

【广告营销Agent实战10】流式响应的坑与解决方案
🐛 流式响应看起来简单,实际上坑很多。最常见的就是中文乱码问题,这篇聊聊我们踩过的坑和解决方案。
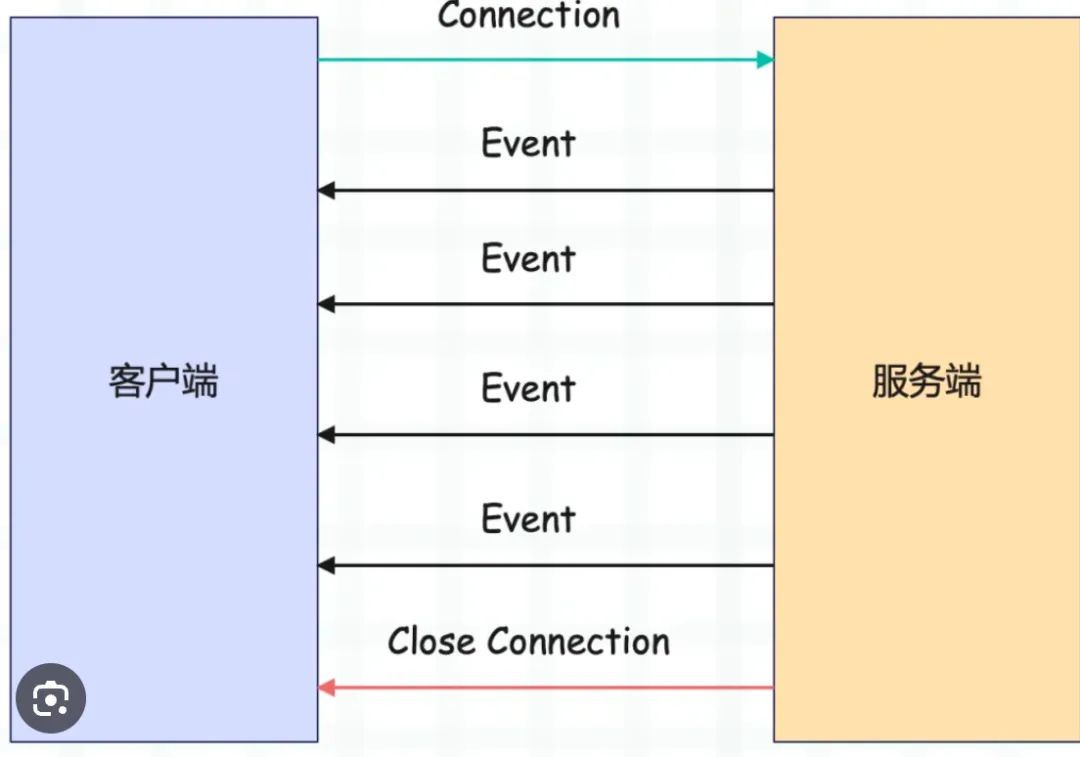
问题现象
坑1:中文字符乱码
流式输出时,中文字符被截断,显示成 �
用户看到的:
"上周的ROI是1.�5,也就是说每投�1元..."
