中国大模型霸榜,不是营销侥幸,是突围!
中国大模型霸榜全球 API 平台:不是营销侥幸,是算力突围与市场必然
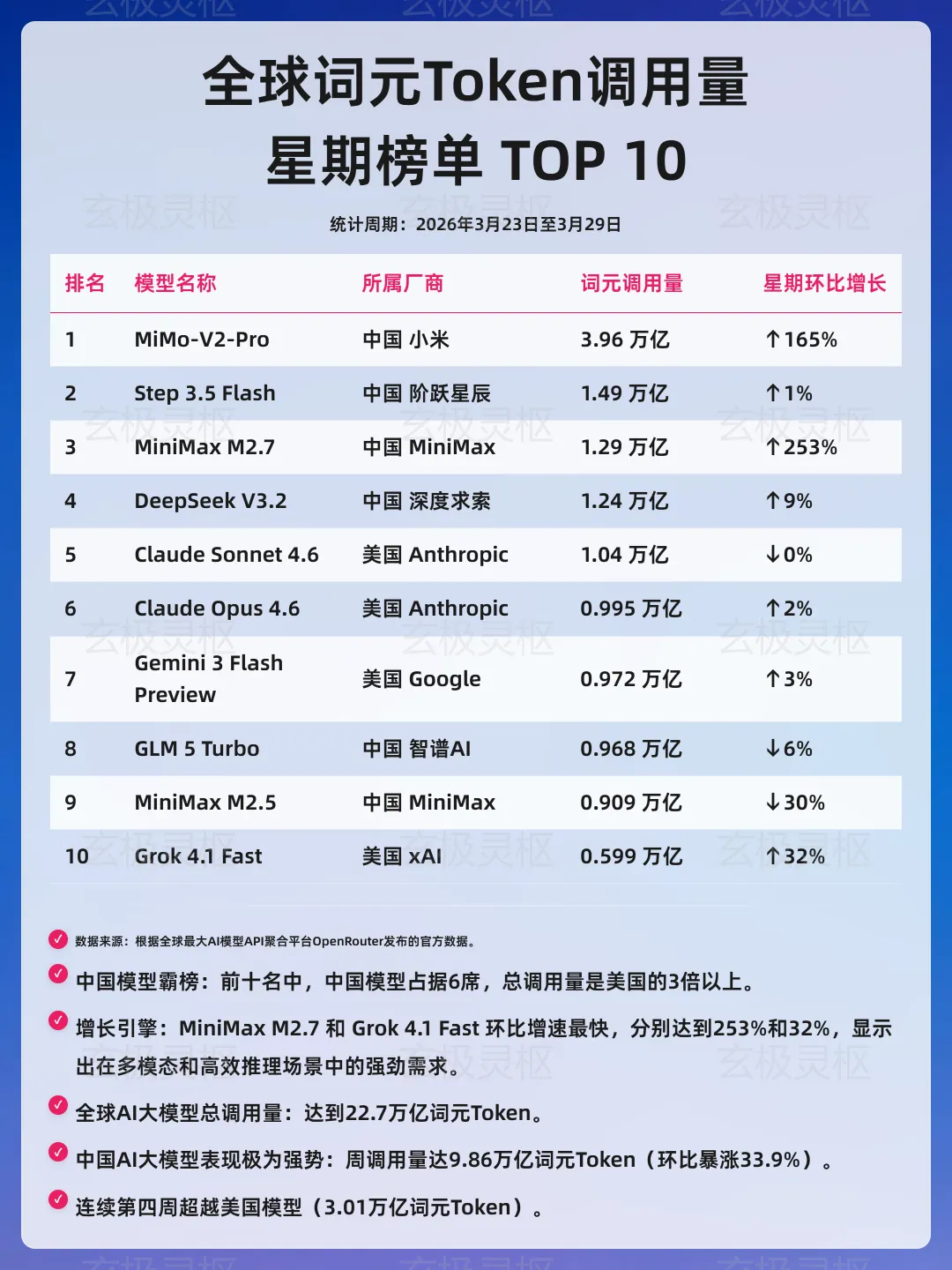
2026 年 3 月最后一周,全球最大 AI 模型 API 聚合平台 OpenRouter 数据再掀波澜:中国大模型周调用量达7.359 万亿 Token,占全球总量 36%,环比暴涨 56.9%,连续三周超越美国(3.536 万亿 Token,环比增 7.35%);全球 Top10 模型中中国独占 6 席,调用量份额超 57%。面对这一里程碑式突破,舆论却陷入割裂:有人归因于 “免费营销”“低价倾销”,有人质疑平台数据 “不能说明一切”,唯独少了对中国 AI 产业突围的正面肯定。我们在算力硬件 “卡脖子” 的前线拼杀,却总被悲观论调拖后腿 —— 中国大模型的领跑,从来不是偶然,而是技术、成本、生态与算力攻坚的必然结果。
1 数据真相:霸榜不是营销泡沫,是全球开发者的 “用脚投票”
1.1 平台数据的权威性与局限性
OpenRouter 作为全球最大 AI 模型 API 聚合平台,汇聚数百万开发者(美国用户占 47.17%,中国仅 6%),其调用量是真实市场需求的直接映射,比实验室基准测试更具产业价值。平台覆盖 400 + 主流模型,支持 OpenAI 兼容接口,是全球开发者测试、部署 AI 应用的核心枢纽,数据具备全球代表性。但需客观看待其局限性:平台侧重推理调用,未覆盖训练算力、企业私有部署等场景;国内用户占比低,中国模型的国内调用量未完全纳入统计,实际产业规模远超平台数据。即便如此,在 “美国开发者主导” 的自由竞争中,中国模型实现反超,足以证明其全球竞争力。
1.2 霸榜核心:免费与低价是手段,不是全部
舆论将中国模型领跑简单归结为 “免费”“便宜”,是对产业逻辑的片面解读。
免费策略:精准破局的市场手段
阶跃星辰 Step 3.5 Flash、DeepSeek 基础版等推出免费调用,本质是降低开发者试用门槛,快速抢占全球开发者心智。2025 年 Q4 中国模型周调用量仅 1.2 万亿 Token(为美国 1/3),不到 5 个月实现反超,免费策略快速激活了全球中小开发者与初创企业需求,是 “从 0 到 1” 的关键破局之举。
低价优势:底层能力的集中体现
中国模型 API 价格仅为美国竞品的1/16 至 1/22:MiniMax M2.5 输出价 1.1 美元 / 百万 Token,Claude Opus 4.6 高达 25 美元;同等代码生成任务,中国模型成本仅 2.6 美元,美国模型需 15 美元。这种优势绝非 “补贴倾销”,而是源于三大硬核支撑:
