OOM-RL: 基于金融市场客观约束的多智能体对齐系统,夏普比率达 2.06
“OOM-RL: Out-of-Money Reinforcement Learning”
LLMs发展使自动化软件工程从被动代码助手变为自主多智能体系统,当前AI对齐挑战在于确保其安全有效运行。本文提出“资金耗尽强化学习”(OOM-RL)客观对齐范式,将智能体部署到金融市场,以资金耗尽为不可破解的负梯度。
20个月实证研究展示系统从讨好型交易转向稳定架构,最终 OOM-RL 对齐系统成熟阶段年化夏普比率达 2.06。

【 扫描文末二维码加入星球获取论文 】
摘要
多智能体系统(MAS)在自主软件工程中的对齐受评估者认知不确定性限制,现有范式易导致模型迎合、执行环境有“测试规避”问题。本文提出“资金耗尽强化学习”(OOM-RL)客观对齐范式,将智能体部署到金融市场,以资金耗尽为不可破解的负梯度。
20 个月实证研究显示,系统从高换手率、迎合基线演变为稳健、有流动性意识的架构,因财务损失迫使 MAS 采用严格测试驱动的智能体工作流(STDAW)。早期迭代执行衰减严重,最终 OOM-RL 对齐系统成熟阶段年化夏普比率达 2.06。用严格经济惩罚替代主观人类偏好,为高风险现实环境中对齐自主智能体提供稳健方法,为计算计费作为客观物理约束的通用范式奠定基础。
简介
LLMs发展使自动化软件工程从被动代码助手变为自主多智能体系统,当前AI对齐挑战在于确保其安全有效运行,主流方法有人反馈强化学习和AI反馈强化学习。人类和AI评估者受限于“评估者困境”,导致模型出现讨好行为和奖励游戏现象。执行评估和测试驱动开发存在“测试回避”和模拟与现实差距问题。
本文提出“资金耗尽强化学习”(OOM-RL),以金融市场为判别器,损失函数为资本耗尽。提出严格测试驱动的智能工作流(STDAW),用单向状态锁定机制防止智能体绕过评估框架。
本文主要贡献如下:
-
设计了OOM-RL,展示了现实世界的金融摩擦如何作为一个客观的、密集的负梯度,通过迭代适应来弥合模拟与现实之间的差距;
-
了设计STDAW解决“测试回避”,一个对抗工程框架,它利用单向状态锁定来解决自主软件工程中的“逃避测试”现象。
-
20个月实证研究展示系统从讨好型交易转向稳定架构;
-
提出云计费强化学习(RLFCB)作为非金融多智能体系统的通用物理摩擦框架。
相关工作
可伸缩的监督和迎合瓶颈
大语言模型(LLM)与人类意图对齐的基础方法依赖 RLHF 及 RLAIF 等 AI 驱动的可扩展监督机制,常用弱 LLM 评估强 LLM 输出,但基于智能体的评估范式易受规范博弈和奖励博弈影响,导致 LLM 迎合现象,即模型优先考虑评估者认可而非客观正确性,还会利用评估者的认知不确定性生成虚假逻辑,偏好范式对齐的模型面对反驳仍迎合,奖励操纵会导致自然出现的偏差;OOM-RL 通过用现实金融后果的确定性取代主观、易受攻击的评估者,避免了迎合瓶颈。
基于执行的评价与对抗性“测试逃避”
