

一万亿市场的赌注:黄仁勋GTC 2026的"全栈AI"革命与Vera Rubin平台解析
引言:英伟达的第三次转身
2026年3月17日,英伟达创始人兼CEO黄仁勋在GTC(GPU Technology Conference)大会主旨演讲中,抛出了一个令人震撼的预测:到2027年,AI市场规模将达到1万亿美元。这一预测背后,并非简单的数字游戏,而是英伟达从图形计算厂商向"AI基础设施提供商"转型的第三次关键战略跃迁。
如果说第一次转型是从游戏显卡转向数据中心计算,第二次是从训练硬件转向推理加速,那么第三次则是从单一硬件供应商转向"全栈AI"生态主导者。这次转型的核心载体,正是黄仁勋在GTC 2026重磅发布的Vera Rubin平台——一个以发现暗物质的天文学家Vera Rubin命名的全新AI超级计算架构。
第一部分:Vera Rubin平台的技术架构重构
六芯片协同:从组件到系统的范式转变
Vera Rubin平台的革命性突破在于"极致协同设计"(Extreme Co-Design)理念。与传统数据中心将服务器视为独立计算节点的做法不同,Vera Rubin将整个机架视为一个统一的计算单元,通过六款深度协同的芯片构建了机架级AI超级计算机。
1. Rubin GPU:计算核心的代际飞跃
- 制程工艺
:采用台积电3nm工艺和CoWoS-L先进封装技术,晶体管数量达到3360亿个 - 架构升级
:第六代Tensor核心(NVFP4架构),支持从FP64到NVFP4的8位精度的动态精度调度 - 算力指标
:单卡推理算力达50 PFLOPS,训练算力35 PFLOPS - 显存系统
:搭载HBM4显存,带宽22 TB/s(是GB300 HBM3e的2.8倍),容量288GB - 设计理念
:不再追求单一指标最大化,而是通过架构优化实现"每瓦Token数"这一核心指标的大幅提升
2. Vera CPU:智能调度中枢的诞生
这是英伟达首次从"ARM公版魔改"升级为"全自研核心"的关键产品:
- 核心架构
:88个定制Olympus核心,支持176线程并发,采用"空间多线程"技术避免传统多线程的性能损耗 - 缓存系统
:配备162MB统一L3缓存,最大支持1.5 TB LPDDR5X内存,带宽1.2 TB/s - 安全特性
:补齐机架级机密计算能力,实现整机架算力的加密防护,满足企业级数据安全需求 - 角色定位
:从传统服务器的通用处理器转变为AI工作负载的智能调度中枢,负责动态分配计算资源、管理上下文、优化能耗
3. NVLink 6 Switch:机架内互联的极致优化
- 带宽指标
:单GPU双向带宽达3.6 TB/s,是第五代NVLink的3.6倍;单个交换机芯片提供28.8 TB/s总带宽 - 连接规模
:通过400Gbps SerDes技术实现传输速率翻倍,机架内72颗GPU构成统一计算域 - 拓扑结构
:采用全互联无阻塞拓扑,任意GPU间直连无延迟,消除了传统树状拓扑的路径差异 - 设计哲学
:将机架内通信优化到极致,确保跨GPU协同训练和推理的效率
4. ConnectX-9 SuperNIC:横向扩展的智能网卡
- 传输速率
:基于200Gbps PAM4 SerDes技术,网络带宽1.6 TB/s - 配置策略
:每个GPU配备2颗CX-9,提供对外总带宽3.2 TB/s - 协议支持
:支持InfiniBand和Ethernet双协议,允许企业根据现有网络架构灵活切换组网方案 - 智能卸载
