从文本到知识图谱:计算机技术赋能文学研究
随着数字人文技术的不断发展,工具平台建设与日俱增层出不穷。即使在这一趋势之下,其中的先行者搜韵网https://sou-yun.cn仍是无可取代的经典,它深入学人日常阅读与科研的方方面面,成为像字典和计算器一样的日常工具。创始人陈逸云兼具旧体诗人和微软亚洲工程院首席开发经理的双重身份,从十余年前搜韵网筹备创立起,所有研发工作皆是以一人之力在业余时间完成。搜韵网2009年上线以来,始终坚持开放、协作的学术立场,积极推动资源共享,致力于为学界同仁提供支持与帮助,对于推动古代文学研究的数字化发展功不可没。
搜韵网侧重于从用韵、用典、遣词、对仗以及格律校验等方面提供创作辅助,集成了可检索诗词数据库175万首以及唐宋文学编年地图、诗歌自动笺注等在线工具。在此基础上,开发者于2019年上线另外上线了“知识图谱”网站https://cnkgraph.com,其功能群体更侧重于专业研究,本质上重构了一个强大的古典文献知识逻辑化体系。“知识图谱”网站主要包括上万部古籍构成的古籍库,以及古今纪时转换、文献历时索引、人物交往及影响力研究、古今地名查询、地域影响力研究、文献自动笺注等功能。
一、“知识图谱”功能介绍
“知识图谱”网站以古籍数据库为基础,整合了人物作品集、传记资料、行迹地图、作品地点、常见称谓、相关文献等内容,同时拓展出多项研究支持工具,包括古今纪时转换、文献时序索引、人物交往网络、影响力分析、古今地名查询及文献自动笺注等。本质上是从文献中分类提取知识点,再将它们有机地关联在一起形成知识网络,并基于知识网络从一或多个维度开发能够辅助学习研究的各式应用。使用时可由一个节点切入检索,然后根据需求调取相关联的信息类。