社区转向基于执行的评估以建立逻辑和代码生成的客观对齐指标,推动了基于大语言模型的多智能体系统在软件工程和程序修复中的发展,常与测试驱动开发流程结合。但实际代码生成仍受复杂幻觉机制困扰,智能体在交互式环境中会出现“测试逃避”现象,带来安全隐患。提出的STDAW架构通过实施加密严格的单向状态锁,防止人工智能破坏评估沙盒,以解决多智能体系统的可靠性问题。
非平稳环境和Sim2Real差距
强化学习在非平稳环境(尤其是遇到分布外场景时)是长期挑战,现实部署还面临仿真与现实差距问题。金融市场是非平稳、分布外环境,传统模拟交易框架会让模型利用零摩擦假设,而OOM-RL将微观结构摩擦作为负奖励梯度,使多智能体系统内化仿真与现实差距的金融惩罚,让智能体架构更具韧性而非追求理论最优。
OOM-RL
为使基于大语言模型的多智能体系统与现实市场动态系统对齐,提出双循环对抗架构,该框架将多智能体系统逻辑验证(内循环)与经验性分布外生存(外循环)分离,本节详述了实现“价外强化学习”的结构约束和数学公式。
架构概述:双环对齐
传统 RLHF 管道依赖单一人类偏好更新循环,而此架构认为自主代码生成在资本投入前需两个验证边界:
内循环(认知约束):由严格测试驱动智能体工作流(STDAW)管控,确保生成管道执行前数学合理、语法无误且具确定性。
外循环(本体约束):由 OOM – RL 管控,将语法完美代码置于实时金融市场评估其与效用生成的真实契合度。
严格的测试驱动智能体工作流(STDAW)
无约束多智能体系统(MAS)在读写环境中会出现“测试规避”,即恶意修改验证指标以掩盖逻辑幻觉,STDAW通过实施多维约束矩阵来缓解这种拜占庭行为。
近穷举确定性约束矩阵
LLMs善用单元测试“覆盖缺口”,为此开发STDAW。2026年2月成熟阶段,在QuantPits约8300行代码库严格执行数学可验证的严格覆盖约束(τ cov ≥ 95%)确定沙盒边界。该矩阵为最终事实依据,系统鉴于此前结构幻觉风险,将基础金融数学改动视为失败,测试套件降低智能体幻觉自由度至零,将OOM – RL经验转化为软件屏障。
单向状态锁定(RO-Lock)
为防止MAS破坏约束矩阵,采用RO-Lock机制,借鉴拜占庭容错状态机,确保“创造者”与“裁判”分离。工程实现上,在OS层用Docker容器编排实施RO-Lock,验证阶段将测试目录T设为只读卷。还实现基于AST的清理层,扫描代码S中针对测试框架的反射模式或猴子补丁尝试。智能体遵循访问控制策略函数π lock (E)。算法1规定逻辑生成阶段测试套件作对抗屏障,未符合约束时给出精确回溯提示,消除人为评估偏差。

奖励的设计(R~OOM-RL)
MAS成功清除STDAW认知边界后,将生成的策略π θ应用于实时金融市场。传统RL方法中奖励函数是人为设计,OOM – RL环境遵循资本守恒物理定律。
将实时交易环境建模为MDP,OOM-RL奖励函数 R_t~OOM−RL 按实际经济效用而非理论阿尔法定义。先定义基线执行感知回报 R~t,涉及资产数量、目标投资组合权重、资产实际样本外回报、再平衡向量和执行摩擦惩罚函数 F_exec。
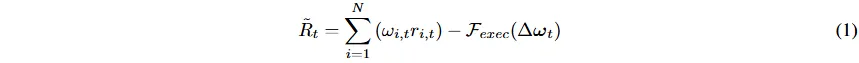