:集成RDMA和网络虚拟化卸载功能,减轻CPU负担,提升AI工作负载的网络吞吐
5. BlueField-4 DPU:从协处理器到上下文记忆系统
BlueField-4的定位发生了质的变化:
- 核心升级
:核心数从BlueField-3的16个跃升至64个Grace CPU核心 - 内存扩展
:内存升级为128GB LPDDR5X,集成ConnectX-9模块 - 功能重构
:从传统"协处理器"升级为"AI上下文记忆系统管理器" - 共享内存池
:每个机架内构建高达150TB共享、持久、高速的上下文内存池 - 动态分配
:为每个GPU动态分配高达16TB专用上下文空间,突破长上下文推理瓶颈
6. Spectrum-6以太网交换机:共封装光学的商用落地
- 技术突破
:首次集成共封装光学(CPO)技术,将光模块直接集成在芯片上 - 能效优化
:功耗降低约70%,与台积电共同开发制造工艺 - 端口配置
:支持512个800G以太网端口,总带宽409.6 TB/s - 部署优势
:将传统需要几十个机柜的光纤设备压缩到单个交换机,大幅降低数据中心占地面积和能耗
NVL72机架:RAS架构的极致设计
Vera Rubin NVL72基于第三代MGX机架设计,将可靠性和可维护性作为核心架构要求:
模块化无缆线设计
-
计算托盘、NVLink交换机托盘以及电源和冷却基础设施全部模块化 -
支持热插拔,现场更换无需排空机架或中断运行中的工作负载 -
消除了托盘内部众多手动的PCIe、网络和管理连接,通过通用快速接头支持远高于前几代产品的流速
智能故障隔离
-
系统能隔离故障、重新路由流量并持续执行工作负载 -
在机架规模上实现零计划停机 -
通过冗余设计和快速切换机制,确保AI工作负载的连续性
预测性维护
-
RAS引擎实时监控硬件健康状态 -
通过AI驱动的预测性管理提前识别潜在故障 -
最大限度减少计划外停机时间,满足企业级7×24小时运营需求
液冷与CPO:从能耗优化到架构创新
100%液冷架构
-
支持45°C进水温度,无需使用高能耗的冷水机组(Chiller) -
仅靠室外自然冷却即可维持运行,大幅降低PUE(数据中心能效比) -
数据中心PUE可降至1.1以下,电力消耗降低6%以上
共封装光学(CPO)的意义
-
CPO技术的商用标志着数据中心互联架构的深刻变革 -
光电子集成取代了传统的光电转换,消除了信号转换损耗 -
与台积电的合作表明英伟达已深度介入芯片制造工艺的定制化开发
非对称分离推理架构:GPU与LPU的协同计算
这是与Groq LPU协同工作的核心创新:
- 分工明确
:Vera Rubin负责Prefill(预填充),处理计算密集型任务,利用海量计算和显存优势;Groq LPU负责Decode(解码),针对推理这一单一工作负载优化 - 技术互补
:GPU擅长大规模并行计算,LPU专注低延迟Token生成 - 协同计算
:GPU和LPU共同计算AI模型每一层,显著提升解码性能 - 架构效果
:每兆瓦推理吞吐量最高提升35倍,为万亿参数模型带来最高10倍营收潜力
第二部分:AI工厂的三大变革
黄仁勋在演讲中明确提出,AI领域正在经历三大深刻变革,这些变革将重塑整个AI产业的技术路线和商业模式。
变革一:从训练到推理,AI工厂模式重塑数据中心经济
推理需求的爆发式增长
-
黄仁勋预测到2027年,AI市场中推理工作负载将占据主导地位,占比超过70% -
这一预测与传统云计算模型形成鲜明对比,传统模型中计算资源主要用于数据处理和存储 -
推理需求的爆发标志着AI从"训练为主"向"应用为主"的拐点到来
