

营销增益模型之 Uplift Tree
因此,T不能视为普通特征,它是干预状态的标记,具有特殊地位。
混杂变量 是 同时影响 T 和 Y 的变量。
假设有实验数据:
-
X = 用户活跃度(0 = 低活跃,1 = 高活跃)
-
T = 是否发券(1 = 发,0 = 不发)
-
Y =是否购买(1 =买,0 =不买)
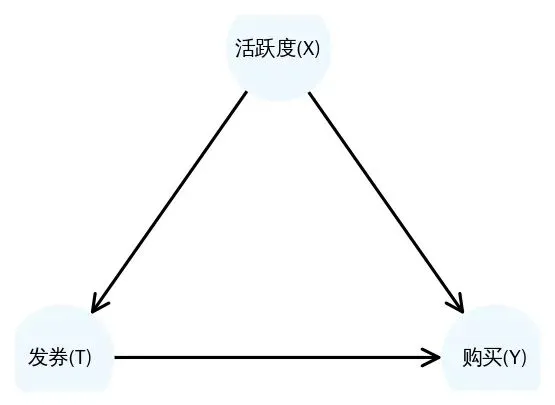
用户活跃度同时影响T和Y(如下图),用户活跃度是一个典型混杂变量。
-
1. 用户活跃度 X 影响 T(干预)
运营只给高活跃用户发券 → X=1 → T=1 的概率很高
-
2. 用户活跃度 X 也影响 Y(购买)
高活跃用户本来就更爱买 → X=1 → Y=1 的概率天然更高
此时,你会观察到:
-
发券的人(T=1)购买率很高 -
不发券的人(T=0)购买率很低
于是,你得出结论:发券效果好!但真相是:不是券有用,是这群人本来就爱买。混杂变量让你把 “人群差异” 当成 “干预效果”。
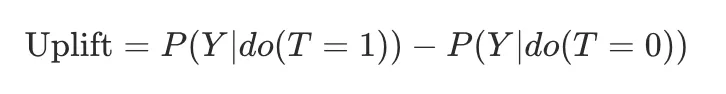
其中,do(T=1)表示强行、外生地给人发券(不受混杂变量影响)。因此,为了准确估计增益,必须消除X对T的影响。
-
方法1:使用RCT数据
RCT(Randomized Controlled Trial ,随机对照试验)数据能保证 T=1 和 T=0 的人是可比的,混杂变量 对 T 的影响被强行清零。
-
方法2:如果没有RCT数据,需要使用算法做 “事后消除”。
-