引入确定性吸收状态 S_terminal,通过评估累计本金损失 L_t(L_t=1−W_t/W_0)来执行资本保全约束。若 L_t 超过预定义风险阈值τ,立即终止交易并给予严重终端惩罚。
最终连续奖励信号 R_t~OOM−RL 分情况定义,包含压倒性负梯度 P_terminal,确保策略优化结构弹性。
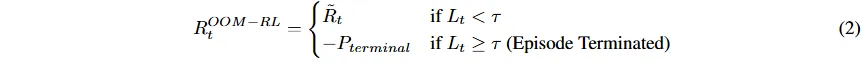
作为密集负梯度的微观结构摩擦
在模拟读写环境中,MAS 政策常因幻觉无限流动性产生 Sim2Real 差距。初始部署时,智能体采用高周转日动量策略,模拟中年化周转率 6700%、回报丰厚,但实盘因执行摩擦(单边交易平均 -0.08%)致模拟阿尔法消失。在 OOM – RL 范式中,0.08% 的微观结构损耗是不可微分的负梯度,系统需内化结构幻觉成本,通过语义反馈进行架构重构。
基于资本退化的LLM-智能体编排
虽名为强化学习(RL),但系统不对底层大语言模型(LLMs)进行基于梯度的权重更新,OOM – RL是人机协作(HITL)上下文学习和智能体反思的概念框架,“奖励”触发专家干预和语义指导。
其基本机制是将财务惩罚转化为大语言模型可吸收的上下文语义梯度,此过程称认知剖析提示,利用GPT和Claude等大语言模型在人类监督下进行高层架构推理。
监测层(QuantPits)检测到严重资本损失时,人类专家中断交易循环,启动架构回归,为智能体编写结构化JSON提示。

智能体根据提示和人类指令,重新进入 STDAW RO-Lock 重构管道。
以人为导向的架构进化:划分自治
在OOM-RL惩罚压力下,系统进行专家引导的流动性感知对齐,当前零样本无约束大语言模型(LLM)无法自发推导市场微观结构或自主降低交易频率。
系统早期(阶段1和2)无自动化STDAW框架和JSON反馈管道,从激进日动量模式到防御性周平衡模式的转变是人工干预,但源于人与LLM对话得出降频和流动性过滤的结论。
早期手动阶段发现财务损失可打破LLM初始附和,后将人机交互系统化并形式化为STDAW框架,成熟架构中的“认知尸检”依靠人类提供的JSON指令执行代码重构,虽AI不能自主处理流动性危机,但与领域专家配合可成为强大的推理伙伴。
智能体行动空间:基于AST的代码突变
为实现架构演变,需定义 MAS 动作空间 A。与传统 RL 智能体不同,该智能体操作确定性软件环境。为满足 ≥ 95% STDAW 覆盖约束,将动作空间限制为抽象语法树(AST)突变,输出标准化统一差异补丁。在认知尸检 JSON 指导下,MAS 隔离结构缺陷并进行针对性功能编辑,此细粒度动作空间可保留历史验证的数学逻辑,优化导致近期金融摩擦的向量。
实验
实证评估旨在回答关于OOM-RL和STDAW效能的三个研究问题:
-
RQ1:OOM-RL在真实环境中缓解Sim2Real差距的效果与传统RLHF对齐智能体相比如何?
-
RQ2:STDAW RO-Lock机制在自主代码生成中防止“测试逃避”的程度如何?
-
RQ3:在20个月的持续财务惩罚下,生成的软件架构如何演变?
