MEME:中国金融市场演化建模,达成盈利与稳定性双突破

摘要
现有量化金融方法多聚焦于个股预测或投资组合分配,却常忽略市场变动的深层驱动因素。本文提出一种逻辑驱动的全新视角,将金融市场重构为动态演进的“投资叙事生态系统”,并创新性引入MEME模型。该模型通过多智能体数据抽取模块转化多维度数据,运用高斯混合模型识别潜在市场共识,同时构建时间评估与动态对齐机制,精准追踪叙事模式的生命周期演变及盈利潜力。基于2023-2025年中国股票市场三个典型池的实证研究证实,MEME模型在性能上显著超越七个当前主流基准模型。通过消融实验、敏感性测试、生命周期案例解析及成本效益评估等多维度验证,充分证明其具备敏锐的市场共识识别能力与自适应调整能力,为构建基于可靠逻辑推演的投资组合提供有效方法论支撑。
简介
LLM技术在量化金融领域的应用价值日益凸显,其驱动的多智能体系统通过非结构化数据处理为投资决策提供了有力支撑。现有金融交易方法虽形成以资产预测为核心和以市场配置为导向的两大范式,但二者均止步于对象化建模,未能穿透市场波动的表象,解析其底层逻辑的演化规律。本文突破传统范式桎梏,提出逻辑推演视角的金融交易建模框架,创新性地将金融市场抽象为动态博弈的“投资逻辑生态体系”,并直面逻辑捕捉中数据混杂、逻辑畸变、信号稀疏及语义漂移等关键挑战。
为此,研究构建了MEME模型:通过多智能体协同的数据萃取引擎实现异构信息融合,运用高斯混合聚类算法解构隐性共识簇群;创新性嵌入时序评估模块与动态校准机制,实现逻辑噪声的智能过滤与模式生命周期的精准追踪。在沪深多组股票池的实证研究中,MEME模型在对比8个前沿基准模型时,展现出卓越的收益风险比与策略稳定性。进一步通过模块化消融分析、参数稳健性测试、样本外推验证及典型逻辑演化案例剖析,系统性证实了该框架对市场逻辑的深层解构能力与动态适配效能,为构建逻辑驱动的智能投资体系奠定了实证基础与理论支撑。
相关工作
以资产为中心的方法:
以资产为中心的研究聚焦于个体资产的精准预测与预测信号深度挖掘,通过遗传编程、强化学习等算法构建预测模型,生成具有解释性的预测表达式,并整合因子建模、时序依赖分析等技术手段。伴随大语言模型的发展,涌现出基于智能体的创新方法,如多模态数据融合分析与专家辩论机制。在阿尔法因子的挖掘中,智能体通过迭代优化算法与导航树搜索策略,探寻有效的预测公式。本文提出的方法论与资产中心研究形成显著差异:传统路径将资产视为孤立单元,直接通过特征映射预测价格变动;而MEME方法实现范式突破,从微观映射转向宏观逻辑推理,通过提取驱动资产联动的潜在投资论点,有效滤除资产级特异性噪声,从而提升逻辑推理的纯净度与可靠性。
以市场为中心的方法:
以市场为中心的研究立足股票池或投资组合层面,传统范式聚焦于投资组合的优化构建,涵盖协方差矩阵的动态预测、多维因子降维技术,以及运用强化学习动态调整资产配置权重。近期研究引入大语言模型整合股票池的多元信息,并探索多种机制以管理市场参与者间的复杂交互。本文框架在核心逻辑上与现有研究形成鲜明区分:视角层面,现有方法秉持对象化视角,将股票池视为静态资产集合;而本文采用逻辑驱动的动态分析框架,将市场诠释为潜在投资叙事的动态竞争场域。方法层面,传统研究侧重空间维度的资产配置优化,本文则聚焦时间维度的逻辑演化,通过追踪投资叙事的生命周期轨迹指导组合构建策略,而非单纯依赖特定市场状态下资产间的短暂相关性波动。
方法
MEME模型通过逻辑驱动范式实现每日投资组合的智能构建,其核心逻辑区别于传统量化方法。该模型将金融市场创新性建模为动态演化的“投资叙事生态体系”,以N只股票在T个交易日的日频数据为输入基础,单只股票每日数据涵盖基本面指标、新闻事件、技术信号等多元模态信息。其运作机制分为三个协同阶段:首先,通过多模态数据解析模块,从异构信息中深度萃取结构化的投资逻辑单元;其次,运用动态聚类算法对逻辑单元进行时序关联分析,追踪其演化轨迹并识别潜在的系统性推理模式;最终,基于历史数据的盈利效能评估,筛选具备稳定收益特征的推理模式,进而构建优化的投资组合。这一框架突破了传统方法的数据驱动局限,实现了从信息表层到逻辑深层的穿透式分析,为动态市场环境下的资产配置提供了更具解释性与适应性的解决方案。
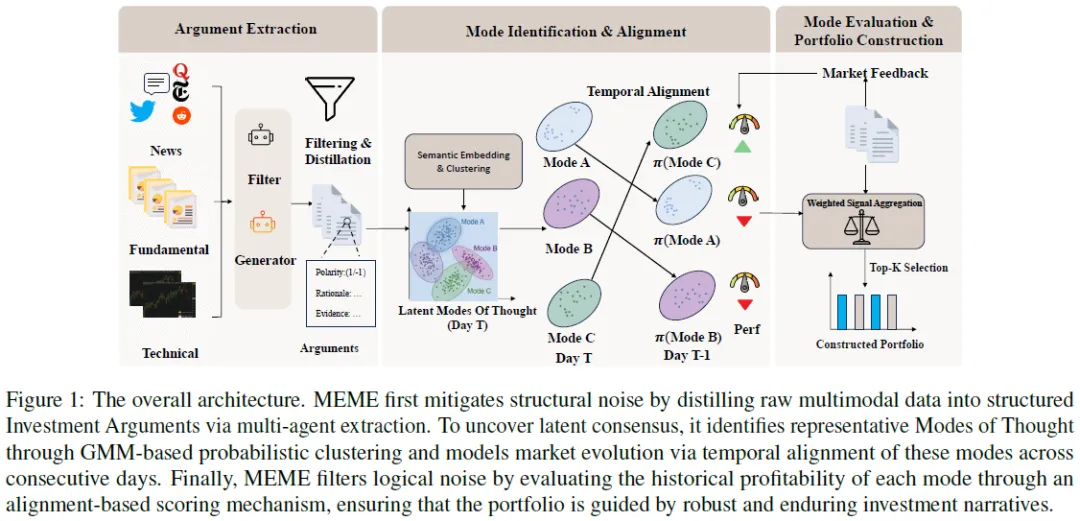
