显著更高的累积财富。
四、经济机制:偏度离散度预测了什么?
预测能力的存在引发了一个更深层的问题:偏度离散度为什么能预测市场收益?
4.1 风险渠道
如果偏度离散度反映的是时变风险溢价,那么高偏度离散度应对应"好时期"(投资者要求的预期收益较低),并伴随着较低的风险度量。
实证证据支持这一假设。偏度离散度与期权隐含方差(impvar, rsvix)和方差风险溢价(vp, vpbad)呈显著负相关,与市场已实现方差也呈负相关。此外,它与平均股票收益相关性(avgcor)呈显著负相关。Pollet and Wilson (2010) 曾论证,在其他条件不变时,总体风险上升会导致股票间共同运动加强(相关性上升)。因此,偏度离散度与平均相关性的负关联意味着:高偏度离散度对应低总体风险,这与风险溢价下降(未来收益更低)的预测方向一致。
4.2 行为渠道
在行为金融的框架下,高偏度离散度应与高投资者情绪相关——乐观情绪推高当前价格,导致未来收益降低。
偏度离散度确实与两个投资者情绪指数(PLS和PLSorth)以及注意力指数(AI)呈正相关。但最强的关联来自AAII(美国个人投资者协会)的调查数据:偏度离散度与看涨情绪的相关系数为0.30,与看跌情绪的相关系数为-0.28,均在1%水平上显著。
这一发现表明,偏度离散度所捕捉的行为成分主要反映的是投资者对市场方向的直接预期(如AAII调查所度量的),而非Baker and Wurgler (2006) 构建的综合情绪指数中的间接成分。
一个有意思的发现是,偏度离散度与分歧度量(disagreement measures)之间没有显著关联,但与总卖空量(aggregate short interest)呈高度正相关。卖空头寸通常反映了相对成熟投资者的前瞻性预期,这为理解偏度离散度的信息来源提供了重要线索。
4.3 投资者情绪状态下的预测能力差异
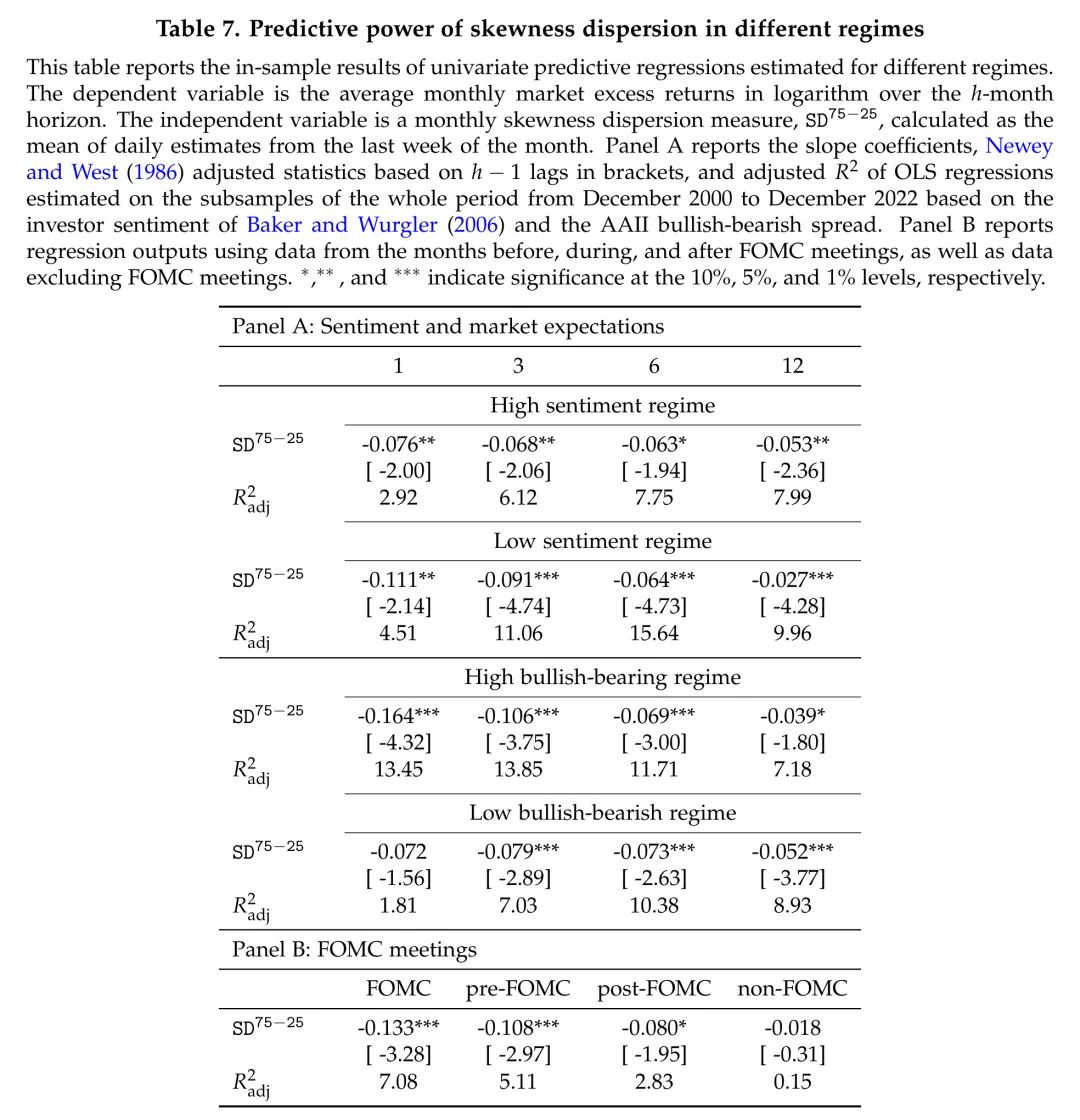 表:偏度离散度在不同投资者情绪状态和FOMC会议时期的预测能力差异。
表:偏度离散度在不同投资者情绪状态和FOMC会议时期的预测能力差异。
