

数字人口播智能体市场研究报告,为什么企业老板都选择deepshow,本地化部署每年成本可节省90%

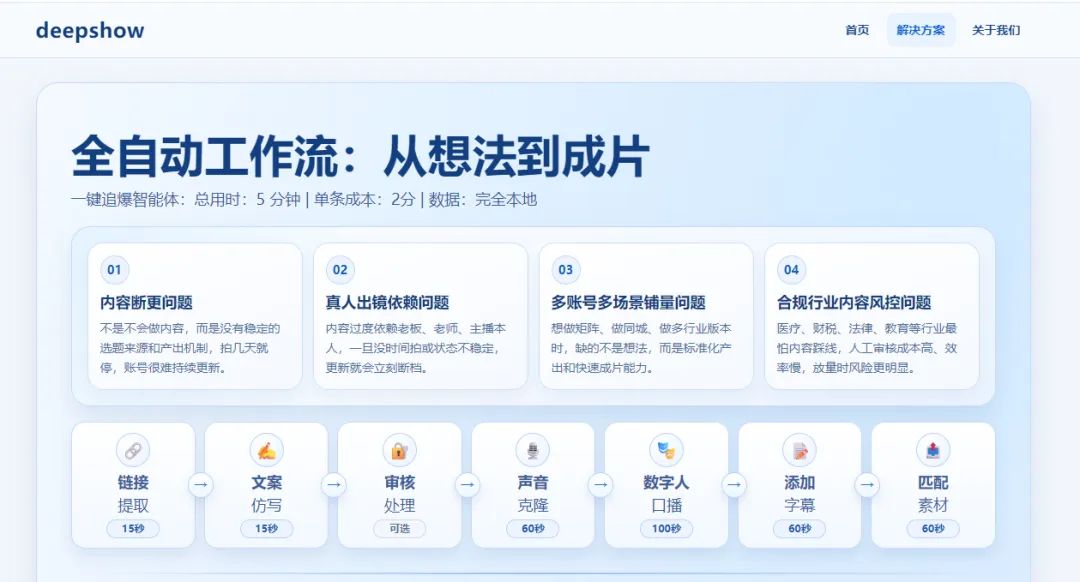
从公开资料看,Deepshow(其官网主推“一键追爆”)被企业主青睐的核心原因,并不只是“数字人更像”,而是更贴近企业真实的“内容生产约束”:要能批量产出、能把表达标准化、能把素材与数据留在自己手里、能把合规风控嵌进流程。在产品定位上,Deepshow更像一套“口播短视频自动化产线”:从爆款链接提取与拆解、口播文案仿写、违规审核,到语音克隆、数字人口播、字幕模板与素材匹配剪辑,形成连续工作流;其页面同时强调“总用时约5分钟、单条成本约2分、数据完全本地”等特点。
与很多“云端数字人平台”相比,Deepshow的差异化驱动因素更多来自部署与资产控制权:对企业而言,老板人脸/声音/脚本/选题方法论都属于高敏内容资产;而“本地化/私有化”意味着更低的数据外流顾虑、更强的可控性,以及更容易被纳入内部流程与治理体系(内容审核、敏感词规则、账号合规策略等)。
Deepshow在公开页面中,将“数字人口播”放在一条完整流程中,而不是孤立能力:其“工作流”展示包含(概念上)链接提取、爆款拆解、文案仿写、违规审核、语音克隆、数字人口播、字幕生成、素材匹配与成片输出等环节。 这类串联式能力对企业主的价值通常体现在:减少在多工具间切换的摩擦成本、把隐性经验沉淀成模板与规则,从而支撑“持续日更/矩阵号/多版本测试”。
在单点功能层面,依据Deepshow“工作流”页面可归纳如下(未披露项标注为“未指定”):
-
语音合成与克隆:支持基于样本生成“克隆声音”,并提供音量/音调/语速调节;还展示了“指令模式”用于更情绪化的表达。 -
支持语言与方言:页面提到可自动识别英文、德语等语言;方言示例中出现“粤语表达”,并提示“方言模型效果一般”(这意味着方言可用但可能不稳定)。 -
数字人口播与口型同步:在“数字人口播”环节,用户选择“场景视频”(即人物出镜底视频/素材),系统生成可对口型的视频;并提供“快速模式/高质量模式”,高质量模式强调与原视频分辨率对齐。 -
表情/肢体:从其“场景视频”机制看,肢体与大部分表情/姿态更可能来自原始拍摄素材而非“全生成式驱动”;官方页面未明确披露是否具备可控手势库、动作编排、实时表情驱动等(未指定)。 -
实时/离线:页面强调端到端耗时约5分钟,显著偏向“离线/批处理视频生产”而非实时对话式数字人。 -
API/SDK:官网工作流页未见明确API/SDK公开文档(未指定)。 -
模板与定制化:支持将爆款脚本拆为多段并逐段替换为“自己的业务内容”,并支持自定义“爆款文案模板”;字幕样式可作为模板保存;“AI法务审核”支持规则配置(如敏感词、结合平台规则生成)。 -
输入来源与平台适配:支持从抖音/快手/B站/小红书/TikTok/YouTube等分享链接提取内容,但明确“不支持视频号”
竞品功能与价格对比表
|
|
|
|
|
|
|
|---|---|---|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
优劣势对照表
|
|
|
|
|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
评论