从噪声到结构
MEME模型的初始处理阶段致力于将混杂的未加工多源金融数据提炼为具有清晰逻辑框架的投资论点,以破解原始数据的异构性与高干扰性壁垒。通过构建多智能体协作框架应对低信噪比挑战,该过程采用双阶处理机制实现数据降噪与结构析出:
信息过滤:各模态的过滤代理处理原始数据,提取相关信息。
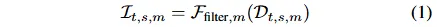
论点生成:整合各模态过滤信息,生成器代理合成结构化投资论点,每个论点含方向立场、分析理由和支持证据,方向立场用+1或-1表示。
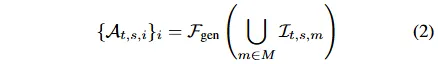
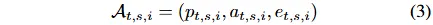
模式识别与对齐
提取个体论点,识别并追踪其隐含共识。针对信息碎片化、表述多样及关注点漂移问题,模型通过语义聚类解析每日潜在逻辑范式,再跨日追踪其演化轨迹,从碎片观点提炼系统性投资逻辑,为动态市场决策提供认知基础。
模式识别:从争论到潜在共识
用高斯混合模型(GMM)对每日论点嵌入集建模论点间共享逻辑,因其能处理市场主题重叠问题,为每个论点分配各模式的隶属概率,比刚性分类更能捕捉市场共识。
为每日每个论点生成语义表示,将论点基本原理与证据拼接,用编码器E编码成D维向量。
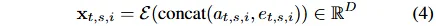
对每日论点嵌入集合应用高斯混合模型(GMM),定义当日 K 个模式,每个模式为高斯分布,同时计算论点属于各模式的后验概率。
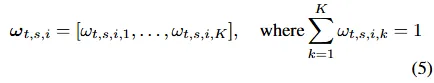
时间模式对齐:从快照到进化
为理解主题持久性,需跨时间连接识别模式,静态日分析因模式语义焦点会漂移而不足,可通过连接连续多天的相关模式解决。设图1图2分别为第t-1天和第t天的模式质心集,用线性分配算法求使匹配模式总语义漂移最小的排列π,以建立各模式的时间对应关系。
模式评价与组合构建
MEME 最后阶段评估各模式历史有效性,量化历史盈利能力,以该得分加权新信号生成未来投资组合股票排名。