AI工厂的经济模型
-
AI工厂模式将数据中心从"通用计算设施"转变为"AI算力生产设施" -
通过高度优化的硬件架构和软件栈,大幅降低单位Token的推理成本 -
英伟达声称,Vera Rubin平台可将AI推理成本压缩至GB300平台的1/10 -
这意味着企业可以用更低的成本部署更大规模的AI应用,推动AI的大规模商业化落地
每瓦Token数的战略意义
-
黄仁勋首次将"每瓦Token数"作为核心指标提出,这一指标的重视反映了AI产业从追求峰值性能到追求能效比的转变 -
对于超大规模数据中心而言,能耗成本已成为制约AI算力部署的关键因素 -
Vera Rubin通过架构优化和能效提升,将每瓦Token吞吐量提升50倍,大幅降低运营成本
变革二:智能体系统推动软件行业转型
SaaS向AaaS的演进
-
黄仁勋明确提出,软件行业正在从SaaS(Software as a Service)向AaaS(AI as a Service)转型 -
传统SaaS模型中,软件的功能和用户体验由开发者预先设计 -
AaaS模型中,AI智能体能够根据用户需求动态生成解决方案,软件的价值从功能提供转向智能决策
智能体系统的核心特征
-
自主性:智能体能够自主感知环境、理解需求、制定执行方案 -
学习能力:通过持续交互不断优化决策质量 -
多模态交互:支持文本、语音、图像等多种交互方式 -
工具调用:智能体能够调用外部API、数据库等工具完成复杂任务
Nemotron联盟与开源生态
-
英伟达成立Nemotron联盟,推动开放模型生态的发展 -
推出开源智能体软件套件,降低开发者构建智能体系统的门槛 -
合作厂商包括比亚迪、日产、吉利、现代汽车、迪士尼等,覆盖汽车、娱乐、制造等多个行业
变革三:物理AI与机器人时代的到来
从数字生成到物理模拟
-
黄仁勋强调,AI的下一个前沿是"物理AI"——即能够理解和模拟物理世界的AI系统 -
传统生成式AI主要处理文本、图像、视频等数字内容 -
物理AI则需要理解重力、摩擦、碰撞、材料特性等物理定律
具身智能的突破
-
英伟达推出Project GR00T通用机器人基础模型,支持多种机器人平台 -
通过Omniverse平台构建高保真数字孪生环境,让机器人在虚拟世界中接受训练 -
训练完成后,将"大脑"下载到边缘设备(如Jetson T4000),在物理世界中执行任务
数字孪生的工业应用
-
宝马、比亚迪等汽车制造商采用Omniverse构建数字工厂 -
在虚拟环境中优化生产线、测试生产流程,大幅降低试错成本 -
实际数据显示,设备故障率降低22%,产能提升18%
第三部分:Vera Rubin平台的应用场景与案例分析
场景一:具身智能与机器人训练
核心挑战
机器人领域的"莫拉维克悖论"——让计算机下围棋很难,但让它像一岁孩子一样走路更难。以前的机器人"大脑"和"身体"分离,代码写好逻辑后,身体在物理世界遇到的每一个坑洼、每一次打滑都是无法预编程的边缘情况。
Vera Rubin解决方案
- 云端大脑
:在Vera Rubin构建的"数字孪生世界"里,机器人可以以几千倍于现实时间的速度进行训练 - 虚拟练兵场
:利用Isaac Sim和Isaac Lab,机器人在虚拟世界里摔倒一亿次,学会如何在各种材质地面上行走,学会如何抓取鸡蛋而不捏碎 - 边缘躯体
:训练好的"大脑"被下载到Jetson T4000边缘设备,实时执行物理世界中的任务
具体案例
- Agility Robotics的Digit机器人