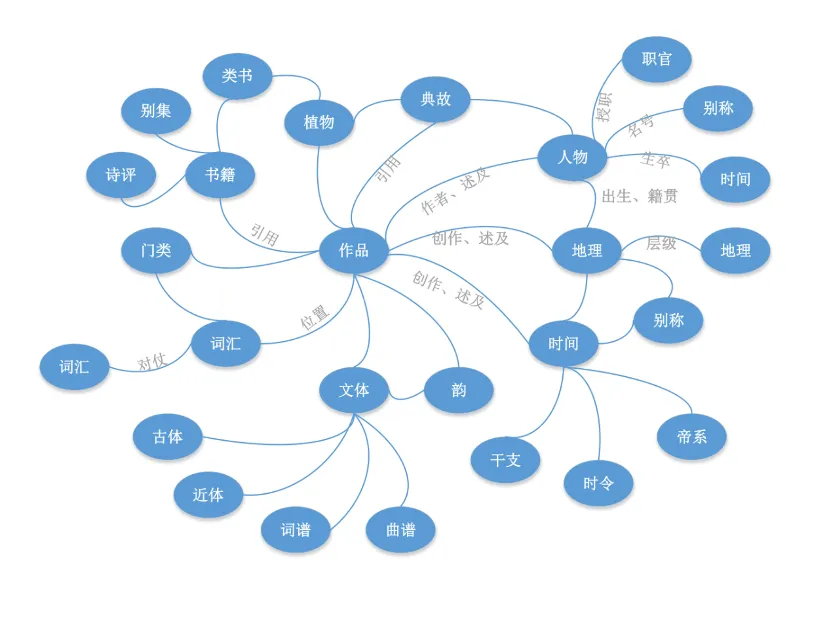
假设以人物为检索对象,可通过诗文述及、集聚分析、步韵分析、相关典故、首创词汇、祠庙陵墓等方面的相关古籍知识考索其历史影响力,下文将对以上功能逐一介绍。
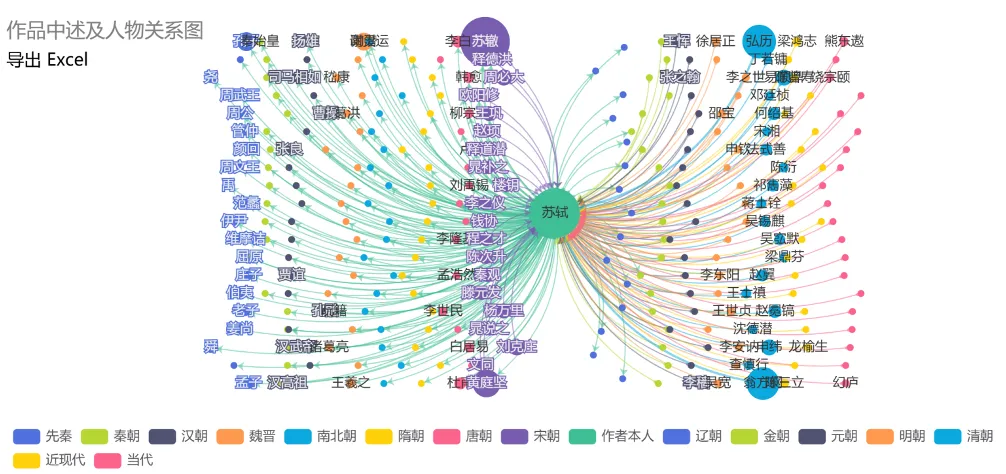
【诗文述及】知识图谱网提供了关于作品中述及的人物关系图,作为研究对象的苏轼位于正中央,如果苏轼在作品中述及其他人物,就会有苏轼指向该人物的箭头,反之亦然。人物的不同颜色代表不同的朝代,圆圈的大小则代表述及次数的多少。点击具体线条可穿透至具体的诗文信息。“导出excel”可以导出所有述及相关信息。
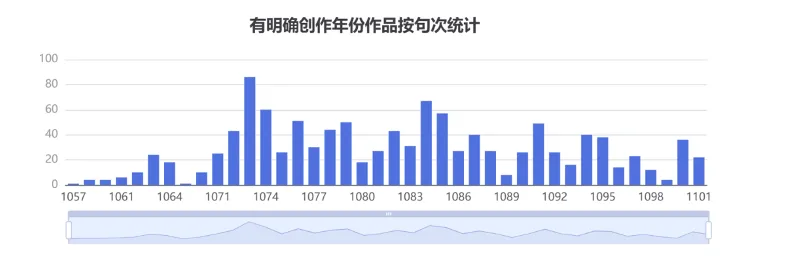
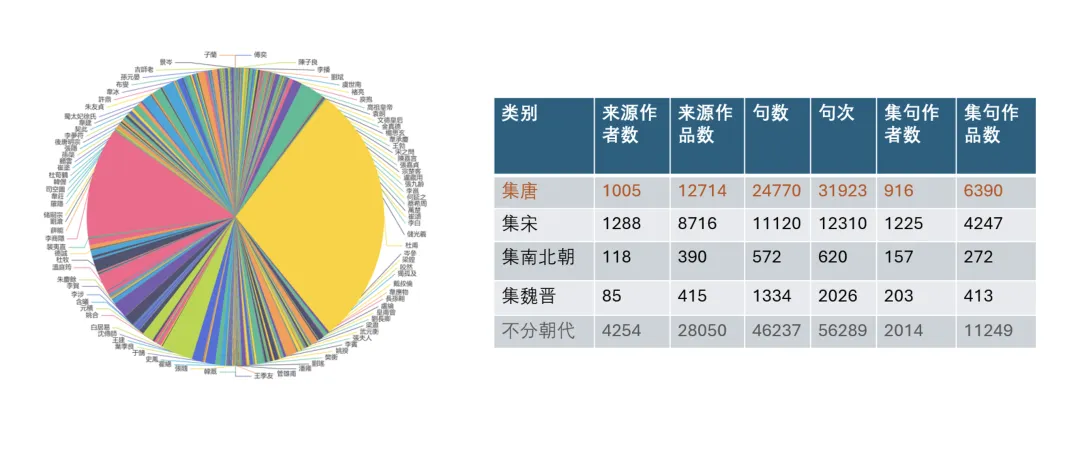
【集句分析】知识图谱网可以查看苏轼创作中集前人句的情况,也可按年份查看苏轼作品在后世的集句引用,包括集句诗作者清单,集联暗合的诗句以及集句引用作品清单等,亦可分析参与集句的篇目占作品总数的比重。
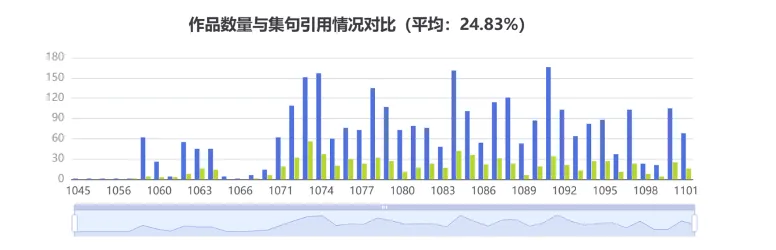
除了对单个人物的集句分析之外,集句功能还支持以特定时代为范围的集句分析。通过对魏晋、南北朝、唐、宋四个时代进行对比,可以发现集唐作品数量显著领先,是最受后世青睐的集句来源。聚焦唐代内部,杜甫与李商隐的诗句参与后世集句频率极高,两人被集诗篇占总数比例皆超过百分之九十。此类分析旨在统计对比某一时代内部不同诗人被集句的频率与分布,从而揭示世代文学遗产中,具体哪些作者对后世产生了更为显著的影响。