1.3 技术实力:与国际顶尖模型的代差已缩至 3 个月
价格之外,中国模型的技术追平是霸榜的核心底气。全球调用量前四的小米 MiMo V2 Pro、阶跃星辰 Step 3.5 Flash、MiniMax M2.5、DeepSeek-V3.2,在多模态生成、逻辑推理、超长上下文(最高 128K Token)等核心能力上,已与国际顶尖模型并驾齐驱。行业共识显示,中国模型与 GPT-4、Claude 3.5 的技术代差已缩短至约 3 个月,且在开源生态、场景适配等领域实现反超 —— 中国开源大模型全球下载量占比 17.1%,首次超过美国(15.8%),阿里 Qwen 系列登顶 Hugging Face 下载榜。
2 算力突围:在 “卡脖子” 前线打翻身仗,每一步都来之不易
2.1 算力硬件的困境与攻坚
中国大模型的领跑,是在算力硬件被封锁的背景下实现的 “绝地反击”。长期以来,高端 AI 芯片依赖进口,美国多次升级出口管制,限制英伟达 H100、H200 等芯片对华供应,直接导致国产大模型训练、推理算力缺口扩大。但中国算力产业从未退缩,实现三大突破:
国产芯片量产突围
华为昇腾 950 Pro 量产,单卡算力达国际旗舰 H20 的 2.87 倍,多模态生成速度提升 60%;阿里玄铁 C950 刷新 RISC-V 性能纪录,首次实现 CPU 原生运行千亿参数大模型;
集群规模化部署
中国移动哈尔滨智算中心实现 1.8 万张国产加速卡 “万卡并行训练”,甘肃庆阳十万卡集群覆盖 “训推一体” 全生命周期,国产算力从 “单点攻关” 进入 “体系化应用” 阶段;
软硬件协同优化
浪潮元脑 SD200 超节点让 DeepSeek R1 模型词元生成速度仅 8.9 毫秒,华为昇腾 384 超节点通过液冷、光互联技术,算力密度提升 3 倍、能效比优化 40%,算力利用率稳定在 92%新华网。
2.2 产业共识:中国 AI 正从 “跟跑” 到 “领跑” 的转折
2026 年 3 月,中国日均 Token 调用量突破 140 万亿,较 2024 年初增长超 1000 倍,标志着中国 AI 产业正式从技术验证阶段迈入全球应用引领阶段数字中国建设峰会。这种转折不是单点突破,而是全产业链的协同爆发:从底层算力芯片到上层模型算法,从开源生态到企业场景落地,中国 AI 已形成完整的自主可控体系。医疗 AI 将罕见病确诊时间从数年缩至数小时,工业大模型助力数万家工厂智能化升级,智能驾驶、智慧城市等场景 AI 渗透率超 83%,5 亿人享受 AI 便利 —— 这些真实落地,远比 API 平台数据更能证明中国 AI 的价值。
3 舆论误区:为何总有人 “长他人志气,灭自己威风”?