研究将样本按照情绪高/低两种状态划分,分别估计预测回归。有趣的是,结果出现了表面上矛盾的模式:
按照 Baker-Wurgler 情绪指数划分,偏度离散度在低情绪状态下预测能力更强(,3个月期限)。
但按照AAII看涨-看跌价差划分,偏度离散度在投资者更乐观时预测能力更强(1个月期限的 ,t统计量 = -4.32,)。
关键的是,预测能力在两种状态下都存在,只是强度不同。这排除了单纯的定价偏误(mispricing)解释——如果仅仅是行为偏差驱动的,预测能力应该在某个状态下完全消失。
4.4 FOMC公告:信息驱动的预测能力
这是整篇文章最具洞察力的发现之一。
研究者将样本划分为四组:FOMC会议所在月、会议前一个月、会议后一个月、以及无FOMC活动的月份,分别估计1个月预测回归。
结果极为显著:
-
在FOMC会议月份, 的系数为 (t统计量 = -3.28),调整 。
-
在FOMC会议前一个月,系数为 (t统计量 = -2.97),。
-
在FOMC会议后一个月,系数为 (t统计量 = -1.95),。
-
而在非FOMC月份,预测关系几乎完全消失:系数仅为 (t统计量 = -0.31), 接近零。
这些结果勾勒出一个清晰的信息传导机制:
-
第一阶段(会前):投资者(尤其是成熟投资者)在货币政策公告前根据各自的信息和预期进行布局。这些异质性预期反映在偏度离散度的升高中。偏度离散度已经包含了关于未来收益的信息,但价格尚未完全反映。
-
第二阶段(会中):FOMC公告释放了关键的宏观信息,投资者迅速处理并将其纳入价格。高偏度离散度所预示的低收益得以实现。预测能力在此时最强。
-
第三阶段(会后):信息基本被消化,预测能力迅速衰减。
这一发现支持了偏度离散度的"双重性质"——它既反映了总体风险的变化(风险渠道),也反映了信息驱动的估值调整和定价偏差的修正(行为渠道),而这两者都在重要宏观公告前后集中体现。
五、峰度离散度:来自四阶矩的额外证据
已实现偏度度量的是收益分布的非对称性。一个自然的问题是:如果我们考虑第四阶矩——峰度(kurtosis),度量的是分布的尾部厚度(tail heaviness),其截面离散度是否也具有预测能力?