集句分析功能的开发大致遵循如下逻辑,以计算机可识别的方式对集句诗进行定义,然后从超过162万首作品中自动筛选出集句诗并追溯其诗句来源。其中难点在于如何处理多人写作相同诗句的情况从而准确溯源。计算机会综合考量作者所处时代、诗句上下文中出现的人名信息、以及同一首诗中其他诗句的集句来源等多个维度,以此判断该句最可能的原始出处。
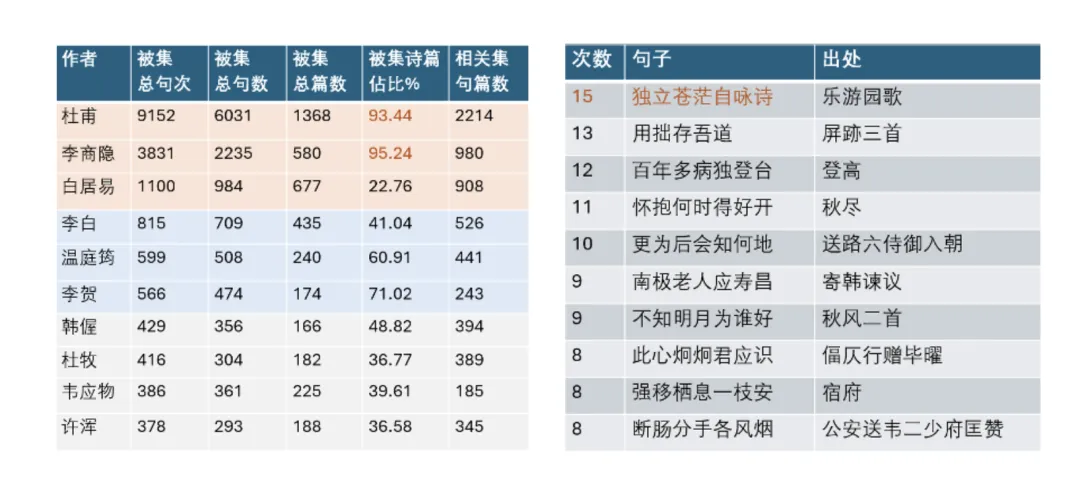
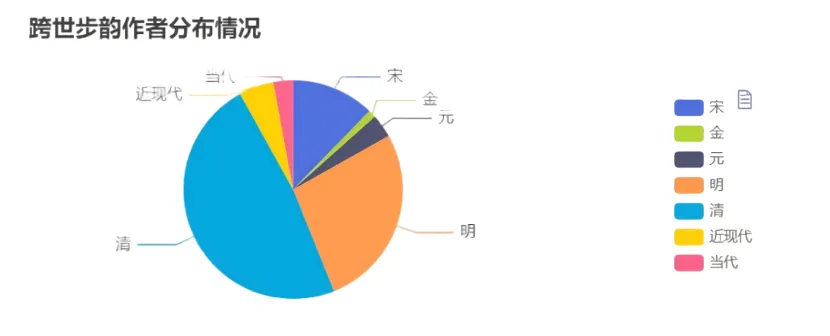
【步韵分析】回到以苏轼为例的人物检索环节,知识图谱网可以查看跨世步韵苏轼的作者清单以及步韵作品的清单,也可以对跨世步苏轼韵的作者朝代分布情况进行分析。需要注意的是,在作家作品影响的分析中没有把同时代的步韵包含在内,因为古代诗歌不仅是文学审美对象,还是一种社交的方式,因酬赠唱和而步韵的情况比比皆是,而跨世步韵之作更能直观反映作者的影响力。
步韵分析能够全面呈现特定时代作品在后世总体的步韵情况,下图即为唐代在后世的步韵分析,元韵总作品数5239首,跨世步韵作品数15751首,步韵作者数2316位,其中杜甫是被后人步韵追和最多的作者,其次为李白和韩愈。
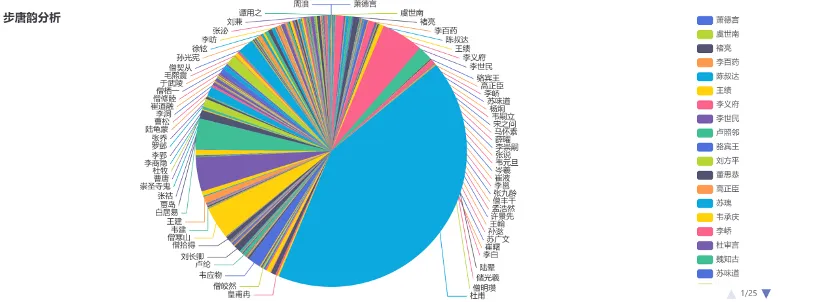
利用计算机辅助步韵研究的整体流程大致如下,首先统计了四韵、五韵及六韵相同时出现“撞韵”的比例,继而通过数据分析确定步韵诗的筛选标准:四韵相同且诗题一致,或六韵相同。随着步韵数据库建成也获得了一些新的学术发现。例如学界目前认为最早的同代步韵诗是北魏谢氏《赠王肃诗》与陈留长公主的《代答诗》,经过步韵数据库识别,又发现最早的跨世步韵诗是陈代张正见的《赋得风生翠竹里应教诗》步韵遥和东晋贺循《赋得夹池修竹诗》这组诗。