深入理解计算机系统1.3:系统的硬件组成:总线、I/O、主存、处理器
在前两节课中,我们已经明白了“信息”的本质(位+上下文),也亲手见证了一个程序从源代码(C/C++ 或 Rust)经历编译、汇编、链接,最终变成可执行文件(二进制)的全过程。
现在,我们要解决一个核心问题:这个编译好的“可执行文件”,究竟是在什么样的物理结构上跑起来的?
这一节(1.3),我们就来解剖这个躯体——计算机系统的硬件组成。它将是你理解一切软件运行机制的基石。所以我会讲的相当详细。
冯·诺依曼体系结构
在冯·诺依曼结构诞生之前(例如早期的ENIAC),计算机更像是一个巨大的计算器。如果你想让它算加法,你需要物理地插拔电缆来改变电路;如果你想让它算乘法,得重新接线。
冯·诺依曼在1945年提出的核心天才构想是:存储程序。
非冯·诺依曼(老式):你的老式电视遥控器。电路是焊死的,按“音量+”就是音量加,你不能通过下载一个文件让“音量+”键变成“换台”键。
冯·诺依曼(现代):你的手机。硬件(屏幕、CPU)没变,但你可以下载“微信”APP,也可以下载“王者荣耀”APP。这些APP就是“程序”。
关键点:计算机不再区分“数据”和“指令”。在内存里,代码(指令)和处理的数据(比如照片、文档)被一视同仁,都以二进制形式(0和1)存放在同一个存储器中。
核心概念:存储程序原理 (Stored-program concept)
定义:程序(指令)和数据没有物理上的区别,它们都以二进制形式存储在同一个读写存储器(Memory)中,并由统一的地址系统访问。
实例说明:假设内存是一排带有编号的格子的集合(地址)。在冯·诺依曼机器中,内存可能是这样排列的:
| 内存地址 |
内存中的内容 (二进制) |
含义 (CPU解码后) |
类型 |
0x0001 |
10110000 00000101 |
指令
|
代码 |
0x0002 |
00000100 00000101 |
指令
|
代码 |
|
|
|
|
|
0x0005 |
00000000 00000011 |
数据
|
数据 |
过程:CPU 的程序计数器 (PC) 指向地址 0x0001,取出内容。控制器发现这是“指令”,于是执行。接着 PC 指向 0x0002,执行加法。加法需要用到地址 0x0005 的内容。
关键点:对于内存硬件来说,它不知道 0x0001 存的是代码,0x0005 存的是数据。是 CPU 在取指周期(Fetch)把它当指令,在执行周期(Execute)把另一个地址的内容当数据。
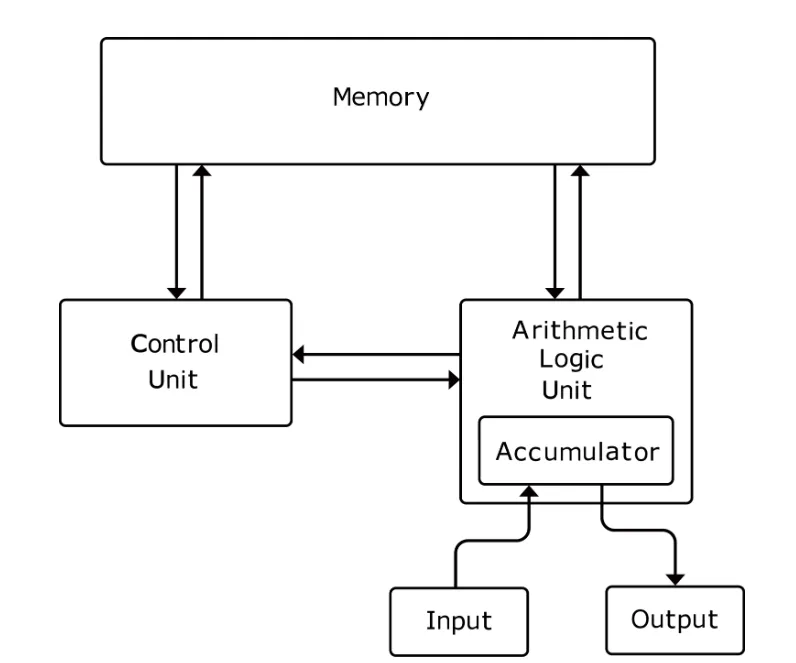
冯·诺依曼定义了计算机必须由五大部件组成。我们会结合具体的硬件实例来看:
1. 运算器 (Arithmetic Logic Unit, ALU)
逻辑运算:判断“与”、“或”、“非”(例如:判断 A 是否大于 B)。
实例:当你在Excel里输入 =10+20 时,Excel软件本身不能算,它必须把这两个数送到CPU内部的ALU里,ALU通过逻辑门电路瞬间算出 30。
2. 控制器 (Control Unit, CU)
它是“指挥官”。它从内存读取指令(如 ADD),解码后发出控制信号(告诉 ALU “做加法”,告诉内存 “开启读取模式”)
注:现代 CPU 中,CU 和 ALU 被封装在一起,统称为 CPU(中央处理器)。
实例:当程序里有一行代码 if (x > 0),控制器会读取这条指令,分析出这是一条“跳转指令”,然后告诉计算机:“如果运算器算出来 x 是正数,下一条指令去读内存地址 005,否则继续读 004。”