3.1 三大认知偏差,遮蔽中国 AI 的真实进步
唯 “技术跑分” 论
部分舆论过度迷信实验室基准测试,忽视 “调用量” 这一产业核心指标。但 AI 的价值在于落地,OpenRouter 的调用量是全球开发者对模型实用性、性价比的真实选择,比纸面跑分更具说服力;
“低价即低质” 的偏见
将中国模型的价格优势等同于 “技术落后”,无视能源、架构、规模化带来的底层成本优势。事实上,中国模型在保持低价的同时,性能已追平国际顶尖水平,是 “性价比” 的胜利,而非 “低质” 的妥协;
忽视产业发展规律
中国 AI 起步晚、基础弱,从 “跟跑” 到 “并跑” 再到 “领跑”,是数十年技术积累、政策支持、产业协同的结果。部分人用 “短期营销” 否定长期攻坚,本质是对中国科技产业发展的不了解。
3.2 正面鼓励:是对前线攻坚者的基本尊重
中国大模型团队在算力封锁、技术追赶的双重压力下,日夜攻坚:优化模型架构、适配国产芯片、降低调用成本、拓展全球生态 —— 他们是在 “科技战场” 的前线拼杀。当他们用数据证明中国 AI 的实力时,舆论需要的是客观肯定与理性支持,而非无端质疑与悲观唱衰。正面鼓励,不是盲目自大,而是基于数据与事实的认可,是对中国科技工作者付出的尊重,更是推动产业持续进步的动力。
4 未来趋势:从 API 领跑,到全球 AI 生态主导
4.1 竞争格局:中国模型的优势将持续扩大
摩根大通预测,中国 AI 推理 Token 消耗量将从 2025 年的 10 千万亿增长至 2030 年的 3900 千万亿,五年增长 370 倍。随着国产算力芯片规模化量产、模型技术持续迭代、全球生态不断完善,中国模型的性价比、场景适配优势将进一步凸显,在 OpenRouter 等全球平台的领跑地位将更加稳固。同时,中国模型将从 “API 调用” 延伸至训练算力、企业私有部署、行业解决方案等领域,实现全产业链领跑。
4.2 应对策略:理性看待质疑,坚定自主创新
面对舆论质疑,中国 AI 产业需保持理性与定力:一方面,持续优化模型性能、降低成本、提升稳定性,用更亮眼的产业数据回应质疑;另一方面,加大算力硬件、基础算法的自主研发,突破 “卡脖子” 技术,构建完全自主可控的 AI 生态。同时,加强全球合作与开放,让中国 AI 的技术与服务惠及全球开发者,用实际行动证明中国 AI 的全球价值。
编者话:
中国大模型霸榜全球 API 平台,不是营销的侥幸,不是低价的泡沫,而是中国 AI 产业在算力封锁、技术追赶中实现的历史性突围。从 Token 调用量的反超,到算力硬件的攻坚,再到全产业链的协同爆发,中国 AI 正从 “跟跑者” 变为 “领跑者”。我们不必回避免费、低价的市场策略,更应看到背后的技术实力、成本优势与产业决心。
在科技竞争的前线,每一次突破都来之不易,每一份成绩都值得肯定。少一些无端质疑,多一些正面鼓励;少一些悲观唱衰,多一些理性支持 —— 这不仅是对中国 AI 工作者的尊重,更是对中国科技产业未来的信心。中国 AI 的翻身仗,才刚刚开始,未来值得我们共同期待。




评论