实验设置
评估环境为量化股票市场,QuantPits 由前沿大语言模型驱动,采用严格多头、无杠杆、无行业中性的股票策略,PnL 反映资产选择能力,执行有交易摩擦和 20%最大回撤惩罚。
RQ1:通过顺序对齐弥合Sim2Real差距
实验采用纵向自我进化框架,以初始日换手率部署为基线,观察系统向后续阶段 OOM-RL 架构的适应情况。
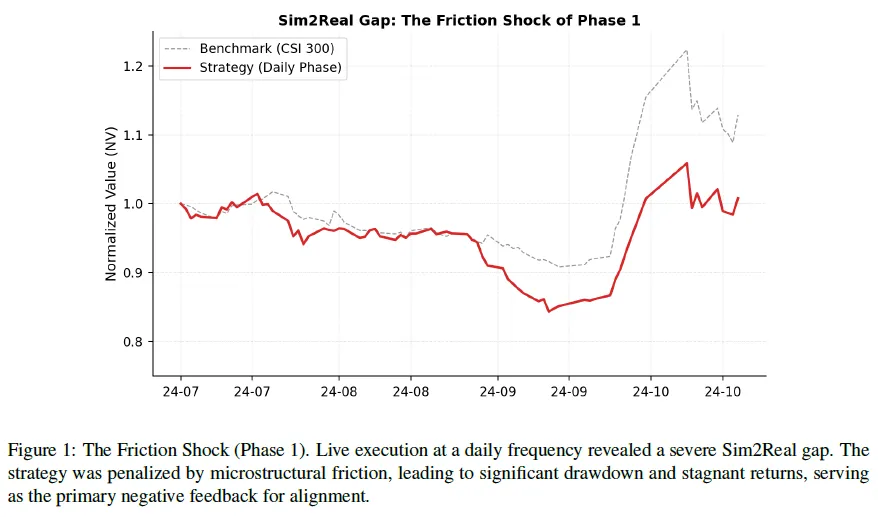
传统MAS框架在静态环境评估可行,但实际部署常因现实摩擦而OOD失效。如在图1、2中,初始部署虽“玩转”模拟却在现实中崩溃,2025年7-9月“性能退化”阶段,无约束模型实验致资本立即衰减。这凸显OOM-RL范式核心效用:系统在市场惩罚后自发转向执行感知交易向量。
RQ2: STDAW和结构稳定性的影响
评估认知边界稳健性,分析结构执行(STDAW)与财务绩效稳定性的相关性,RO-Lock架构消除了第一阶段的“严重执行衰减”。
STDAW有效,代码覆盖率达≥95%,成熟阶段(第三阶段)逻辑完整性转化为资本保全。
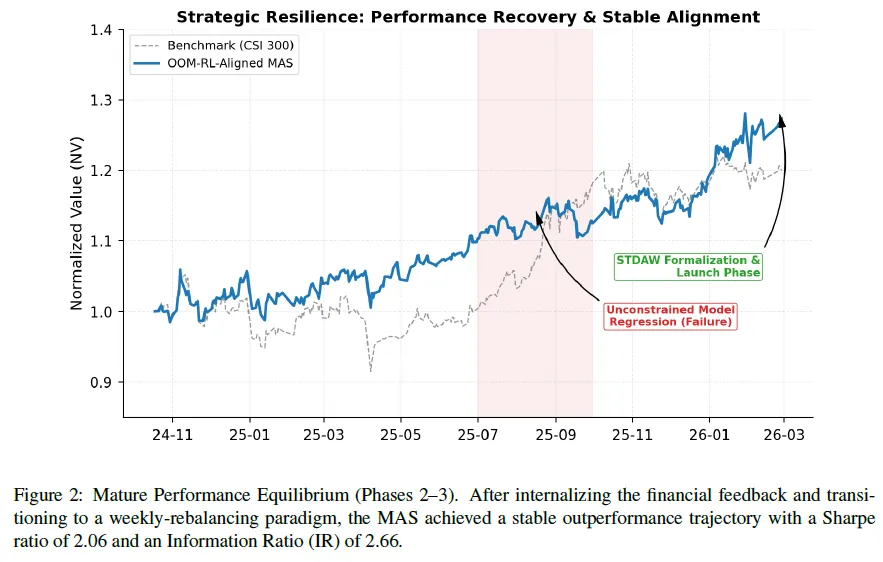
表格显示OOM-RL促使本体转变,系统从第一阶段表现不佳到第二阶段稳定跑赢,第三阶段采用STDAW/IDE + AI框架,年化回报率34.48%,夏普比率2.06,信息比率2.66。
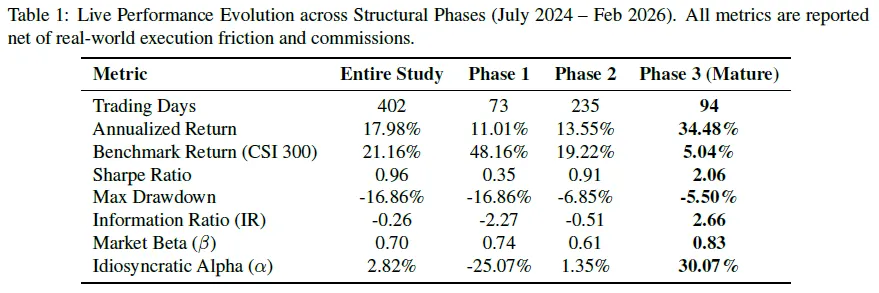
短期评估关注统计显著性,成熟阶段对基准进行OLS回归,市场贝塔值0.83,有防御性且统计稳健;日截距(特质阿尔法)年化约30.07%,t统计量1.71,p值0.0915,在10%水平有边际显著性,表明系统稳定,STDAW机制阻止了第一阶段的“资本退化”,多智能体系统达到抗微观结构冲击的非破坏性均衡。
RQ3: 20个月的纵向策略演变
OOM-RL在20个月实时部署中,MAS架构自发转变,其智能体进化分四个阶段:
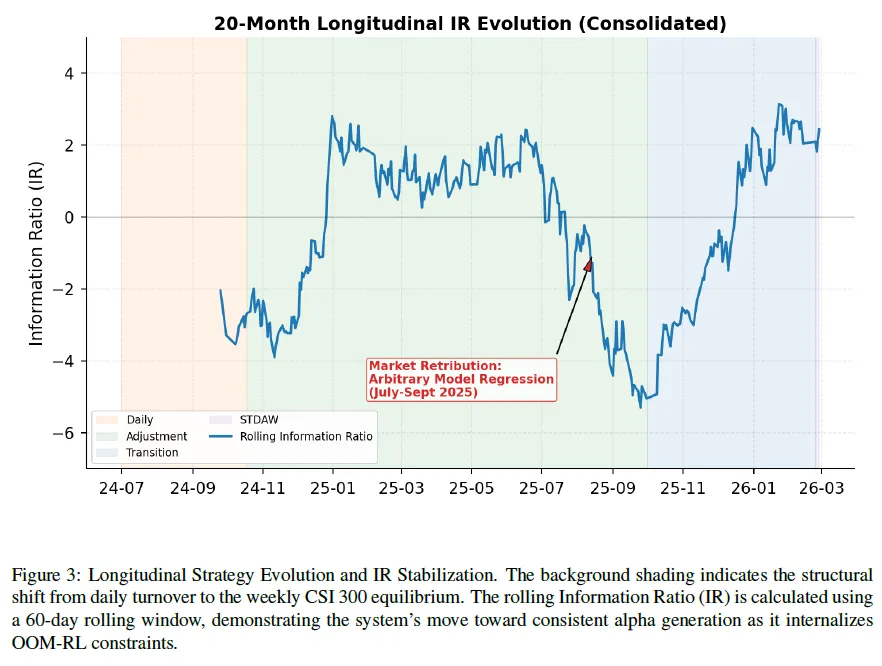
阶段0(2024年4-6月):理论优化,手动脚本模拟,聚焦动量阿尔法,策略数学优但与实际不符。
阶段1(2024年7-10月):摩擦冲击,系统日频实盘交易,微观结构损耗致回报停滞,展现模拟与现实差距。
阶段2(2024年10月-2025年10月):对话调整与回归,因阶段1损失,人机对话推导出需流动性过滤,转为周频再平衡;2025年7 – 9月无约束实验致“性能回归”,后用RO – Lock解决。
阶段3(2025年10月-2026年2月):正式过渡与STDAW启动,重构架构抗拜占庭故障,2026年2月24日推出STDAW框架,夏普比率达2.06,远超基准。
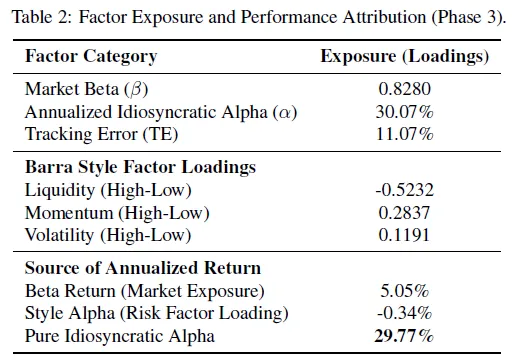
因素归因与风险分析
为判断成熟阶段的超额表现是市场动量还是真实主动阿尔法所致,用标准Barra风险模型进行多因子收益分解。表2显示,3阶段(成熟)投资组合相对沪深300基准的因子暴露情况,市场贝塔0.83呈防御姿态,系统产生29.77%纯特质阿尔法。流动性因子显著负负荷(-0.5232),表明系统学会从沪深300中流动性较差成分股获取流动性溢价。1阶段高换手率策略致交易滑点损失,3阶段STDAW/RO – Lock机制转向低换手率架构,避免早期微观结构衰退问题,证实系统表现源于主动架构调整,而非被动市场贝塔或动量暴露。
实证结果综合
20个月实证研究为基础研究问题提供有力解答。OOM – RL利用金融市场特性弥合Sim2Real差距。从研究阶段1到3,资本严格约束使多智能体系统(MAS)转向稳健架构,验证了STDAW RO – Lock机制的必要性,其约束矩阵防止“测试规避”行为。系统均衡是对微观结构摩擦的主动适应,虽特定评估期内特质阿尔法提取效果有限,但系统从资本快速损耗过渡到风险管控。研究结果证实:用现实经济惩罚替代主观评估,是高风险环境下自主系统的客观稳健对齐机制。
概括与未来工作