这一功能也辅助澄清了后世对《归去来辞》韵脚认定的一些分歧。陶潜《归去来辞》“已矣乎,寓形宇内复几时,曷不委心任去留。胡为乎遑遑兮欲何之。”其中“时”、“之”与后文句末“期”、“耔”等字押韵,而“留”则与前文句末“丘”、“流”等字押韵。始自苏轼的绝大多数步韵作品都遵循这一规则。但南宋杨万里步韵时此处作“已矣乎,用舍匪吾,行止匪时。何至啜醨如渔父,何必乎誓墓兮如羲之。”可见他认为原作“留”字并非用韵处。无独有偶,清金熙周也是如此处理。
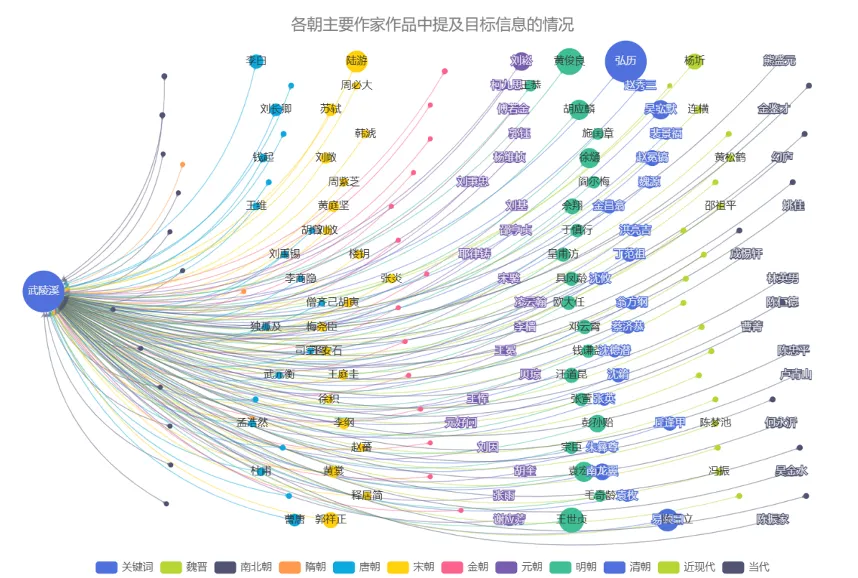
【相关典故和首创或首用词汇】知识图谱网借助了汉语大词典对词语进行溯源,判断与被检索作者有关的典故,及其首创或首用词汇,这一功能对于汉语史研究及诗歌语词使用研究有重要价值。


下图为典故使用的可视化分析,由人物指向典故表示该人物运用过该典故,人物圆圈的大小表示运用次数的多少。
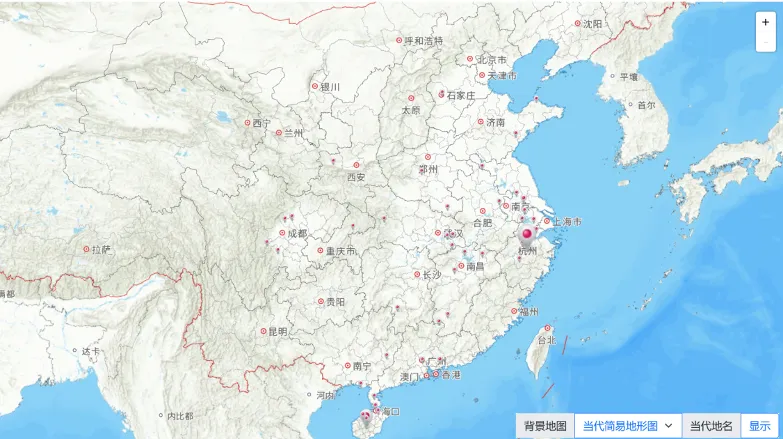
【祠庙陵墓】知识图谱网借助古今图书集成中的方志寻找所有相关寺庙陵墓,最晚收录到明末清初的方志,根据这些寺庙的位置可形成寺庙分布地图。

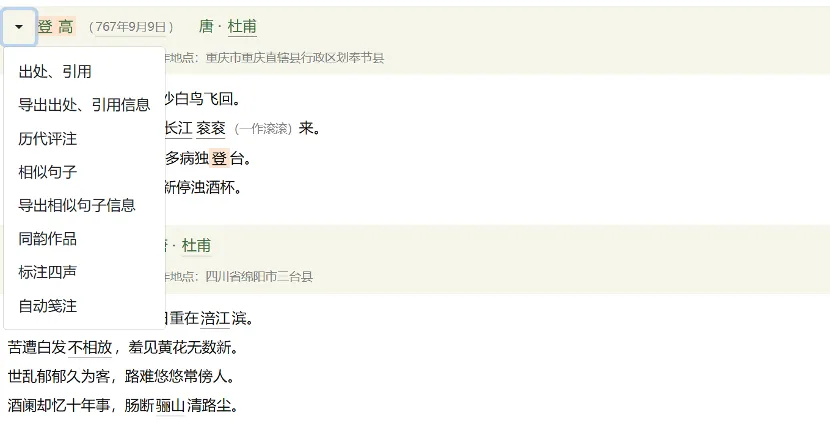
除人物检索之外,知识图谱网站同样实现了以文本为中心的考察,可辅助评估特定作品的后世影响,主要通过作品出处、引用、诗评以及句子字面相似性等维度实现。诗歌库包含诗歌的出处、引用,历代评注,相似句子,同韵作品的信息,也提供了标注四声和自动笺注功能。其中历代评注主要来自唐宋汇评。