研究者按照相同方法构建了峰度离散度 ,并复制了全套的样本内和样本外检验。
结果表明,峰度离散度同样展现出与市场收益的显著负向关系。在1个月预测期限上,峰度离散度的 约为4%-6%,与偏度离散度相当甚至略高。
然而,在更长的预测期限上,峰度离散度的解释力明显弱于偏度离散度—— 差距达到至少两个百分点。此外,使用更宽的百分位数范围来计算峰度离散度会进一步削弱结果,因为峰度对异常值比偏度更敏感,极端峰度值往往是噪音。
这一对比分析告诉我们:收益分布的非对称性(偏度)比整体尾部风险(峰度)在预测市场收益方面提供了更持久和更可靠的信息。
六、方法论总结与启示
6.1 预测变量构建的要点
偏度离散度的构建有几个重要的方法论优势:
-
数据需求简单——它仅依赖于股票收益数据,不需要期权数据、分析师预测或宏观经济变量。这意味着它可以以更高的频率和更广的覆盖面来计算。
-
对异常值的处理——使用百分位数范围而非标准差来度量离散度,天然地减轻了极端值的影响。进一步地,使用月末最后一周的均值(或中位数)进行月度平滑,也降低了单日估计的噪音。
-
低持久性——与许多传统预测变量(如股息率、账面市值比)不同,偏度离散度的自相关性较低。这使得它在IVX等控制持久性的稳健推断方法下仍然保持显著,避免了Stambaugh偏误的困扰。
6.2 与已有预测变量的关系
在50个已有预测变量中,偏度离散度最强的截面相关性来自总卖空量(aggregate short interest)。这并非巧合:当截面上偏度差异扩大时,成熟投资者倾向于做空那些正偏度过高(被投机者追逐)的股票。
令人惊讶的是,偏度离散度与分歧度量(disagreement)、离散度度量(return dispersion)和尾部风险代理(tail risk)之间的相关性不显著。这表明它捕捉的是一种与已有文献中的信息异质性度量不同的横截面变异来源。
6.3 对量化策略开发的启示
对于量化研究员和交易策略开发者,这项研究有以下实践启示:
信号构建层面,偏度离散度可以作为市场择时信号,与现有的基于波动率、情绪或宏观的择时模型互补。考虑到它在FOMC月份的预测能力最强,一种可能的增强策略是根据FOMC日程对信号进行加权。
组合构建层面, 的均值和中位数两种版本的差异值得关注——中位数版本在样本外通常表现更好,可能是更优的选择。
风险管理层面,高偏度离散度意味着市场中存在大量不对称风险暴露。资产管理者可以将其作为减仓或加强对冲的信号。
七、结论
本文介绍了一个新颖的股票市场收益预测指标——偏度离散度,它度量的是高频已实现偏度在股票截面上的四分位距。核心发现可以概括为:
偏度离散度与未来1至12个月的市场超额收益呈显著负向关系。该预测能力在多种统计推断方法下稳健,不受经济衰退期驱动,在严格的样本外检验中显著优于历史均值基准。
在50个已有预测变量中,偏度离散度的预测能力不被任何单一变量所解释。相反,加入偏度离散度后,绝大多数已有变量失去了独立的预测能力。
基于偏度离散度的投资策略产生了709至875个基点的年化CER增益和0.82至0.91的夏普比率,在几乎所有备选策略中名列前茅。
偏度离散度的预测能力集中在FOMC会议所在月份,在非FOMC月份几乎不存在——这指向了一种信息驱动的预测机制,结合了风险重定价和估值偏差修正两个渠道。
对于量化研究者和从业者而言,偏度离散度提供了一个构建简洁、经济含义清晰、且在样本内外均表现稳健的市场收益预测工具。它的信息来源——公司层面收益非对称性的截面异质性——提醒我们,除了通常关注的一阶矩(均值)和二阶矩(方差)之外,高阶矩的截面分布形态也蕴含着丰富的市场信息。
参考文献
Babiak, M., Baruník, J., & Kurka, J. (2026). Skewness dispersion and stock market returns. arXiv preprint, arXiv:2604.07870v1.

评论