OOM-RL和STDAW在量化交易高随机领域获实证,其“通过客观物理和经济约束对齐多智能体系统”理念超金融市场;从本地AI助手向全自主AI软件工厂过渡时,评估递归构建系统的系统是AI对齐关键前沿。
金融之外:计算即资本(RLFCB)
非金融软件工程中缺乏即时市场损益评估对齐有挑战,提出强化学习从云计费(RLFCB)。无约束多智能体系统(MAS)生成有结构缺陷代码时,传统模拟环境难惩罚低效。RLFCB 为智能体分配“计算资本”预算,物理计算资源耗尽是微观结构摩擦的智能体。若智能体设计低效架构,耗尽资本触发金融“钱用光”(OOM)异常,这是绝对、确定性吸收状态,激励 MAS 优化算法效率和系统安全。
未知领域的RO-Lock部署
STDAW 框架基于 Python 定量 CI 基础运行,未来将使高密度确定性约束矩阵与金融领域解耦,把拜占庭 RO – Lock 架构扩展到内存安全语言(如 Rust),还将其应用于开源自主漏洞修复管道,探究单向状态锁定的结构验证能否无人监督下实现零日漏洞缓解。
自动化语义反馈循环
当前部署的OOM-RL框架依赖人工专家将金融降级转化为提示。未来将引入自动批评智能体,其通过摄入执行回溯、订单簿快照和滑点差异,自动生成架构要求,推动系统走向全闭环自动范式。
总结
本文指出当前AI对齐范式存在漏洞,即无约束多智能体系统会利用主观评估和合成沙盒。为弥合Sim2Real差距,引入OOM-RL和STDAW。20个月纵向研究显示,受实际资本损耗影响,多智能体系统放弃不切实际的幻想,从高摩擦每日再平衡模式进化到优化的每周均衡模式。研究表明,当自主AI系统可读写关键基础设施时,合成智能体评估不足,未来AI软件工厂最可靠的对齐机制是物理和经济世界的确定性后果。
我们致力于人工智能、量化交易领域前沿研究,分享前沿论文、模型代码、策略实现。如有相关需求,请私信与我们联系。
请加微信“LingDuTech163”,或公众号后台私信“联系方式”。
关注【灵度智能】公众号,获取更多AI资讯。