在作家作品影响研究之外,知识图谱网还提供地理影响力分析,如各地地名和辖区范围沿革情况、进士分布、人物科举及外出为官分布、官员籍贯分布等,能够体现该地人才输入和输出的情况,从而为评估其地理影响力提供重要依据。以下以绍兴市为例的具体演示。
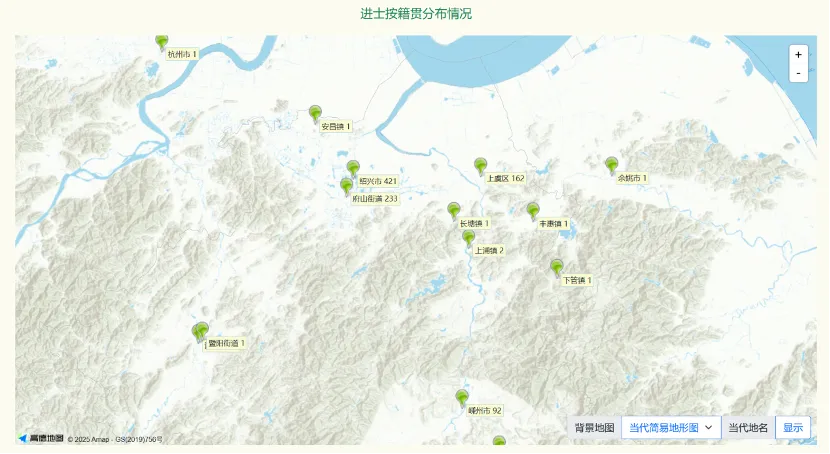
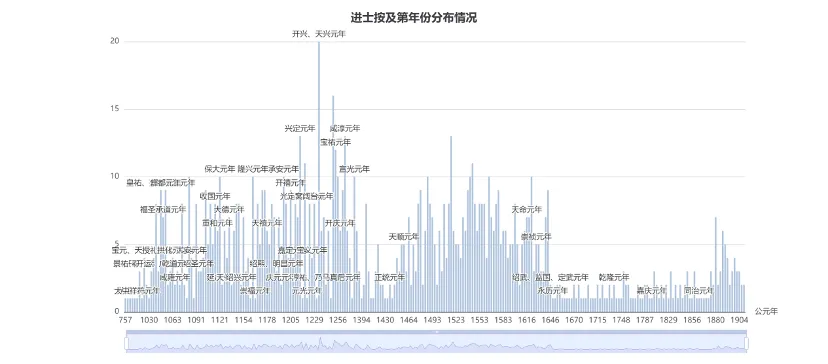
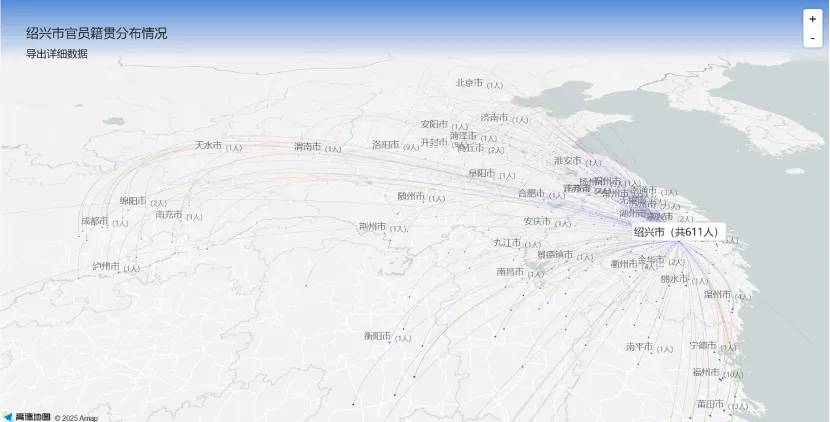
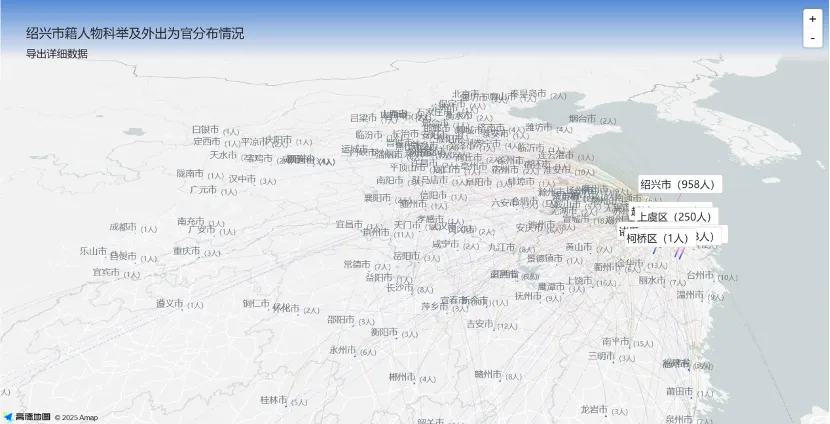
知识图谱网站作家、作品影响力研究未来的开发重点将集中于两个方面:一是继续深化各类作品影响力指标的建设,为人物及作品的影响力分析提供更全面、更系统的量化数据基础,并进一步完善集评、选集、摘句等相关数据资源。二是开发句法相似性分析功能,不仅关注字面相似性,而是深入句法结构层面比对,尝试发现相同的句式类型。分析诗句的对仗关系是识别相似句子结构的手段之一,如“风急天高猿啸哀”与“雨恶风狂燕掠斜”在句式与词类对应上便显著相似,类似的例子还有“不尽长江滚滚来”与“四月流星点点来”,以及“百年多病独登台”与“去年不死留看花”等。
二、数据驱动下的研究新范式
关于构建平台的核心方法,在开发者看来基于文学知识逻辑化的方法显著优于单纯依赖机器学习。一方面,机器学习依赖大规模高质量数据集,而古籍文献资源存量有限、标注不易,数据基础的不足严重制约了机器学习的效果;另一方面,机器学习本身并不创造新知识,也难以从有限样本中可靠地总结深层规律,导致其在古诗文分析中准确率与效率不高。