:通过Isaac Lab框架强化学习,优化步态控制和抗干扰能力,在颠簸路面稳定行走 - 迪士尼雪宝机器人
:完全由英伟达物理AI全家桶构建,从虚拟世界训练获得物理躯体,能够在真实环境中与人类互动
场景二:数字生物学与药物研发
行业痛点
传统新药研发遵循"双十定律"(10年、10亿美金),需要像碰运气一样在湿实验室里筛选分子。平均需要筛选数千个化合物才能找到一个有效的药物候选分子,开发周期长、成本高、失败率高。
Vera Rubin解决方案
- BioNeMo框架
:模拟蛋白质的折叠结构,模拟药物分子与靶点的结合过程 - 微观物理模拟
:在微观层面进行物理计算,而非简单"画"出来 - 计算速度提升
:AI加速的偏微分方程求解器将计算速度提升数万倍,实现"实时模拟" - 个性化医疗
:根据个人基因序列,在几小时内算出并合成专属药物将成为可能
具体案例
- 礼来制药
:计划用Vera Rubin构建包含1000颗Blackwell Ultra GPU的药物研发超算,预计将药物筛选周期从6个月缩短至2周 - DeepMind的AlphaFold
:虽然不是Vera Rubin平台,但其蛋白质折叠预测的成功展示了AI在生命科学领域的巨大潜力,Vera Rubin将进一步加速这一进程
场景三:工业数字孪生
传统制造模式的困境
制造业最昂贵的是"试错"——造一辆原型车撞毁测试,造一条生产线发现流程不跑通,成本巨大。传统的数字化改造更多停留在数据采集和可视化的层面,无法真正预测物理系统的行为。
Vera Rubin解决方案
- 1:1数字工厂
:在虚拟世界里完全还原真实物理工厂,包括设备布局、工艺流程、物料流转等 - 物理定律仿真
:每一颗螺丝的扭矩、每一条传送带的速度都遵循物理定律,模拟结果高度可信 - 无限回滚
:产品经理和工程师可以在虚拟世界里把工厂"开"一万遍,把所有BUG修完,再在现实世界动土
具体案例
- 宝马慕尼黑工厂
:用Omniverse数字孪生改造3条智能手机组装线,设备故障率降低22%,产能提升18% - 富士康郑州工厂
:Omniverse平台改造,验证产线设计,实际投产时问题减少80% - 特斯拉Gigafactory
:通过数字孪生优化生产布局,将生产线调整时间从数周缩短至数天
场景四:自动驾驶与Robotaxi
技术挑战
自动驾驶需要实时处理摄像头、雷达、激光雷达等多源传感器数据,并在毫秒级内做出安全决策。系统需要能够在各种极端天气、复杂路况下稳定运行,对算力和延迟都有极高要求。
Vera Rubin解决方案
- Alpamayo全栈方案
:100亿参数VLA模型+AlpaSim开源仿真+1700小时物理AI数据集 - 多模态数据融合
:图像、语音、文本等多模态数据直接在引擎内完成融合计算,避免跨单元数据传输的延迟损耗 - 环境感知推理延迟较Blackwell架构降低40%
:为车辆决策提供更充足的响应时间
具体案例
- 比亚迪、日产、吉利、现代
:加盟英伟达robotaxi ready平台,每年合计生产约1800万辆汽车 - Uber
:合作开发L4级自动驾驶平台DRIVE AGX Hyperion 10,计划2027年部署10万辆自动驾驶出租车 - 梅赛德斯-奔驰CLA
:首款搭载Alpamayo系统的乘用车,AI定义驾驶功能已获EuroNCAP五星安全评级
场景五:6G通信与边缘AI
未来网络的演进方向
未来通信网络不仅传输信号,还需要作为边缘AI推理中心,实时处理工业自动化、AR/VR渲染等任务。6G网络将深度集成AI能力,实现"通信-计算融合"的新型架构。