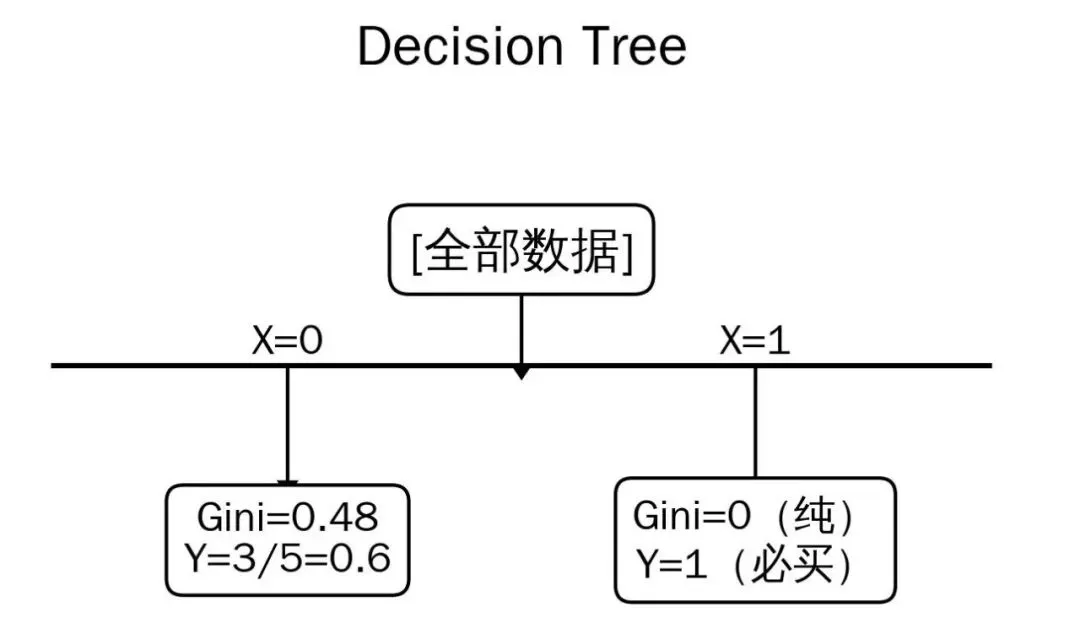
Decision Tree(决策树) -
样本形态:(X, Y)
-
分裂目标:让子节点内的标签 Y 更纯
-
切分标准:左子树与右子树的不纯度(越小越好)
-
公式:
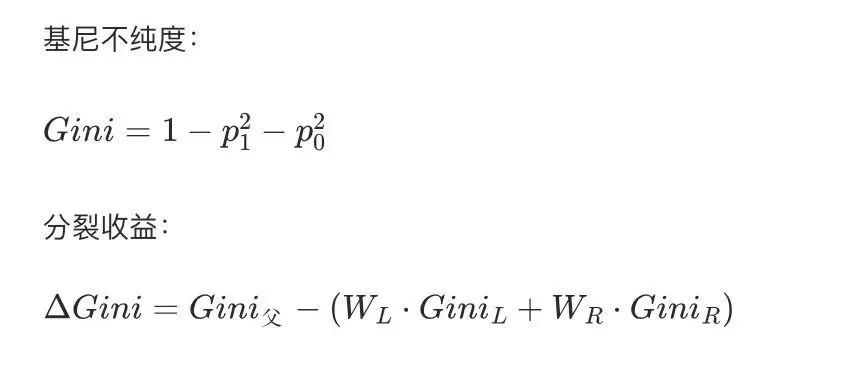
其中,p1表示Y=1发生的概率,p0表示Y=0发生的概率。
-
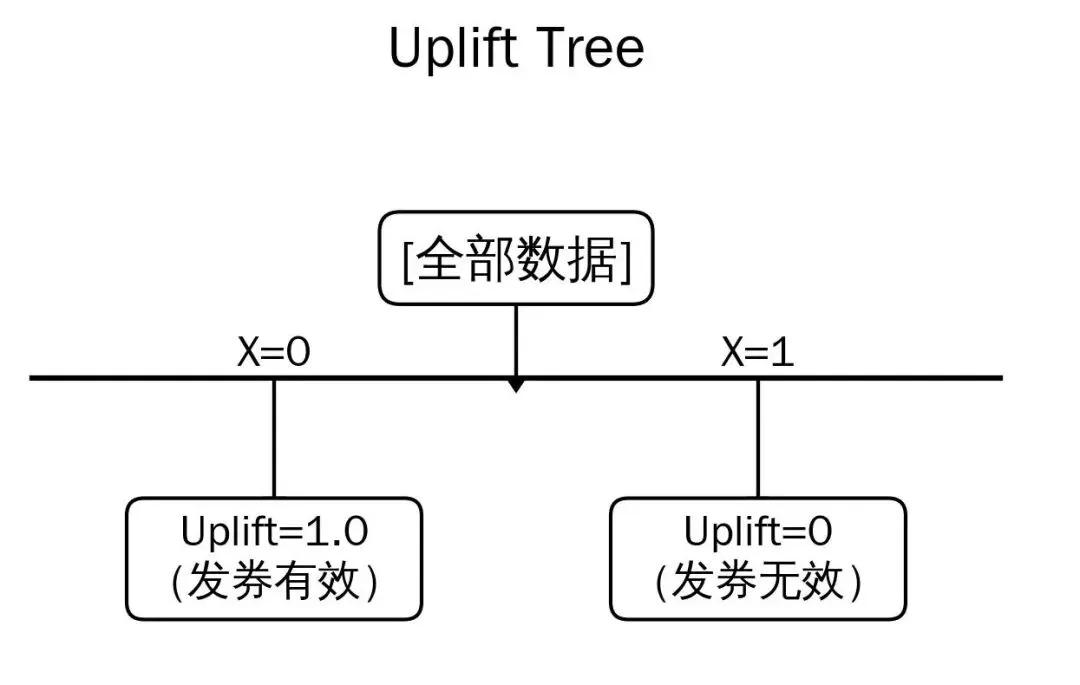
Uplift Tree(增益树) -
样本形态:(X,T,Y) -
分裂目标:让实验组 T=1 与对照组 T=0 的 Y 差异最大化。 -
切分标准:左子树与右子树的增益差(越大越好) -
公式:
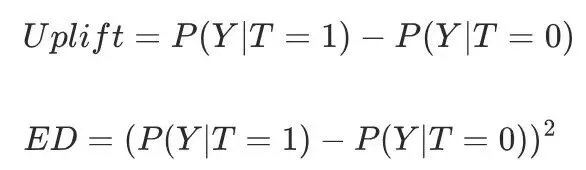
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
-
Decision Tree分裂过程
-
父节点的Gini
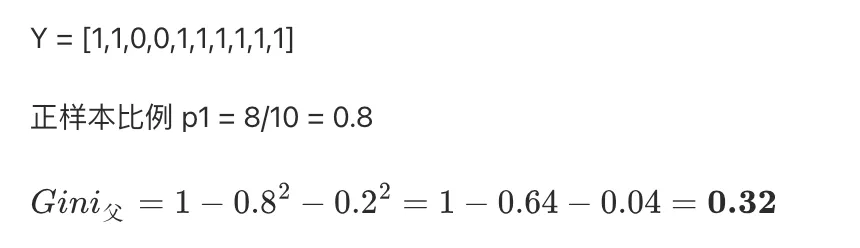
-
按特征X分裂后的Gini

-
不纯度变化
∆Gini = 0.32 - 0.24 = 0.08 (分裂后的不纯度下降,可以分裂)
-
Uplift Tree的分裂过程
-
父节点的欧式距离

-
按特征X分裂后的欧式距离

-
欧式距离变化
∆ED = 0.5 - 0.16 = 0.34 (分裂后的欧式距离增大,可以分裂)
五、总结分析
评论