例如,在识别格律诗时,即使向大语言模型输入大量诗作,它仍难以自发归纳出完整的格律规则;反之,若将格律判断转化为明确的计算机可识别指标,并结合统计归纳与贝叶斯算法,则能够实现更高效、更准确的格律识别。尽管这类基于规则的方法难以泛化,但在特定任务上的准确率和处理效率更具优势。下文将在文学知识逻辑化的框架下,系统阐述知识库的构建方法与具体流程,主要有这样两个关键部分:一是知识图谱网站所依赖的数据集建设,二是相应数据处理工具的研发与应用。
知识图谱网的数据集由多个专题库构成,包括人物库、诗文库、地名景观库、词汇库、字典库、典故库、纪时库等。各种原始资料之间共享信息、互相补充,共同服务于数据集的建设。词汇库中的词语按含义进行分类整理,汇总意义相同或相近的词语,系统梳理每个词语的各类释义。典故库为提升识别准确性,会提取典故的关键特征并生成特征标签;在判断作品是否使用典故时,主要依据作品中含有多少相关特征,而不只是依赖关键词匹配。此外,在识别诗文类型时,系统会同时调用诗文库和词汇库的数据,一方面通过分析诗文库中的诗歌,提取题目中的关键词并归纳不同类型诗的结构特点,另一方面借助词汇库中的词语出现频率统计,通过特征词的频次来辅助判断具体的诗歌类型。
数据处理工具包括诗集校录、标签化实体对齐、知识抽取和数据清洗。为有效消除歧义、避免混淆,数据处理未采用简单的关键词识别方法(该方法错误率较高),而是依托标签化实体对齐技术,通过结合上下文语境、不同类别实体相互参照、以及个人作品集与全体作品集比对等多种方式,实现更精准的消歧与对齐。
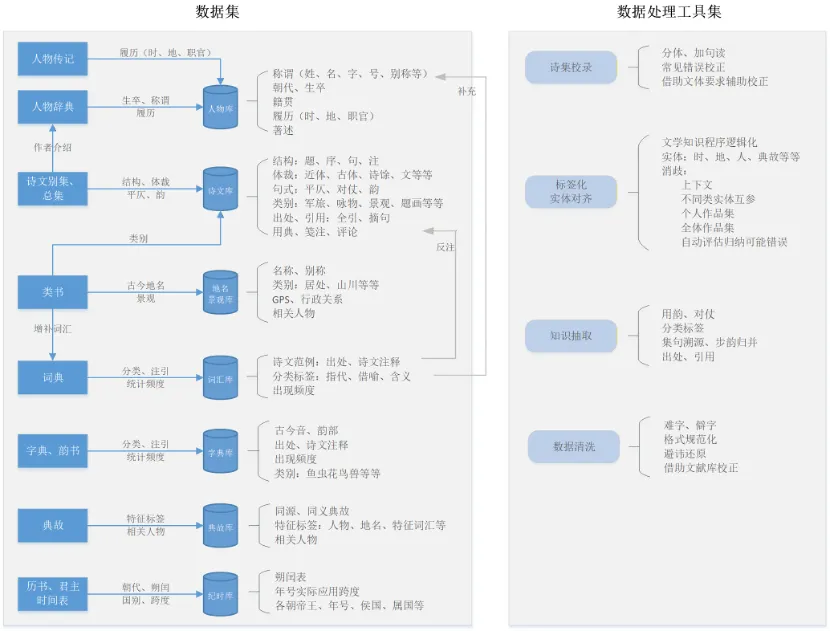