坑2:消息截断
长消息传输到一半就断了,后面的内容丢失。
坑3:流式中断
网络抖动或超时导致 SSE 连接断开,用户体验很差。
根因分析
UTF-8 多字节字符问题
UTF-8 编码中,中文字符占 3 个字节。如果在字符中间截断,就会出现乱码。
// 错误示例 content := "上周的ROI" for i := 0; i < len(content); i++ { fmt.Fprint(w, string(content[i])) // ❌ 按字节截断 w.(http.Flusher).Flush() }正确的做法是按 Rune(字符)截断:
// 正确示例 content := "上周的ROI" runes := []rune(content) for _, r := range runes { fmt.Fprint(w, string(r)) // ✓ 按字符截断 w.(http.Flusher).Flush() }
SSE 协议规范
SSE 要求每条消息以 \n\n 结尾,格式必须严格遵守:
data: {"type":"content","content":"你好"}\n\n解决方案
方案1:UTF-8 边界检测
func writeUTF8Safe(w io.Writer, data []byte) error { // 检查最后几个字节是否是完整的 UTF-8 字符 validLen := len(data) for i := len(data) - 1; i >= 0 && i >= len(data)-4; i-- { if utf8.RuneStart(data[i]) { // 检查从这里开始是否是完整字符 r, size := utf8.DecodeRune(data[i:]) if r == utf8.RuneError && size == 1 { // 不完整,截断到这里 validLen = i break } break } } _, err := w.Write(data[:validLen]) return err }方案2:缓冲区管理
type StreamWriter struct { w http.ResponseWriter buffer []byte } func(sw *StreamWriter) Write(data []byte) error { sw.buffer = append(sw.buffer, data...) // 找到最后一个完整的 UTF-8 字符边界 validLen := 0 for i := 0; i < len(sw.buffer); { r, size := utf8.DecodeRune(sw.buffer[i:]) if r == utf8.RuneError { break } validLen = i + size i += size } if validLen > 0 { // 发送完整的字符 sw.w.Write(sw.buffer[:validLen]) sw.w.(http.Flusher).Flush() // 保留未完成的字节 sw.buffer = sw.buffer[validLen:] } return nil }方案3:错误恢复机制
前端检测到乱码时,自动重连:
const useStreamChat = () => { const [retryCount, setRetryCount] = useState(0); const connect = () => { const eventSource = new EventSource(url); eventSource.onmessage = (e) => { try { const data = JSON.parse(e.data); // 检测乱码 if (containsGarbledText(data.content)) { console.warn('检测到乱码,重连...'); eventSource.close(); if (retryCount < 3) { setTimeout(() => { setRetryCount(retryCount + 1); connect(); }, 1000); } } else { handleMessage(data); } } catch (err) { console.error('解析失败', err); } }; eventSource.onerror = () => { eventSource.close(); // 自动重连 if (retryCount < 3) { setTimeout(() => { setRetryCount(retryCount + 1); connect(); }, 2000); } }; }; return { connect }; };性能优化
1. 批量发送
不要每个字符都 Flush,积累一定量再发送:
const BATCH_SIZE = 10 // 每10个字符发送一次 func streamResponse(w http.ResponseWriter, content string) { runes := []rune(content) buffer := make([]rune, 0, BATCH_SIZE) for _, r := range runes { buffer = append(buffer, r) if len(buffer) >= BATCH_SIZE { fmt.Fprint(w, string(buffer)) w.(http.Flusher).Flush() buffer = buffer[:0] } } // 发送剩余内容 if len(buffer) > 0 { fmt.Fprint(w, string(buffer)) w.(http.Flusher).Flush() } }2. 超时控制
func streamWithTimeout(w http.ResponseWriter, content string, timeout time.Duration) error { ctx, cancel := context.WithTimeout(context.Background(), timeout) defer cancel() done := make(chan error, 1) go func() { done <- streamResponse(w, content) }() select { case err := <-done: return err case <-ctx.Done(): return fmt.Errorf("stream timeout") } }
测试验证
编写测试用例验证各种边界情况:
funcTestUTF8Streaming(t *testing.T) { tests := []struct { name string input string wantErr bool }{ {"纯中文", "你好世界", false}, {"中英混合", "Hello世界", false}, {"特殊字符", "😀🎉", false}, {"长文本", strings.Repeat("测试", 1000), false}, } for _, tt := range tests { t.Run(tt.name, func(t *testing.T) { // 测试流式输出 err := streamTest(tt.input) if (err != nil) != tt.wantErr { t.Errorf("got error = %v, want %v", err, tt.wantErr) } }) } }总结
核心要点:
1. UTF-8 边界 - 按 Rune 而不是 byte 处理
2. 缓冲区管理 - 保留不完整的字节
3. 错误恢复 - 前端自动重连
4. 性能优化 - 批量发送、超时控制
下一篇聊 Agent 路由优化,如何提升意图识别的准确率。
📖 广告营销 AI Agent 开发全记录 - 第10篇
作者:树林子有理想 | 2026年4月
上一篇:思考过程可视化
下一篇:Agent 路由优化
树
树林子有理想
一个有想法,爱思考,爱折腾,爱生活,喜欢探索的技术人。
📮 公众号:职场经历与人生感悟
💬 如果想进一步交流,欢迎加好友
评论