天津大学计算机科学与技术学院自然语言处理实验室系列研究成果获ACL 2026收录

近日,第64届国际计算语言学大会(ACL 2026)公布论文录用结果。天津大学自然语言处理实验室(TJUNLP)熊德意教授团队共有16篇论文入选,其中9篇入选Main Conference,7篇入选Findings。ACL是计算语言学与自然语言处理领域重要国际学术会议,也是CCF推荐A类会议。此次入选体现了团队在大语言模型基础研究、关键技术与交叉应用方面的持续积累,研究覆盖推理与强化学习、可解释性与模型安全、多语言大模型与机器翻译、价值对齐与科研智能体等方向。
推理大模型与强化学习
实验室围绕后训练泛化、熵调控与高效推理开展研究,揭示强化学习后训练优于监督微调的机制,分析RLVR训练中的熵坍缩规律并提出调控方法,同时提出基于推理向量的高效推理框架,在保持准确率的同时显著缩短推理长度。
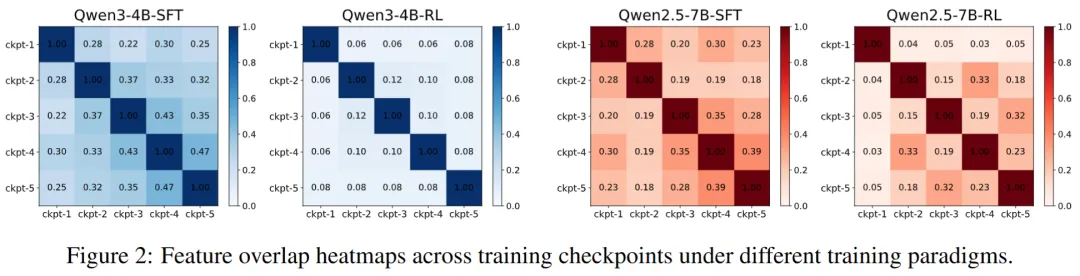
不同训练范式下模型特征重叠情况的对比热力图
可解释性与模型安全
实验室提出可解释性引导的数据选择框架,通过识别具有因果效用的内部任务特征提升数据筛选与微调效率;同时面向对抗攻击与越狱风险,提出靶向神经元精细化调优方法,在增强安全鲁棒性的同时保持模型通用能力。
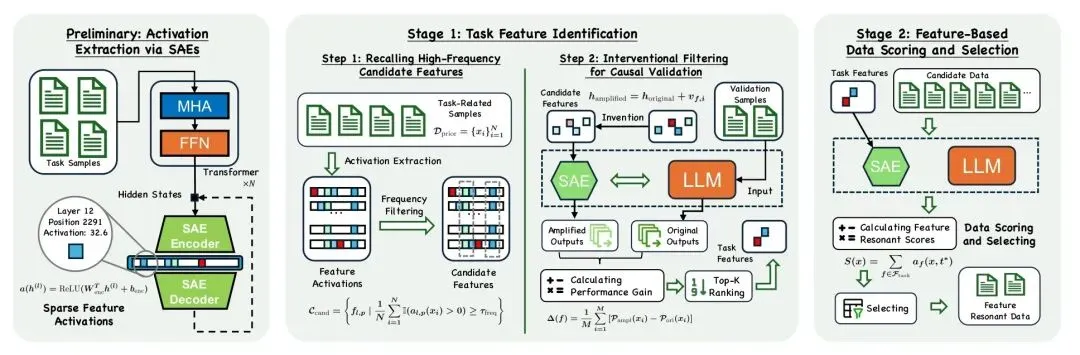