Vera Rubin解决方案
- 诺基亚10亿美元战略合作
:推出支持6G的NVIDIA Arc Aerial RAN Computer(ARC)平台 - 智能基站
:根据天气、用户密度、信号干扰实时调整发射功率,频谱效率提升30%以上,同时降低15%能耗 - 边缘计算
:直接在基站运行工业自动化控制、低延迟云游戏、AR/VR渲染等任务
具体案例
- T-Mobile
:首个测试方,计划2026年启动6G实地验证 - 远程手术
:医生操作指令可通过基站边缘计算实时反馈,延迟控制在毫秒级
场景六:科学计算与宇宙探索
科学计算的新需求
求解复杂的物理方程(如气候模拟、天体物理)需要天文数字般的计算资源。传统超级计算难以满足日益增长的科学计算需求,特别是在实时模拟和多尺度建模方面。
Vera Rubin解决方案
- Earth-2气候AI模型
:根据流体力学方程计算水分子运动轨迹、热力交换和相变过程 - 天文数据处理
:Vera C.鲁宾天文台每晚产生20T数据,触发多达1000万次实时警报 - 多学科应用
:从材料科学到核物理,从天体物理到量子化学,覆盖广泛的科学计算领域
具体案例
- 美国洛斯阿拉莫斯国家实验室
:确定将Vera Rubin用于"Mission"和"Vision"两台超级计算机,承担国家安全任务与开放科研 - CERN(欧洲核子研究中心)
:利用Vera Rubin处理大型强子对撞机产生的海量数据
第四部分:性能对比与前代差异
与GB300 NVL72相比的代际提升
|
|
|
|
|
|---|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
实际工作负载性能对比
GPT-4级别(1.76万亿参数)大模型训练
-
GB300 NVL72:约22天 -
Vera Rubin NVL72:约9天(效率提升60%) -
意味着相同时间内可以完成2.5倍的模型训练迭代,大幅加速AI研发周期
GPT-5级别(5万亿参数)大模型训练
-
GB300 NVL72:约65天 -
Vera Rubin NVL72:约26天(效率提升60%) -
将超大模型的训练周期从两个月缩短到一个月,使企业能够更快地推出下一代AI产品
实时LLM推理
-
相比Hopper架构:30倍性能提升 -
相比GB300 NVL72:5倍性能提升 -
单位Token成本降低90%,使得大规模AI应用部署在经济上可行
自动驾驶环境感知推理
-
延迟较Blackwell架构降低40% -
响应时间从150ms降至90ms以下 -
为L4级自动驾驶提供了足够的安全边际,支持更复杂的场景理解
能效与部署效率提升
能效优化
-
45℃温水冷却无需制冷机组,节省6%电力消耗 -
CPO技术降低光互迟能耗70% -
每瓦Token吞吐量提升50倍,大幅降低运营成本
部署效率
-
单节点组装时间从2小时缩短至10分钟 -
维护效率提升18倍,热插拔设计无需停机维护 -
冷板数量减少67%,液冷架构简化了部署复杂度
可靠性提升
-
系统年停机时间减少90% -
预测性维护功能大幅减少故障发生率 -
RAS架构满足企业级7×24小时运营需求
第五部分:商业模式与成本结构分析
单机BOM成本变化
尽管Vera Rubin在性能和能效上有显著提升,但硬件成本也有明显增长:
|
|
|
|
|
|---|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 总成本 | 144万美元 | 300万美元 | +108% |