交易日t收盘时评估t-1日所有模式表现,给出股票一日远期超额回报公式。
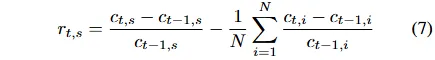
计算论点实现得分、各模式每日聚合得分,用指数移动平均更新长期表现得分,确保表现连续性。
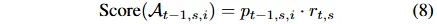
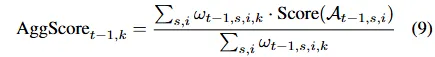
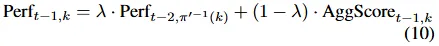
构建每日投资组合Wt,计算新论点与既定模式的对齐概率,以此加权模式长期表现得出新论点预测得分。
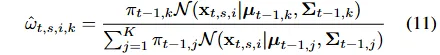
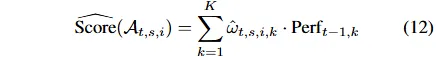
汇总论点得分得到每只股票的综合信号,根据信号向量排名采用 top – K 策略构建次日开盘投资组合。
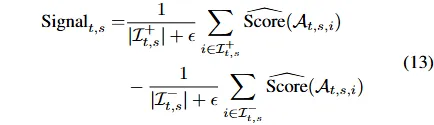
实验
实验设置
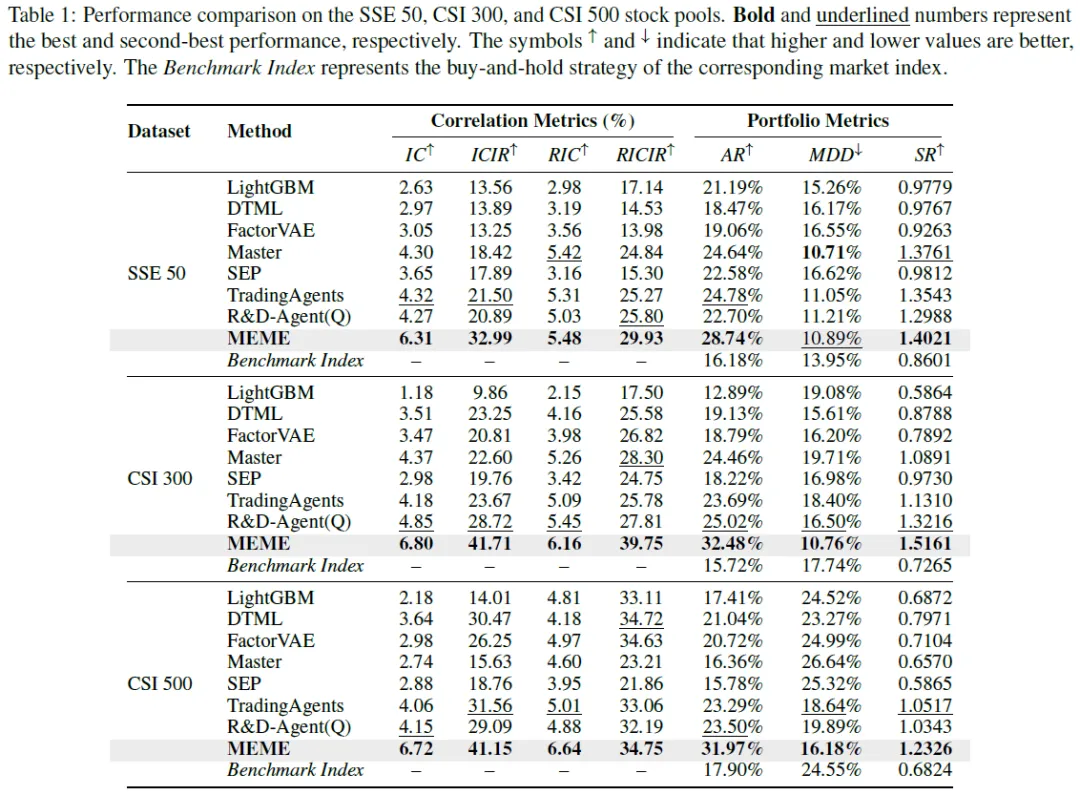
数据集:2023 Q4 – 2025 Q4 对 SSE 50、CSI 300、CSI 500 三个 A 股股票样本进行实验,期间涵盖多种市场风格转变。
性能指标:采用基于相关性(IC、ICIR 等)和基于投资组合(AR、MDD 等)两类指标评估 MEME 性能。
基线:将 MEME 与传统机器学习、深度学习、单资产和市场为中心的代理方法等多种基线对比。
实现细节:以 DeepSeek V3.1 为骨干大模型,Qwen3 Embedding – 8B 用于模式识别,设置相关参数,采用指数增强策略回测。
实验结果:2023 Q4 – 2025 Q3 实验表明,MEME 股票收益预测能力强,不同市场条件下稳定性更好。
结果
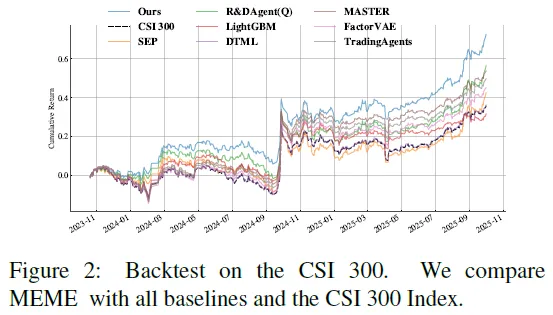