可解释性引导的数据选择框架图
多语言大模型与机器翻译
实验室聚焦低资源语言建模、文档级翻译一致性和MoE架构的跨语言迁移与高效部署,构建高质量大规模藏语语料并推进Dense与MoE模型持续预训练;提出文档级翻译动态参数内化框架,并在跨文化实体翻译、跨语言语义锚定路由对齐和专家神经元结构化剪枝等方面取得进展。
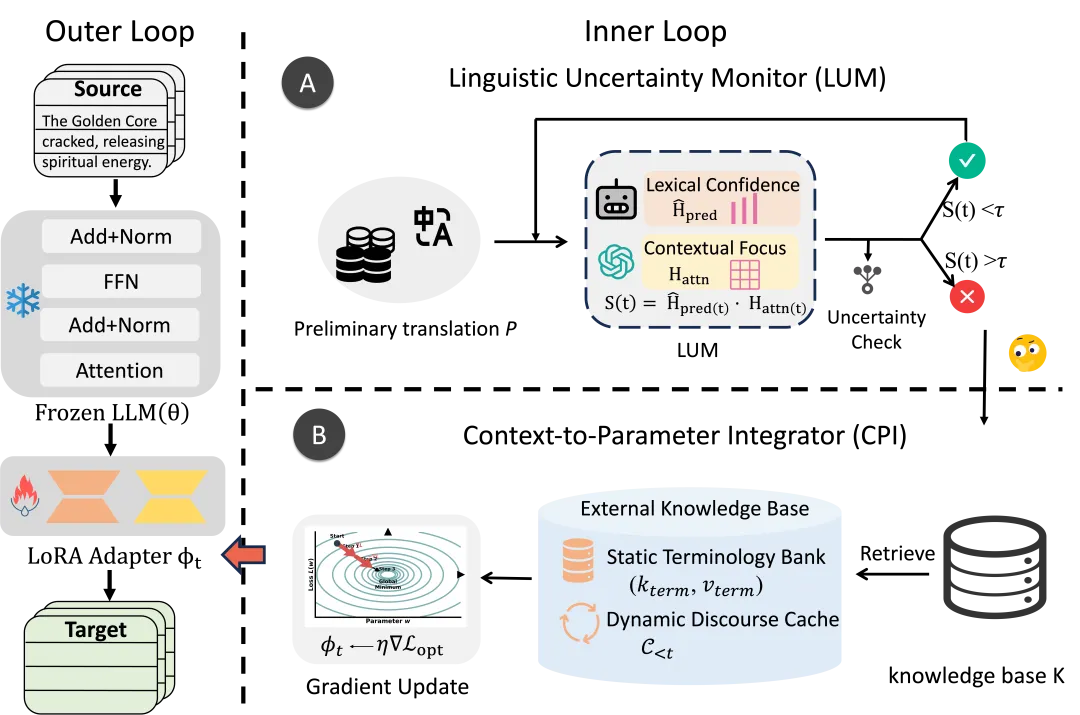
文档级翻译动态参数内化框架图
价值对齐、社会模拟与科研智能体
实验室围绕价值建模、结构评测与科研智能体形成连续研究链条,提出基于人口统计学映射的细粒度多元价值观对齐框架、面向价值结构的对称式评测方法和社会学专家驱动的个体价值模拟框架,并探索面向科学发现和社会科学研究的多智能体系统;同时构建高质量英文应用隐私政策总结与解释语料库。
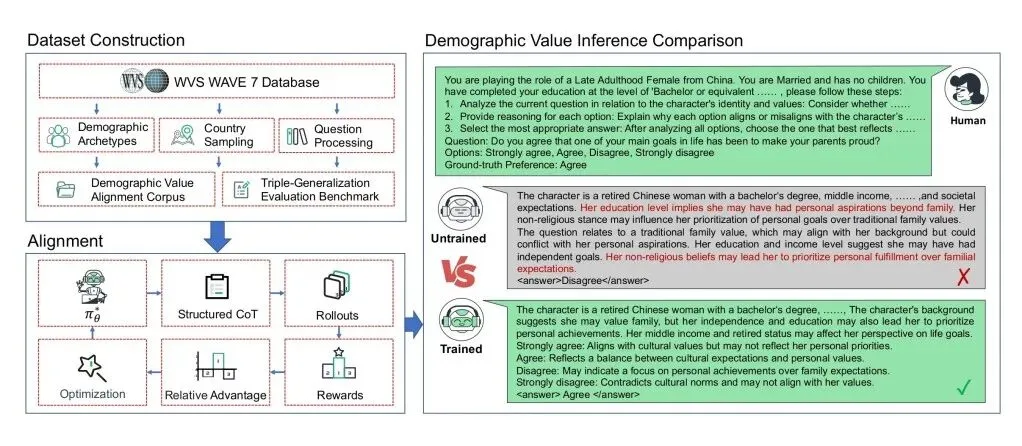
基于人口统计学映射的细粒度多元价值观对齐框架图
未来,实验室将继续面向国家在人工智能、数字中国、教育强国和科技强国建设中的重大需求,立足多语种智能信息处理、可信人工智能与科研智能化等战略方向,推动基础理论突破与关键核心技术攻关,主动服务国家重大战略实施,为实现高水平科技自立自强贡献智慧和力量。
★
图文 |
编辑 |
初审 |
审核 |
审核发布 |
任玉琪 郑景婷
冯稚瑾
薛文晞
孙 媛
冯 伟