全生命周期成本优化
尽管硬件成本翻倍,但从全生命周期成本看,优化更为显著:
部署环节
-
单节点组装时间从2小时缩短至10分钟,大幅降低部署人力成本 -
维护效率提升18倍,热插拔设计无需停机维护 -
冷板数量减少67%,液冷架构简化了部署复杂度
运维环节
-
45℃温水冷却无需制冷机组,节省6%电力消耗 -
系统年停机时间减少90%,减少业务中断损失 -
预测性维护功能大幅减少故障发生率,降低维修成本
算力效率
-
训练相同模型GPU用量减少75%,周期缩短62.5% -
推理效率提升5倍,单位Token成本下降90% -
这意味着虽然硬件成本更高,但单位算力的TCO(总体拥有成本)实际下降
商业模式的战略调整
从卖GPU到卖AI工厂
-
英伟达不再仅仅销售GPU芯片,而是提供从芯片到软件栈的完整AI解决方案 -
通过软硬件深度整合,构建难以复制的生态壁垒 -
客户购买的不是硬件,而是"AI生产力"
云服务模式的拓展
-
与微软、亚马逊、谷歌等云厂商深度合作,推出基于Vera Rubin的AI云服务 -
企业无需自行采购和维护硬件,即可获得世界级的AI算力 -
这降低了AI应用的门槛,推动了AI技术的普及
按使用量计费的新模式
-
英伟达开始探索按"Token使用量"计费的新模式 -
客户根据实际使用量付费,而非按硬件规格付费 -
这种模式更符合AI应用的实际需求,降低了客户的风险
第六部分:对全球AI产业链的重构影响
对算力供应商的影响
AMD和英特尔的压力
-
英伟达的全栈布局使得单一硬件供应商难以竞争 -
AMD虽然在GPU领域追赶迅速,但缺乏英伟达的软件栈优势 -
英特尔虽然在CPU领域有优势,但在AI专用计算方面落后
专用加速器的挑战
-
Groq LPU等专用推理加速器虽然效率高,但通用性受限 -
英伟达通过与Groq合作,将专用加速器的优势整合到自己的平台中 -
这种合作共赢的模式避免了恶性竞争,推动了整个行业的发展
对云计算厂商的影响
云服务商的战略选择
-
微软、亚马逊、谷歌等云厂商面临战略抉择:自研还是采购 -
自研需要巨额投入,但可以降低对英伟达的依赖 -
采购英伟达方案可以快速获得领先技术,但长期可能受制于人
边缘计算的竞争
-
随着Vera Rubin平台向边缘设备延伸,云服务商的垄断地位受到挑战 -
企业可以在边缘节点直接运行AI应用,减少对云端算力的依赖 -
这将推动云计算向"云-边-端"协同的新架构演进
对应用企业的影响
AI应用的门槛降低
-
单位Token成本下降90%,使得中小型企业也能负担AI应用 -
英伟达的开源生态(如Nemotron联盟)降低了开发者门槛 -
AI应用将从大型科技企业向更广泛的企业群体扩散
AI应用的场景拓展
-
物理AI的突破使得AI从虚拟世界走向物理世界 -
制造、医疗、交通、能源等传统行业将迎来AI应用的爆发 -
这将催生新的商业模式和产业形态
对开发者的影响
开发模式的转变
-
从传统的"模型训练-应用部署"模式转向"智能体构建-场景适配"模式 -
开发者需要掌握多模态交互、工具调用、知识管理等新技能 -
英伟达的软件栈(如CUDA-X、BioNeMo、Isaac)为开发者提供了强大的工具支持
开源生态的重要性
-
英伟达通过开源(如Nemotron联盟)构建了庞大的开发者社区 -
开源生态加速了技术创新和应用落地 -
但开源并不意味着免费,英伟达通过硬件销售和云服务实现商业化