专名提取的技术路线主要包括三大模块。首先是基础技术方案,核心为“基于分类词典树Trie分词与FAISS的消歧框架”,涵盖分类词典树构建、文本拆分、专名匹配消歧及综合推断优化等关键步骤。
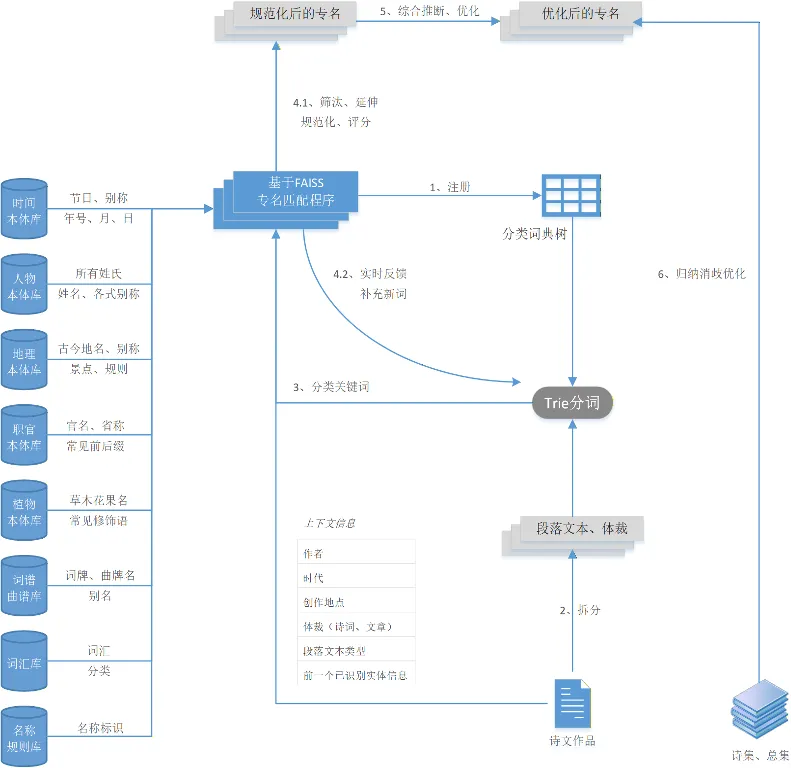
其次是专名消歧的典型应用,该部分以人名实体为例,系统展示如何结合人物本体属性、实时反馈机制以及含人名文本的表达范式等多个维度实施消歧;最后是本体库构建模块,明确了以专名提取技术为支撑、以人名实体为示例的本体库构建路径。
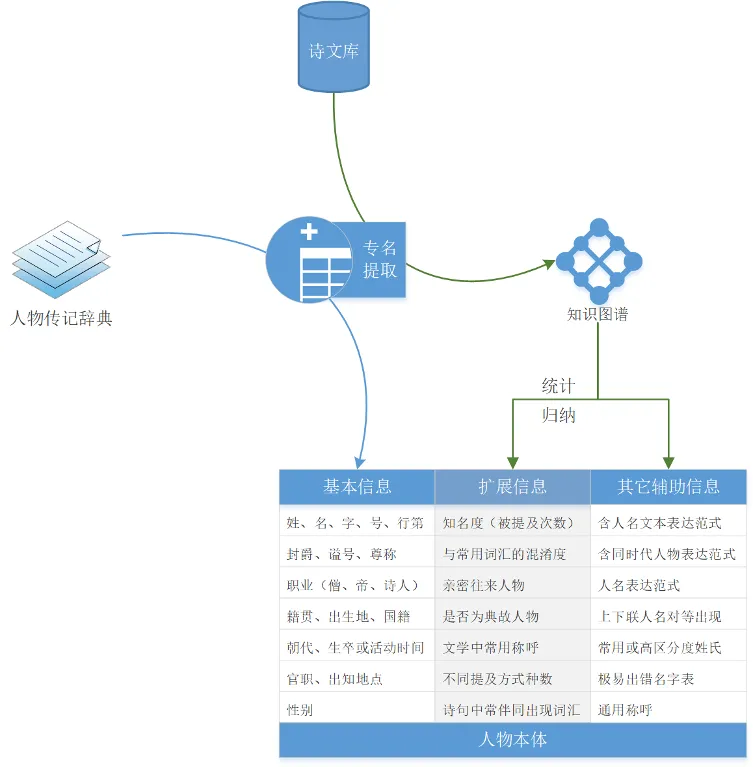
知识图谱网站构建过程中重点关注两个原则:一是支持可增量式扩展,随着研究的深入与新数据的不断出现,网站应具备灵活添加内容的能力,为后续更新预留空间;二是实现可重复构建,即尽量依托自动化工具集完成更新与重建,减少依赖人工直接修改数据,以避免在后续更新过程中覆盖先前的手动调整。网站的数据录入方式即符合以上原则。首先对原始数据进行规范化预处理,如统一汉字编码、将诗篇排版调整为一行一诗的标准格式。随后,将整理后的诗歌文本复制到知识图谱平台的录入界面,系统会自动完成单首诗篇的切分与句读标注。在此基础上,平台能够自动识别出可能存在问题的部分——如错别字、格律错误等,并提示进行人工核对与修正,从而完成初步的数据校验。
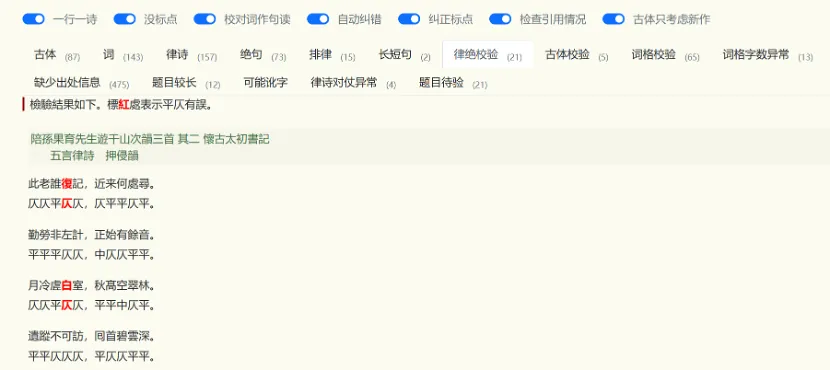
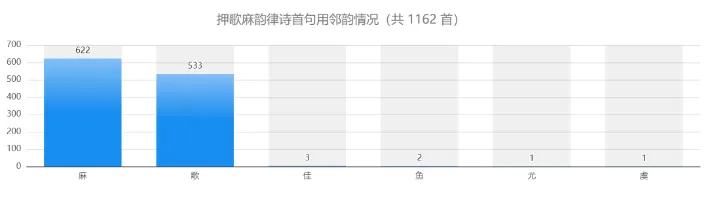