3.存储器 (Memory)
这是冯·诺依曼结构的精髓。它是一个线性的列表,每个位置都有一个编号(地址)。
实例:你的电脑内存条(RAM)。假设它是一个巨大的表格:
地址 0001:存放指令 LOAD A (把A拿来)
地址 0003:存放指令 ADD B (加上B)注意:对存储器来说,它不知道0001存的是指令,0002存的是数据,它只管存0和1。只有控制器读取时才知道怎么解释。
4. 输入设备 (Input Device)
将人类能懂的信息(文字、声音、图像)转换为计算机能懂的二进制数据。实例:键盘、鼠标、麦克风、摄像头。
5. 输出设备 (Output Device)
将计算机处理后的二进制结果,转换回人类能懂的形式。实例:显示器、扬声器、打印机。
总线的本质
总线是计算机系统中连接各主要组件(如CPU、内存、输入输出设备)的公共通信线路。它负责在各部件之间传输数据、地址和控制信号。
在物理上,总线是一组物理导线(或电路板上的走线),为多个硬件部件提供共享的传输通道。在逻辑上,它定义了部件之间如何“对话”。总线按功能分为三类,它们通常协同工作。
1. 数据总线
功能:承载实际要传输的信息(指令、整数、浮点数、字符等)。它是双向的(CPU 既要读也要写)。
一个32位数据总线意味着它有32根导线,可以同时传输32位(即4个字节)的数据。当CPU从内存地址0x1000读取一个整数时,这个整数的32位二进制值就是通过数据总线从内存传送到CPU的。
将一个1MB的文件从硬盘加载到内存。数据总线负责传输这个文件的所有二进制内容。位宽更宽的数据总线(如64位)能比位宽较窄的(如16位)在单位时间内传输更多数据,从而提高效率。
2. 地址总线
作用:CPU用来指定它要读取或写入的内存位置或I/O设备端口的地址。CPU 告诉内存“我要读哪一个格子的数据”。它是单向的(由 CPU 发出,指向内存或外设)。
一个拥有32位地址总线的系统,其每根线可表示0或1,总共能产生2³²个不同的地址组合,因此CPU可以唯一寻址4GB(2³²字节)的内存空间。如果你想安装一块8GB的内存条,这个系统将无法识别和使用超过4GB的部分。
当CPU需要读取内存地址0xA0B1C2D3处的数据时,它会通过地址总线将这个32位的地址值发送给内存控制器。内存控制器根据这个地址找到对应的物理内存单元。
3. 控制总线
传输各种控制信号,协调各部件间的操作时序和动作。决定“动作”
读写信号:一根信号线指示当前操作是读(从内存/设备取数据)还是写(向内存/设备存数据)。
中断请求:当键盘被按下或硬盘完成数据读取时,相应设备会通过控制总线中的一根特定线路向CPU发送一个中断请求信号,通知CPU来处理。
如果没有控制总线,内存不知道是要把地址 100 的内容读出来,还是要写进去。
控制总线:一旦 CPU 拉低 Memory Write (MEMW) 信号线(电平变低),内存就知道:“哦,现在是写入操作”,于是把数据总线上的 5 存入地址 100。
工作流程示例:CPU从内存读取数据
总线仲裁
问题:总线是共享资源,当多个“主设备”(如CPU、DMA控制器、图形处理器)同时请求使用总线时,需要决定使用权归属。
实例:在一个系统中,CPU正在通过总线访问内存,同时,一张网卡收到了一个数据包,希望通过直接内存访问(DMA)方式,不经过CPU而直接将数据写入内存。
这就是为什么你拷贝大文件时,电脑可能会稍微卡一下,因为 DMA 正在和 CPU 抢占总线资源。
同步 vs 异步 总线时序
这是两种协调发送方和接收方速度的通信协议。设备之间如何配合默契?