第七部分:未来趋势与战略建议
英伟达的未来优势与挑战
优势
- 技术领先优势
:Vera Rubin平台在性能和能效上的代际优势短期内难以超越 - 生态壁垒
:CUDA-X软件栈的深度绑定使得第三方开发者难以迁移 - 全栈能力
:从芯片到软件到解决方案的完整布局形成了难以复制的竞争力
挑战
- 反垄断风险
:随着英伟达在AI基础设施领域的垄断地位加强,反垄断监管风险增加 - 地缘政治风险
:中美科技竞争可能限制英伟达在某些市场的业务 - 技术迭代风险
:AI技术发展迅速,新的技术路线可能颠覆现有格局
对企业的战略建议
大型科技企业
-
短期内仍需依赖英伟达的硬件和软件栈 -
长期应考虑自研核心组件,降低对英伟达的依赖 -
积极参与英伟达的开源生态,保持技术敏感度
中小型企业
-
直接采用英伟达的云服务,降低技术门槛 -
专注于特定行业场景的AI应用,而非底层技术 -
与英伟达生态中的合作伙伴建立合作关系
传统行业企业
-
尽快启动AI应用试点,积累经验 -
关注物理AI在本行业的应用潜力 -
通过数字孪生等新技术优化业务流程
对开发者的职业建议
技能升级
-
掌握多模态AI开发技能,不局限于文本或图像 -
学习物理AI相关技术,如机器人控制、数字孪生等 -
熟悉英伟达的软件栈和开发工具
职业方向选择
-
AI应用开发:专注于特定行业的AI应用落地 -
AI平台工程:构建和维护AI基础设施 -
AI产品经理:连接技术与业务需求
开源参与
-
积极参与英伟达的开源项目 -
为开源社区贡献代码和经验 -
通过开源项目建立个人影响力
结论:从"卖铁锹"到"卖AI工厂"的战略跃迁
Vera Rubin平台的发布,标志着英伟达从"卖铁锹"(GPU)向"卖AI工厂"(完整技术栈)的战略跃迁。这一跃迁的背后,是英伟达对AI产业发展趋势的深刻洞察和前瞻布局。
其命名——以发现暗物质的天文学家Vera Rubin命名——蕴含深刻隐喻:现有的互联网数据只是可见宇宙的5%,而剩下的95%(物理世界的运行规律、生物分子化学反应、复杂动力学特征)才是等待AI去发现的"暗物质"。
这套架构不是为了让你更快地生成小红书文案,而是为了计算宇宙设计的。它的核心使命是支撑NVIDIA Omniverse和Earth-2等平台进行大规模物理模拟,把AI从"生成虚拟内容"推向"模拟物理世界"的新纪元。
对于企业和开发者而言,这意味着AI的应用边界正在被彻底重塑——从数字世界到物理世界,从文本生成到物理仿真,从辅助工具到自主智能体。未来的竞争将不再是"谁的模型参数更多",而是"谁的AI工厂更高效、谁能更快地把智能部署到物理世界"。
这已经不再是技术迭代,而是一场工业革命的开端。一万亿美元的AI市场,仅仅是这场革命的起点。
注:本文基于英伟达GTC 2026演讲及相关技术文档整理,部分数据和案例来自公开报道。随着技术发展和市场变化,部分预测可能需要根据实际情况调整。
免责声明:本报告仅供参考,不构成任何投资建议。投资者应根据自身风险承受能力和投资目标做出理性决策。
炒股迷茫,如何应对
想要成为股市赢家,加入我们!专业炒股培训,实战派讲师亲授,跟随经济周期,助你掌握盈利技巧。投顾服务,一对一策略指导,把握市场脉搏。名额有限,加微信:xiangchirou咨询,教你如何解读财富密码!
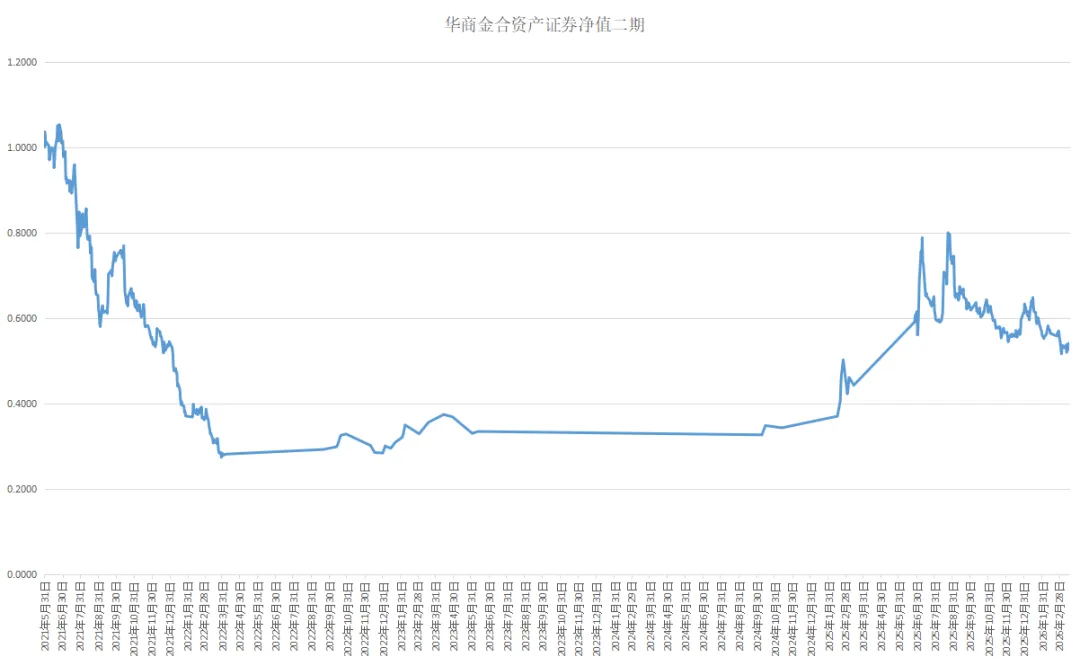
华商金合资产价值投资组合
华商金合资产净值以基金净值数据模式,采用基金净值走势图进行公示,以价值投资为主。目前持仓方向:数字经济。
评论