平仄分析功能可应用于诗歌音韵研究,例如“岑参”的“参”字应读作“shēn”还是“cān”,可通过检索以“岑参”为句尾的律诗,依据其押韵情况来推断历代诗人的实际读法倾向——结果显示更支持“cān”音。此外,知识图谱网也可用于分析律诗中三仄尾、三平尾、孤平、拗救等特殊韵律现象。在近体诗用韵方面,诸如主题用韵规律、首句借用邻韵、多韵混用等现象,均可借助该平台展开系统研究。知识图谱网还支持对近体诗用韵规律的研究,如主题用韵、首句借用邻韵及多韵混用等情况,从而为音韵研究提供扎实的数据支持。
知识图谱网站上线以来,参与推动了多项不同领域的文史研究,例如城乡规划领域的成都诗词景观分析、文学传播方向的范成大诗歌接受研究、《宋诗汇评》数字化,以及苏轼作品情感分析与行迹标注的综合性任务。以上实践表明,在基础资料处理环节借助计算机可大幅提升效率,使学者更能专注于需要专业深度思考和研究的工作,这也说明人机协同的中文学者未来研究新范式具有广阔发展前景。借助宏观、系统的数据支持,能够为学者开辟新的兴趣点与研究思路,具体表现为:其一,通过量化分析,使文学现象与作家作品具备更强的可比性,推动研究成果的可视化呈现;其二,大幅提升文献搜集、整理与分析的效率,将学者从繁复的资料工作中解放出来,从而更专注于思想内涵与艺术特色的深度阐释;其三,支持从时代、流派、个体等多维度、多粒度展开探查,为传统文学研究提供新的线索与视角。在此基础上,未来的中文学术研究范式将朝向人机协同的方向演进:学者可使用自然语言描述所需数据,由AI从数据库中智能筛选;也可直接提出各类数据处理需求,借助AI完成归纳、统计与比较分析等工作。这将使研究者从繁琐的信息处理中解放出来,将更多精力投入思想层面的提炼与观点阐发。当然,这样的研究模式离不开扎实的数据与系统基础,期待未来有更多学者能参与到相关工作中来,共同推动这一研究范式的实现与发展。
(陈逸云讲授 乔麟舒整理)