绘制沪深300完整回测曲线,图2显示MEME在多数回测期表现领先,在2024年初流动性危机和2025年4月贸易摩擦时低回撤,2025年中期牛市获良好回报,展现出较强稳健性。
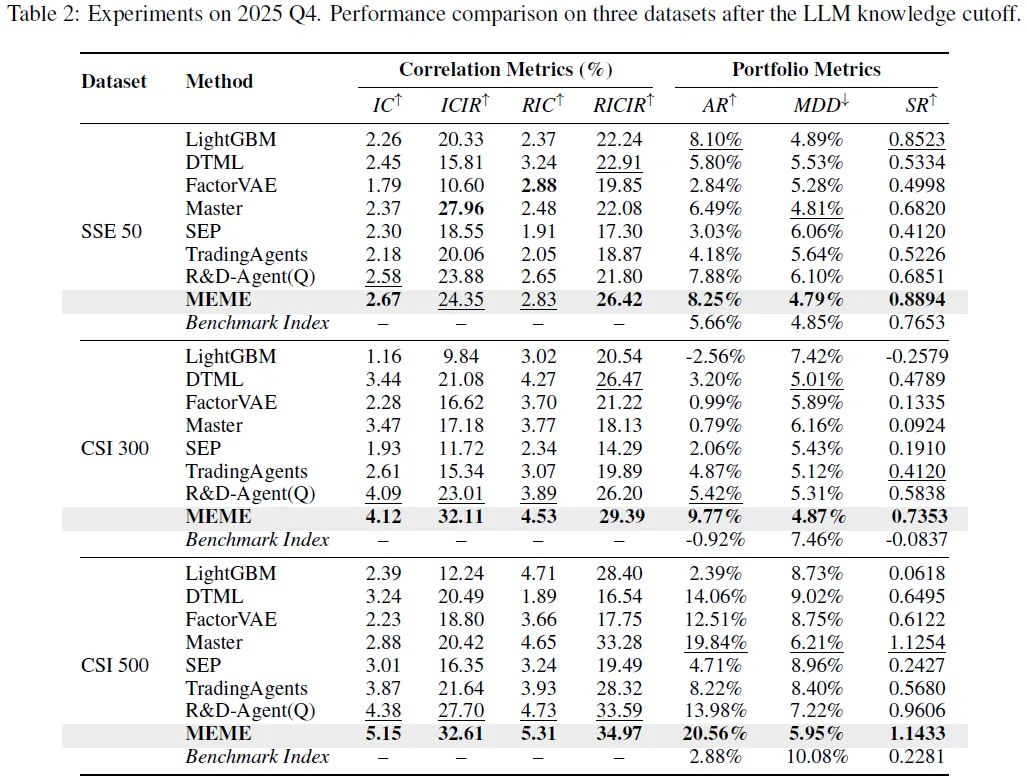
数据泄漏问题的实验研究
为检验MEME模型是否存在数据泄露风险,我们在LLM知识截止日期之后的2025年第四季度新数据上,对三个主流数据集进行了严格的样本外测试。表2的实验结果清晰地表明,MEME在各项关键指标上均显著超越了包括LightGBM、DTML及各类Agent在内的所有基线模型。
具体而言,在SSE 50数据集中,MEME实现了0.8894的夏普比率,优于次优的R&D-Agent(Q)(0.6851);在CSI 300数据集中,其年化收益率达到9.77%,大幅领先于其他方法;而在CSI 500数据集中,MEME更是取得了5.15%的信息系数和34.97%的风险调整后信息系数,全面领跑。这些结果有力地证明了MEME的卓越性能完全源于其独特的方法论设计,而非依赖于大语言模型训练语料中的潜在数据污染。
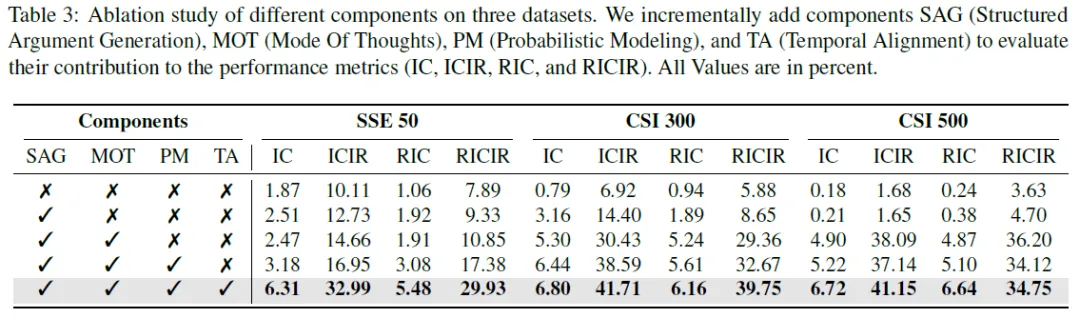
消融分析
消融研究通过增量添加组件,验证了MEME各模块的必要性。基线模型(无组件)性能最差,如CSI 500的IC仅0.18%、ICIR仅1.68%,凸显结构化分析的必要性。引入SAG后,小股票池(如CSI 300的IC从0.79%升至3.16%)表现提升,但大股票池(如CSI 500的ICIR微降至1.65%)效果有限,表明单纯结构化论点提取难以应对复杂噪声。加入MOT后,性能实现跃升,CSI 500的ICIR从1.65%激增至38.09%,验证了将论点聚类为推理模式的核心价值。用PM替代确定性聚类后,各指标进一步优化,证实了概率建模对模糊关系捕捉的有效性。最终添加TA形成完整模型,CSI 500的IC升至6.72%、ICIR达41.15%,证明时序对齐对思维模式生命周期建模的关键作用。
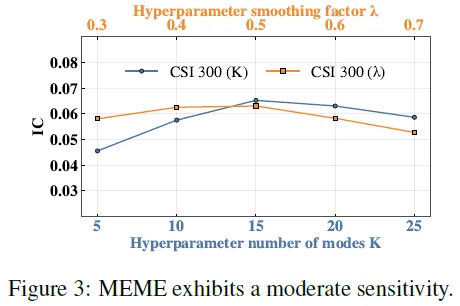
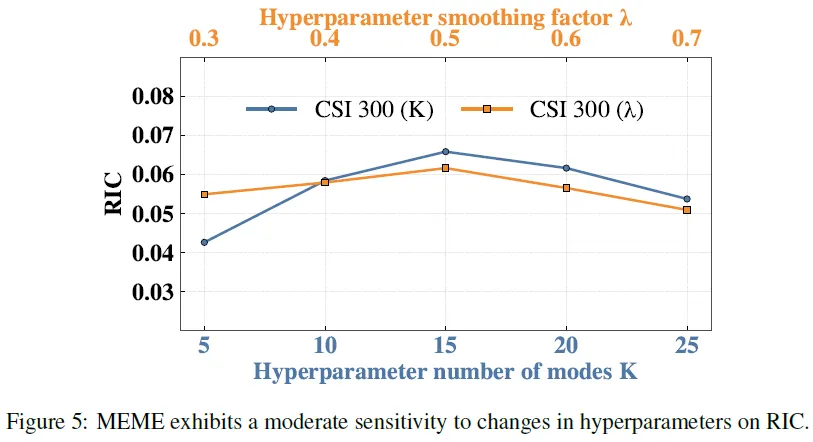