同步总线
原理:所有设备都连接到一个公共的时钟信号。每个操作都在固定的时钟周期内完成。
动作:在第 1 声“滴”发出地址,规定在第 3 声“滴”数据必须到达。
缺点:短板效应。总线速度必须迁就最慢的那个设备,且受限于导线长度(电信号传播需要时间,线太长,第 3 声滴答时数据可能还没跑过来)。
异步总线
原理:没有统一的时钟。通信依靠“握手”信号来协调。发送方和接收方通过一组特定的控制线(如“请求”、“就绪”)来确认每一步的完成。
USB、I²C总线。在I²C总线中,主设备发起传输后,会等待从设备拉低一条“应答”线,确认收到数据。从设备处理速度可快可慢,只要它在超时前完成应答即可,主设备会等待这个信号。
优点:灵活,可以连接速度差异巨大的设备(CPU 极快,硬盘极慢,互不影响)。
同步总线:类似于军训齐步走,所有人必须跟上统一的口令(时钟)节奏。
异步总线:类似于两个人对话,A说:“数据给你了”,然后等待。B处理完后说:“收到了,下一项”,然后对话继续。
你会发现,CPU 的速度(GHz 级别)已经快得惊人,但总线的速度和内存的速度增长却相对缓慢。 现代计算机最大的悲剧在于:运算器算得太快,而总线搬运数据的速度太慢。CPU 大部分时间其实是在空转(Stall),等待数据从内存通过总线慢吞吞地运过来。这就是著名的‘冯·诺依曼瓶颈’。
为了解决这个问题,计算机科学家并没有发明一种“既超级快又超级便宜”的神奇内存(因为物理定律不允许),而是利用统计学原理设计了存储器层次结构。
存储器层次结构 (Memory Hierarchy)
1. 金字塔模型:距离 CPU 越近,速度越快,容量越小,越贵
我们需要看具体的数量级差异(这是直觉无法感知的):
计算机存储系统采用分层设计,目的是在速度、容量和成本间取得平衡:
实际层次示例(以Intel Core i7系统为例):
L1缓存:每核心32KB数据缓存+32KB指令缓存,延迟1-2纳秒
主存(DRAM):8-32GB,延迟60-100纳秒
SSD存储:512GB-2TB,延迟50-150微秒
访问时间对比:从寄存器读取数据约0.5纳秒,从SSD读取约50微秒——相差10万倍。
局部性原理
为什么我们只需要很少的 L1/L2 缓存,就能让 CPU 觉得似乎整个内存都很快?因为程序访问数据不是随机的,而是有规律的。
int sum = 0;int arr[1000];for (int i = 0; i < 1000; i++) { sum = sum + arr[i];}
时间局部性 (Temporal Locality):
实例:变量 sum 和 i。在循环的每一步都在用它们。
硬件对策:把 sum 和 i 放在寄存器或L1 缓存中,绝不放回主存,直到循环结束。
空间局部性 (Spatial Locality):
概念:如果一个数据项被访问,那么它旁边的数据项也很快会被访问。
实例:数组 arr。当你访问 arr[0] 时,紧接着你就要访问 arr[1]。
硬件对策:当你命令 CPU 去主存拿 arr[0] 时,内存控制器不仅会给你 arr[0],还会把 arr[0] 到 arr[15] 这一整块数据(称为一个Cache Line,通常 64 字节)一起搬进缓存。
结果:当你下次需要 arr[1] 时,CPU 发现它已经在 L1 缓存里了(Cache Hit),无需再去慢吞吞的主存。
主存的内部构造
即使有缓存,主存(Main Memory)依然是数据的大本营。现代主存几乎都是DRAM (Dynamic Random Access Memory)。
硬件单元:一个比特(1 bit)由1个电容和1个晶体管组成。
漏电问题:电容就像一个会漏水的小桶。存进去的电荷会慢慢泄漏。如果不理它,几十毫秒后 1 就会变成 0,数据就丢了。
刷新 (Refresh):为了保住数据,内存控制器必须每隔几十毫秒(如 64ms)对所有单元进行一次读取并重写。
代价:“刷新”期间,内存是无法响应 CPU 读写的。这就是为什么 DRAM 比 SRAM(静态随机存取存储器,不需要刷新,但电路复杂占地大)慢且有延迟的原因之一。
内存编址:字节序 (Endianness)
内存是一个巨大的字节数组,每个地址对应 1 Byte (8 bits)。但是,现代数据类型通常大于 1 Byte(如 int 是 4 Bytes)。
问题:这 4 个字节在内存里怎么摆放?是从左到右,还是从右到左?
假设有一个十六进制整数:0x12345678(共 32 位)。 它由 4 个字节组成:12 (高位), 34, 56, 78 (低位)。 假设我们要把它存入从地址 0x00 开始的内存。
大端序 (Big Endian)—— 符合人类直觉
内存布局: | 地址 | 内容 | | :— | :— | | 0x00 |12| | 0x01 | 34 | | 0x02 | 56 | | 0x03 | 78 |
小端序 (Little Endian)—— 看起来是反的
内存布局: | 地址 | 内容 | | :— | :— | | 0x00 |78| | 0x01 | 56 | | 0x02 | 34 | | 0x03 | 12 |
应用:Intel x86 架构、大部分 ARM 架构(Android/iOS)。
随机访问 (Random Access):我们要拿第 1000 号柜子的东西,不需要从第 1 号开始找,直接跳到第 1000 号,耗时和拿第 1 号是一样的。这是 RAM 名字的由来。
破坏性读取:在 DRAM 的物理层面,很多时候‘读取’电容里的电荷会把电放光。所以读操作在硬件底层其实是‘读出+写回’的过程,这又增加了复杂的时序控制。
I/O 接口的功能
这是计算机硬件与操作系统打交道的关键接口。如果没有 I/O 系统,计算机就是一个把自己锁在黑屋子里空转的大脑,既看不见也说不出。
不要把 I/O 接口简单理解为机箱背后的 USB 插孔。在硬件层面上,它指的是设备控制器 (Device Controller)——一块插在主板上或集成在 CPU 附近的电路板/芯片(比如显卡、网卡、硬盘控制器)。
接口作用:CPU 只能看懂 TTL 电平(高低电压代表 0/1)和并行数据。I/O 接口负责将上述物理信号转换为 CPU 数据总线上的0 和 1。
实例:当你按下键盘上的 ‘A’ 键,键盘内部电路(I/O 接口的一部分)检测到矩阵电路的坐标 (2, 1) 被导通,查询内部 ROM 表,将其转换为扫描码 0x1E,然后放在数据总线上供 CPU 读取。
接口作用:如果没有缓冲,CPU 必须傻等着网卡一个比特一个比特地收数据。I/O 接口内部通常有数据寄存器 (Data Register)或RAM 缓冲区。
实例:网卡收到网络包时,先暂存在自己的缓冲区里,等凑够了一整帧(Frame),再通知 CPU 一次性取走。
CPU 与外设的三种对话方式
这是操作系统设计和驱动开发的核心逻辑。我们通过代码执行流程来看它们的区别。