参数灵敏度分析
本研究基于CSI 300数据集,深入探究了MEME模型对核心超参数——模式数量K与平滑因子λ的敏感性。实验结果显示,该模型展现出卓越的鲁棒性,在K与λ的广泛取值区间内,各项性能指标均保持在较高水平,未出现剧烈震荡。
具体而言,当模式数量K设定过低时,模型性能出现下滑。这是因为过少的聚类中心迫使模型将语义迥异的投资逻辑强行归并为同一模式,导致特征混淆。同样,当平滑因子λ数值过大时,性能亦受到损害。此时模型过度依赖模式的长期历史表现,导致权重更新迟滞,难以敏锐捕捉思维模式预测能力的近期动态变化,从而降低了策略的时效性。
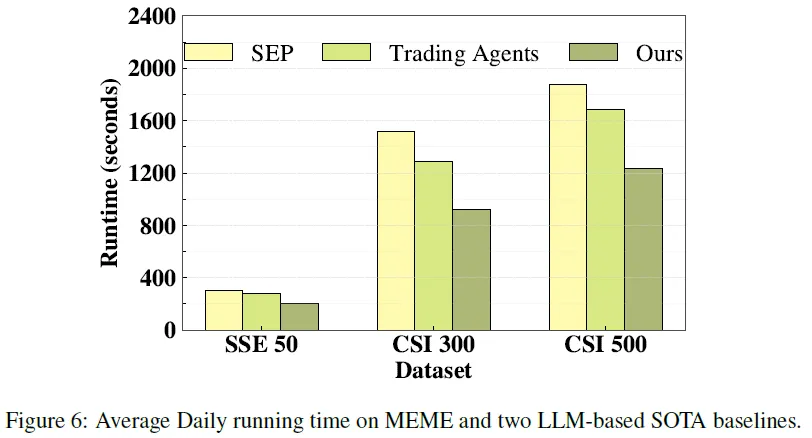
消耗时间分析
通过对比MEME模型与当前顶尖的LLM(大型语言模型)基线系统的日平均运行时间可见,MEME展现出显著的计算效率优势。其核心在于通过结构化参数化解析机制与噪声过滤模块,有效筛除非关键信息,减轻模型处理负担;同时,依托模式识别算法与跨资产-跨周期信息对齐框架,实现多维度金融数据的深度融合与逻辑关联,避免了LLM在显式推理过程中对海量冗余数据的重复解析与高成本迭代。这种设计使MEME在保持高性能的同时,大幅压缩了推理资源消耗,日均运行耗时显著低于传统LLM基线,验证了其通过结构化处理与信息精炼技术路径,在降低算力成本与时间成本方面的创新性与有效性。
总结
本文提出了一种创新的基于大语言模型的金融交易框架——MEME,该框架以策略驱动为核心方法论,通过动态解析、持续追踪及效果评估多维度投资逻辑的全生命周期演变规律,相较于传统竞品实现了效能与稳定性的双维度突破,并在多样化的市场场景中展现出卓越的鲁棒性与泛化能力,为复杂金融环境下的交易决策提供了更具适应性的技术范式。
关于我们
赋能每一个个体的“算力自由”,极量数科是一家专注于高性能算力普惠化的平台。
欢迎加入我们的交流群!扫描下方二维码即可进群,与更多同行、专家及爱好者实时互动。群内提供干货分享、热点探讨、资源对接等丰富内容,助您拓展人脉、碰撞灵感、获取行业动态。无论您是交流学习还是合作共创,这里都是您的理想平台!