1. 程序查询方式 (Polling) —— CPU 全程参与,效率极低
// 伪代码:CPU 想要从键盘读取一个字符while (Keyboard_Status_Register == NOT_READY) { // CPU 就在这里死循环,什么别的事都做不了 // 这一行代码会根据 CPU 频率每秒执行几十亿次空转}// 等到状态变成 READY,才读取数据char c = Keyboard_Data_Register;
硬件行为:CPU 不断通过地址总线询问 I/O 接口:“数据好了没?” I/O 接口回答:“没”。
适用场景:极简单的嵌入式系统(如老式洗衣机控制器),或者对实时性要求极高且任务单一的场景。在现代 PC 中几乎已被淘汰,因为它极度浪费 CPU 算力。
2. 中断驱动方式 (Interrupts) —— CPU 被动响应,效率大幅提升
CPU 专注于计算,当外设准备好时,外设通过中断请求线 (IRQ)发送电信号给 CPU。
代价:上下文切换 (Context Switch)是有成本的。
3. DMA (Direct Memory Access) —— 彻底解放 CPU
为了解决上述“频繁中断”导致 CPU 过载的问题,引入了 DMA 控制器。
核心思想:CPU 只当下达命令的老板,搬运工由 DMA 担任。
中断方式:搬运 4KB 可能需要 4096 次中断。
DMA 方式:搬运 4KB 只需要1 次中断(只有开始和结束时 CPU 参与)。
你会发现,I/O 系统的进化史,就是CPU 不断推卸责任的历史。
后来,CPU 让外设叫它(中断),但数据还得 CPU 亲自搬。
现在,CPU 连搬运都不干了,雇了 DMA 来搬,自己只负责发号施令。
这种‘去中心化’的设计,是现代计算机能同时流畅运行几十个程序而不卡顿的根本原因
处理器
这是整个计算机组成原理中“含金量”最高的部分。我们不再把 CPU 看作一个黑盒子,而是拆开盖子,看里面的齿轮是如何咬合的。
CPU 的内部逻辑其实可以被简化为两个部分:干活的(Datapath/运算器)和指挥的(Control Unit/控制器)。
运算器 (Datapath/ALU)
1. 算术逻辑单元 (ALU)
输入:通常是两个二进制数(操作数 A 和 B) + 一个控制信号(操作码)。
输出:一个运算结果(Result) +状态标志 (Flags)。
状态标志实例:这是编程中 if (a > b) 的硬件基础。
2. 通用寄存器组 (General Purpose Registers)
为什么要它?ALU 速度太快了(光速级电路延迟),如果每次运算都要去内存(DRAM)拿数据,ALU 就要等待几百个周期。
实例: 在 x86 汇编中,EAX, EBX, ECX 就是寄存器名字。 指令 ADD EAX, EBX 的意思是:直接把 CPU 肚子里的 EBX 和 EAX 相加,结果存回 EAX。这个过程不需要访问内存,速度极快(<1ns)。
控制器 (The Control Unit – CU)
控制器不处理数据,它只负责发出信号告诉其他部件该做什么。
程序计数器(PC)是CPU中的一个特殊寄存器,用于存储下一条要执行的指令的内存地址。
指令周期的五个阶段 (The 5-Stage Cycle)
为了执行一条指令(例如 ADD R1, R2, R3 —— 把 R2 和 R3 加起来放到 R1),CPU 内部发生了什么?
2. 硬布线 vs 微程序 (Hardwired vs. Microprogrammed)
提升性能的黑科技
1. 流水线技术 (Pipelining)
2. 多核 (Multi-core)
原理:简单粗暴地在芯片上复制多份完整的“Datapath + CU”。
关键点:多核并不意味着单线程程序(如老游戏)跑得更快。它只意味着你可以同时跑更多程序,或者跑经过特殊编写的并行程序。
共享资源:通常每个核心有独立的 L1/L2 缓存,但共享 L3 缓存和主存接口。
了解了处理器内部,你就会明白:高级语言(Python/Java)是在描述‘我想做什么’,而指令集(ISA)是在描述‘硬件能做什么’。编译器就是那个痛苦的翻译官,它必须把你的抽象逻辑,拆解成上面讲的取指、译码、执行的笨拙步骤。
指令的生命周期
我们将把之前学过的冯·诺依曼结构、总线、主存、I/O 和 CPU全部串联起来。
假设当前 CPU 的程序计数器 (PC)指向内存地址 0x0200,该地址存放着一条机器指令: ADD R1, [1000]
含义:取出内存地址 1000 里的数据,把它加到寄存器 R1 上,结果保存回 R1。
第一阶段:取指令 (Instruction Fetch)
PC -> MAR:控制器 (CU) 看到 PC 是 0x0200,将这个地址送入内存地址寄存器 (MAR)。
地址上总线:MAR 将 0x0200 电平信号打到地址总线上。
发出读命令:CU 通过控制总线发出 MEMORY_READ 信号。
内存响应:内存条看到地址 0x0200 和读信号,将该位置的二进制代码(即 ADD 指令本身)放到数据总线上。
指令入库:CPU 通过内存数据寄存器 (MDR)接收指令,并将其送入指令寄存器 (IR)。
译码:CU 分析 IR 中的位串,明白:“哦,这是要我去读地址 1000 的数据,然后和 R1 相加。”
步骤 1:送出数据地址 (Address Generation)
动作:CU 将指令中解析出的操作数地址 1000 送入MAR。
总线行为:地址总线上的信号瞬间变为 1000(二进制 …001111101000)。
控制信号:CU 再次拉低控制总线上的 READ 引脚,告诉内存:“我要读数据。”
步骤 2:主存读取 (Memory Access)
动作:主存芯片内部的解码器选中第 1000 行电容。
延迟:这里需要等待几十纳秒(CAS Latency)。
总线行为:内存将地址 1000 里的数据 5(二进制 …00000101)放到数据总线上。
步骤 3:数据暂存 (Data Buffering)
动作:CPU 的MDR侦测到数据总线上的电压变化,锁存数据 5。
内部传输:数据 5 通过 CPU 内部总线被送往ALU 的输入端 B。
步骤 4:准备另一操作数 (Register Read)
动作:CU 告诉通用寄存器组:“把 R1 的值给我。”
内部传输:R1 中的数据 10 被送往ALU 的输入端 A。
动作:CU 向 ALU 发出操作码 OP_ADD。
电路反应:ALU 内部的加法器电路(逻辑门)瞬间导通:
10 (00001010) + 5 (00000101) = 15 (00001111)
状态更新:ALU 计算出 15,同时因为结果不是 0,将状态寄存器的Zero Flag (ZF)设为 0。
动作:ALU 的输出结果 15 被通过内部总线送回通用寄存器组。
落袋为安:R1 的旧值 10 被新值 15 覆盖。
| 组件 |
在此案例中的角色 |
物理表现 |
| 控制器 (CU) |
|
就像交通指挥,不停切换开关(控制信号),决定数据流向哪里。
|
| 地址总线 |
|
先承载了 0x0200 (取指),后承载了 1000 (取数据)。
|
| 数据总线 |
|
|
| ALU |
|
|
| 寄存器 |
|
|
你看完这个过程,可能会觉得繁琐。但请记住,这一切都是在时钟信号(Clock)的驱动下严格同步进行的。
比如在 3GHz 的 CPU 上,上述的每一步可能只花 0.3 纳秒。
真正神奇的不是某一个部件,而是配合。如果内存慢了,CPU 就得空转等待(Stall);如果总线窄了,数据就得排队。高性能计算机的设计艺术,就是消除这些等待。